运用google-protobuf的IM消息应用开发(前端篇)
前言:
公司原本使用了第三方提供的IM消息系统,随着业务发展需要,三方的服务有限,并且出现问题也很难处理和排查,所以这次新版本迭代,我们的server同事呕心沥血做了一个新的IM消息系统,我们也因此配合做了一些事情。 对于前端来说,被告知需要用到protocol buffer,什么gui?最开始我一直没弄懂到底是个什么东西,感觉和平时接触的技术差别比较大。 还有二进制什么的,以前感觉从来就没在前端使用过。 久经波折,这次的旅途学到了很多东西,所以作此博客。
protocol buffer:
简称protobuf,google开源项目,是一种数据交换的格式,google 提供了多种语言的实现:php、JavaScript、java、c#、c++、go 和 python等。 由于它是一种二进制的格式,比使用 xml, json 进行数据交换快许多。以上描述太官方不好理解,通俗点来解释一下,就是通过protobuf定义好数据结构生成一个工具类,这个工具类可以把数据封装成二进制数据来进行传输,在另一端收到二进制数据再用工具类解析成正常的数据。
为什么用protobuf(以下是后端大大“邱桑”的意思):
优:
劣:
使用protobuf:
message Person { required string name = 1; required int32 id = 2; optional string email = 3; }
定义了人的类,有三个描述变量。通过protobuf编译器,把当前配置的类编译成你所需要语言的代码。 比如编译成JavaScript,这个时候会生成一个js文件,我们重命名就叫person.js吧,里面的代码依赖google-protobuf,所以我们要先npm google-protobuf,然后通过webpack或者browserify之类的打包工具把 google-protobuf 引入到当前 person.js 中,最后再引入到我们的工程中。
定义的person,前端要使用的话大致代码如下:
//封装 var person = new proto.protocal.Person(); person.setName('子慕'); person.setId('1'); person.setEmail('xx@xx.com'); var binary = person.serializeBinary(); //解析 var person= new proto.protocal.Person.deserializeBinary(unit8array); var obj = { name: person.getName(); id: person.getId(); email: person.getEmail(); }
前端通过websocket拿到后端下行的arrayBuffer对象,把它转化成unit8array,Person的deserializeBinary方法就能把二进制解析成Person对象,可以通过get+变量命拿到相应值。 serializeBinary方法可以直接把当前的对象转换成二进制数据,用于发送到另一端。
但是,这样就显得非常难以使用了,甚至数据类型很多,结构也都不一样,如果每次收发一个消息都要这样去处理的话,太麻烦了。这里需要进行一层封装处理,方便业务使用,封装后使用大概如下代码:
//我们封装生成的对象假比就叫ImInstance //发送时候直接写一个json,会自动封装 ImInstance.send({ person:{ id: '1', name: '子慕', email: 'xx@xx.com' } }) //接收也会自动,解析 var msg= ImInstance.parse(arrayBuffer);//{person:{name:'x',id:'x',email:'xxx'}}
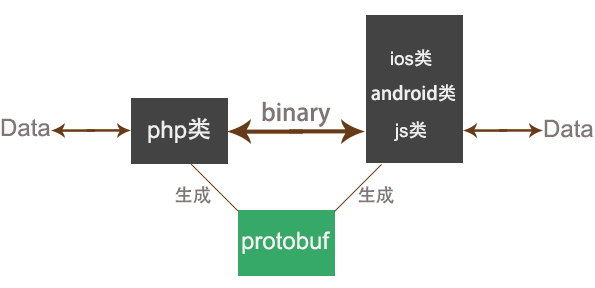
假如我们后端是php,前端是web,protobuf生成一个两个语言的工具类,相互通信都要通过各自的类解析和封装,如下图:

实际是我们会有三个前端:
长连接:
