

numpy、scipy、pandas、matplotlib的读书报告
Numpy: 基础的数学计算模块,以矩阵为主,纯数学。
SciPy: 基于Numpy,提供方法(函数库)直接计算结果,封装了一些高阶抽象和物理模型。比方说做个傅立叶变换,这是纯数学的,用Numpy;做个滤波器,这属于信号处理模型了,在Scipy里找。
Pandas: 提供了一套名为DataFrame的数据结构,适合统计分析中的表结构,在上层做数据分析。
Numpy:
来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多,本身是由C语言开发。这个是很基础的扩展,其余的扩展都是以此为基础。数据结构为ndarray,一般有三种方式来创建。
Pandas:
基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。最具有统计意味的工具包,某些方面优于R软件。数据结构有一维的Series,二维的DataFrame(类似于Excel或者SQL中的表,如果深入学习,会发现Pandas和SQL相似的地方很多,例如merge函数),三维的Panel(Pan(el) + da(ta) + s,知道名字的由来了吧)。
1.汇总和计算描述统计,处理缺失数据 ,层次化索引
2.清理、转换、合并、重塑、GroupBy技术
3.日期和时间数据类型及工具(日期处理方便地飞起)
Matplotlib:
Python中最著名的绘图系统,很多其他的绘图例如seaborn(针对pandas绘图而来)也是由其封装而成。
绘制的图形可以大致按照ggplot的颜色显示,但是还是感觉很鸡肋。但是matplotlib的复杂给其带来了很强的定制性。其具有面向对象的方式及Pyplot的经典高层封装。
需要掌握的是:
1.散点图,折线图,条形图,直方图,饼状图,箱形图的绘制。
2.绘图的三大系统:pyplot,pylab(不推荐),面向对象
3.坐标轴的调整,添加文字注释,区域填充,及特殊图形patches的使用
4.金融的同学注意的是:可以直接调用Yahoo财经数据绘图
Scipy:
方便、易于使用、专为科学和工程设计的Python工具包.它包括统计,优化,整合,线性代数模块,傅里叶变换,信号和图像处理,常微分方程求解器等等。基本可以代替Matlab,但是使用的话和数据处理的关系不大,数学系,或者工程系相对用的多一些。
近期发现有个statsmodel可以补充scipy.stats,时间序列支持完美。
一。 数组要比列表效率高很多
numpy高效的处理数据,提供数组的支持,python默认没有数组。pandas、scipy、matplotlib都依赖numpy。
pandas主要用于数据挖掘,探索,分析
matplotlib用于作图,可视化
scipy进行数值计算,如:积分,傅里叶变换,微积分
statsmodels用于统计分析
Gensim用于文本挖掘
sklearn机器学习, keras深度学习
二。
numpy和mkl 下载安装
pandas和maiplotlib网络安装
scipy 下载安装
statsmodels和Gensim网络安装
三numpy的操作。
import numpy
# 创建数一维数组组
# numpy.array([元素1,元素2,......元素n])
x = numpy.array(['a', '9', '8', '1'])
# 创建二维数组格式
# numpy.array([[元素1,元素2,......元素n],[元素1,元素2,......元素n],[元素1,元素2,......元素n]])
y = numpy.array([[3,5,7],[9,2,6],[5,3,0]])
# 排序
x.sort()
y.sort()
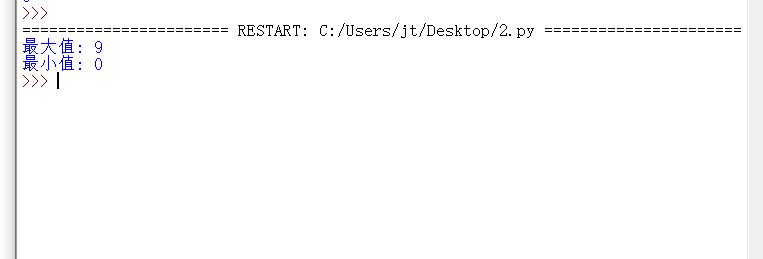
# 取最大值
y1 = y.max()
# 取最小值
y2 = y.main()
# 切片
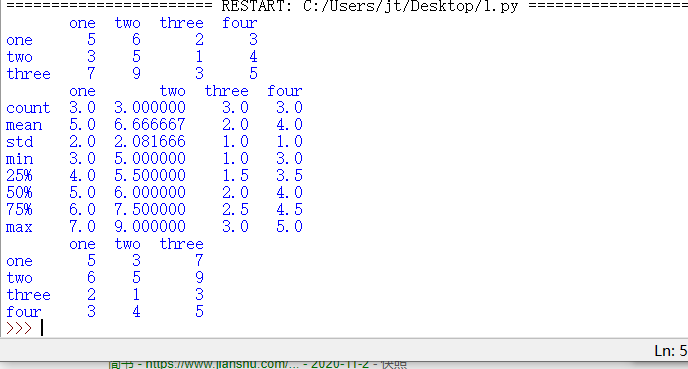
四pandas的操作。 import pandas as pda # 使用pandas生成数据 # Series代表某一串数据 index指定行索引名称,Series索引默认从零开始 # DataFrame代表行列整合出来的数据框,columns 指定列名 a = pda.Series([8, 9, 2, 1], index=['one', 'two', 'three', 'four']) # 以列表的格式创建数据框 b = pda.DataFrame([[5,6,2,3],[3,5,1,4],[7,9,3,5]], columns=['one', 'two', 'three', 'four'],index=['one', 'two', 'three']) # 以字典的格式创建数据框 c = pda.DataFrame({ 'one':4, # 会自动补全 'two':[6,2,3], 'three':list(str(982)) }) # b.head(行数)# 默认取前5行头 # b.tail(行数)# 默认取后5行尾 # b.describe() 统计数据的情况 count mean std min 25% max e = b.head() f = b.describe() # 数据的转置,及行变成列,列变成行 g = b.T
print(e)
print(f)
print(g)
五python数据的导入
import pandas as pad
f = open('d:/大.csv','rb')
# 导入csv
a = pad.read_csv(f, encoding='python')
# 显示多少行多少列
a.shape()
a.values[0][2] #第一行第三列
# 描述csv数据
b = a.describe()
# 排序
c = a.sort_values()
# 导入excel
d = pad.read_excel('d:/大.xls')
print(d)
print(d.describe())
# 导入mysql
import pymysql
conn = pymysql.connect(host='localhost', user='root', passwd='root', db='')
sql = 'select * from mydb'