一个消息系统是需要长连接的,前端需要随时接收消息,APP使用了tcp长连接,前端就是websocket了。 websocket也是基于tcp的,相当于在tcp基础上封装了一层。 某种程度来说tcp的性能优于websocket,因为websocket就是在tcp的基础上多了一层转化,但是websocket使用更简单,用tcp的app端需要自己去读tcp流,根据包头和包体组装数据包,而websocket不需要,因为websocket会是一个整包的数据并不是流的形式。 具体来说,后端通过缓存区把数据冲刷(flush)给前端,app端拿到tcp数据流,需要根据消息头给定的消息体长度,去拿取后面多少位的数据,然后组装成一个数据包。 而websocket传输过来就是一个个的包,也就是帧并不是数据流,所以后端在给websocket数据的时候,必须要把一个整包,在缓冲区一次性冲刷过来,而给tcp的话就可以自由冲刷。
(引用)概念上,WebSocket确实只是TCP上面的一层,做下面的工作:
- 为浏览器添加web 的origin-based的安全模型。
- 添加定位和协议命名机制来支持在同一个端口上提供多个服务和同一个IP上有多个主机名。
- 在TCP上实现帧机制,来回到IP包机制,而没有长度限制。
- 在带内包含额外的关闭握手,是为了能在有代理和其他中间设施的地方工作。
ArrayBuffer:
前端也许很少会接触到二进制,至少我没怎么接触过。 之前说的二进制传输,通过设置websocket对象的binaryType属性: binaryType = 'arraybuffer'(如果没有配置默认返回的是个Blob对象,protobuf解析时会报错),消息下行的时候 onmessage 拿到的 MessageEvent.data 会是一个ArrayBuffer对象,如图:
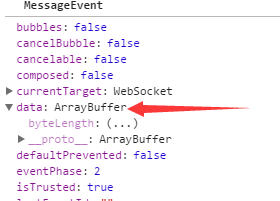
关于ArrayBuffer,MDN解释: ArrayBuffer对象被用来表示一个通用的,固定长度的二进制数据缓冲区。你不能直接操纵ArrayBuffer的内容;相反,你应该创建一个表示特定格式的buffer的类型化数组对象(typed array objects)或数据视图对象DataView 来对buffer的内容进行读取和写入操作。
类型化数组(typed array objects)有下图这些类型:

实际就是一个ArrayBuffer我们是不能直接操作它的,需要转成可以操作的对象类型,我们是需要转换成Unit8Array,比如这样:
var unit8= new Uint8Array(arrayBuffer);
但是我发现在微信里这样用会报错,在手机默认的浏览器里还是好的,看来还存在一定兼容问题。后来用到DataView才没问题的:
var dataview = new DataView(arrayBuffer); var unit8= new Uint8Array(dataview.buffer, dataview.byteOffset, dataview.byteLength);
兼容问题不止这一点,在phone5测试的时候,一直有问题(同事说那台手机被苹果封过,不晓得会不会和这个有关系),一步步查下去,发现是Unit8Array一些方法在phone5里显示undefined,比如 Unit8Array.slice 和 Unit8Array.from,把 Unit8Array.slice用 Unit8Array.subarray 替换,Unit8Array.from 用 new 替换,像这样:Uint8Array.from([1, 0, 0]) == new Uint8Array([1, 0, 0]),目前来说就没出现其他兼容问题了。
websocket和重连机制:
我们会封装一个独立的websocket类,处理websocket的建立、连接、重连、心跳、监听等,提供一些钩子函数,配合前面说的ImInstance实现业务功能。长连接肯定是会出现断开或者弱网等一系类情况,保证业务的健壮和稳定性,需要做心跳重连。这块之前的博客已经写过,这次项目之后又对代码和博客进行了一些完善,具体可以看之前的博客《初探和实现websocket心跳重连》和心跳的github源码《https://github.com/zimv/WebSocketHeartBeat》。
一些踩到的坑汇总:
下面两个问题有一个知识点: Number类型统一按浮点数处理,64位(bit)存储,整数是按最大54位(bit)来算最大最小数的,否则会丧失精度;某些操作(如数组索引还有位操作)是按32位处理的。