e = pad.read_sql(sql, conn)
# 导入html表格数据 需要先安装 html5lib和bs4
g = pad.read_html('https://book.douban.com/subject/30258976/?icn=index-editionrecommend')
# 导入文本数据
h = pad.read_table('d:/lianjie.txt','rb', engine='python')
print(h.describe())
六matplotlib的使用
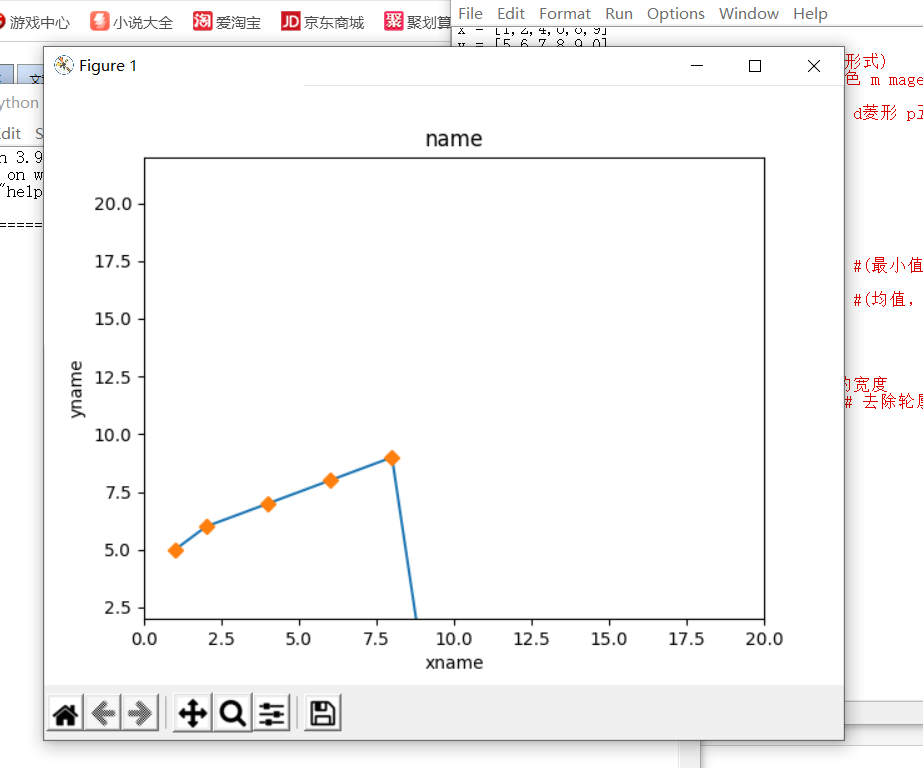
# 折线图/散点图用plot
# 直方图用hist
import matplotlib.pylab as pyl
import numpy as npy
x = [1,2,4,6,8,9]
y = [5,6,7,8,9,0]
pyl.plot(x, y) #plot(x轴数据,y轴数据,展现形式)
# o散点图,默认是直线 c cyan青色 r red红色 m magente品红色 g green绿色 b blue蓝色 y yellow黄色 w white白色
# -直线 --虚线 -. -.形式 :细小虚线
# s方形 h六角形 *星星 + 加号 x x形式 d菱形 p五角星
pyl.plot(x, y, 'D')
pyl.title('name') #名称
pyl.xlabel('xname') #x轴名称
pyl.ylabel('yname') #y轴名称
pyl.xlim(0,20) #设置x轴的范围
pyl.ylim(2,22) #设置y轴的范围
pyl.show()
# 随机数的生成
data = npy.random.random_integers(1,20,100) #(最小值,最大值,个数)
# 生成具有正态分布的随机数
data2 = npy.random.normal(10.0, 1.0, 10000) #(均值,西格玛,个数)
# 直方图hist
pyl.hist(data)
pyl.hist(data2)
# 设置直方图的上限下限
sty = npy.arange(2,20,2) #步长也表示直方图的宽度
pyl.hist(data, sty, histtype='stepfilled') # 去除轮廓
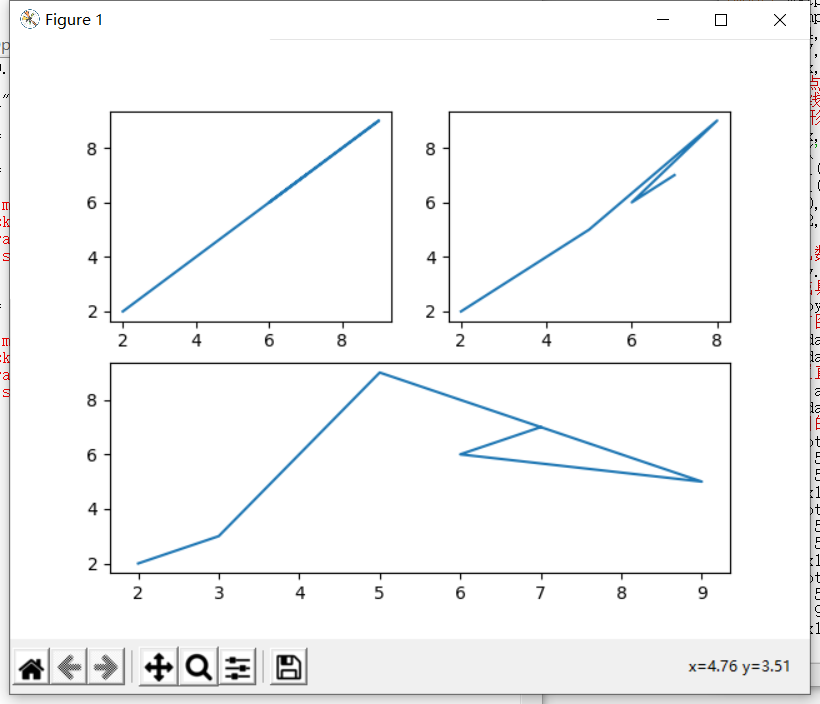
# 子图的绘制和使用
pyl.subplot(2, 2, 2) # (行,列,当前区域)
x1 = [2,3,5,8,6,7]
y1 = [2,3,5,9,6,7]
pyl.plot(x1, y1)
pyl.subplot(2, 2, 1) # (行,列,当前区域)
x1 = [2,3,5,9,6,7]
y1 = [2,3,5,9,6,7]
pyl.plot(x1, y1)
pyl.subplot(2, 1, 2) # (行,列,当前区域)
x1 = [2,3,5,9,6,7]
y1 = [2,3,9,5,6,7]
pyl.plot(x1, y1)
pyl.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号