1.位移运算:
每一条消息有个唯一id,id是根据时间戳加上一些其他参数再通过位移运算得出的。 本身根据id可以得出时间,所以就没有专门给时间的字段,这里就需要前端对id进行一次运算,得出时间,但是我在做位移操作的时候发现得出的值不对。 后来才查到了上面的知识点。 server给我们的是64位的int,但是js的位移是按照32位处理的,所以得出的值不对,后来邱桑找到了一个Long.js库,它可以把64位整数拆分成两个32位的去计算,最后我就得到了正确的时间。Long.js
2.number丢失精度:
因为js的整数最大只支持到54bit,范围在 −9007199254740992 到 9007199254740992,而我们的id是超过了54bit的(这一点受到了后端同事的疯狂嘲笑)。 在做消息回执(收到一条消息,发送当前消息的id给后端,告知我收到这个消息了)的时候,因为超过了js的最大值,所以前端传出去的id就会是错误的。 比如后端返回了一个id为111111111111111111的值(18个1),前端通过protobuf类解析之后拿到的值直接变成了111111111111111100(16个1加2个0),因为超过了最大值,js用0来占位显示,这样回执给后端的id就是111111111111111100了。 我以为当前存放数字的变量就已经是这个值了,我不管做什么都没用了,那么我希望后端给我一个字符串的id我才好处理(发现这个问题的时候项目正在准备上线),但是邱桑觉得这样多一个字段太浪费。 后来他查了一些资料告诉我,就用Long.js,它可以帮我转换成正确的字符串,我不信,我认为js存不到那么大的数据,js直接把数据给丢失了,而邱桑说值实际还在内存里精度没有丢失,只是js展示不出来,而且非常肯定,我当时不信,在他强烈的要求下,我使用了Long.js的转换方法,结果他是对的。 虽然收到的值超过了js的范围,但是数值仍然是原封不动的在内存里,这个也是被狠狠的打了一下脸,果然还是邱桑厉害! Long.js的代码量还是比较多,当时我想我只用位移就把位移的相关代码抽出来整合了一下,这样比较节约。 后来发现我现在说的这个问题也需要用到Long.js的其它方法,我又尝试抽离,发现要抽的代码太多了,后来干脆就直接把Long.js全部引入进来了(装逼失败)。
ps:由于当时我们的id是18位的number,通过long.js转换是没有问题的。但是后面id到19位以后,所有的结果都不再正确了。js中的number超过安全限制以后,开始变得不安全,有些19位的number可以解析成功,有些不可以,当超过20位以后几乎全部出问题。所以我们的结论是id如果可能特别长,尽量用string。
4.websocket断线重连把自己踢下线的问题:
我们会避免用户重复登录websocket,如果当前用户第二次连接websocket的话 会把上一次登录的一端给踢下线,被踢下线的一端会收到一个消息,当收到踢下线的消息之后我便不会进行重连。 因为网络原因、异常原因或者后端主动要求我重连,我便会去进行重连,但是有时候出现就在同一个地方执行了重复连接,实际都是自己这一个端,那么就会出现登录上之后,又收到踢下去的消息,把自己给踢下去了,踢下去就不会再重连了,这样就永久断开了,这属于逻辑没控制好。 解决这个问题是首先要保证重连之前先主动对当前的websocket执行一次close,close的时候后端是会收到断开的通知,这样我们再去连接就不会重复登录了。
结语:
这次自己碰到很多不熟悉的知识,也问了server同事很多问题,学到很多,有靠谱的大牛同事就是爽! 也出过一些bug和问题,多次反复追溯才查出问题的根源,有时候1个bug可能是几个地方代码写错造成的问题。 第一个版本已经顺利上线,后面还有很多重要的工作要做,单从前端来说,还需要把封装的websocket和ImInstance写得更好,文档,扩展性这些都要考虑(已经是一个公共类了,以后还会作为sdk开放给三方平台);还需要做一个监控展示,帮助实时监控服务器CPU,带宽,性能等。 经历了一次大版本的迭代,加了一个月的班,熬了几天夜,和团队一起在进步,收获到这么多经验包也是很开心的。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号