
一次电话Java面试的问题总结(JDK8新特性、哈希冲突、HashMap原理、线程安全、Linux查询命令、Hadoop节点)
面试涉及问题含有:
Java
JDK8新特性
集合(哈希冲突、HashMap的原理、自动排序的集合TreeSet)
多线程安全问题
String和StringBuffer
JVM
原理、运行流程、内部结构
Linux
查询含有某字符串内容的命令grep
查询进程、GC状态、杀死进程
Hadoop五种节点介绍
--------------------------------------------------------------------------------------------------------
JAVA:
1、JDK8新特性:
- 函数接口Functional Interface
只包含一个抽象方法的接口,也成为SAM(Single Abstract Method单方法接口)类型的接口。
例如Runnable接口的run()方法。JDK8新增了许多函数接口,其中一个重要的原因就是支持Lambda表达式。
-
Lambda(拉姆达) 表达式(闭包) − Lambda允许把函数作为一个方法的参数,函数作为参数传递进方法中。
一种匿名方法,可以将函数接口中的函数作为方法参数处理。在Java中Lambda表达式返回值是一个对象,这个对象必须是单方法接口。
lambda表达式的重要特征:
可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
Lambda的设计可以实现简洁而紧凑的语言结构。最简单的Lambda表达式可由逗号分隔的参数列表、->符号和语句块组成,例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> System.out.println( e ) ); Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.println( e ) ); Arrays.asList( "a", "b", "d" ).forEach( e -> { System.out.print( e ); System.out.print( e ); } ); String separator = ","; Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.print( e + separator ) ); Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> e1.compareTo( e2 ) ); 等同于 Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> { int result = e1.compareTo( e2 ); return result; } );
-
方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
Lambda表达式的一种特殊形式。当一个lambda表达式body中仅仅是调用某个方法,此时使用方法引用替代Lambda表达式。从形式上直接引用这个方法,比在lambda表达式body中引用在形式上更简洁。
方法引用通过方法的名字来指向一个方法。
方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
方法引用使用一对冒号 :: 。
Java 8使用两个新概念扩展了接口的含义:默认方法和静态方法。默认方法使得接口有点类似traits,不过要实现的目标不一样。默认方法使得开发者可以在 不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的类也同时实现这个新加的方法。 默认方法和抽象方法之间的区别在于抽象方法需要实现,而默认方法不需要。接口提供的默认方法会被接口的实现类继承或者覆写,例子代码如下: private interface Defaulable { default String notRequired() { return "Default implementation"; } } private static class DefaultableImpl implements Defaulable { } private static class OverridableImpl implements Defaulable { @Override public String notRequired() { return "Overridden implementation"; } } Defaulable接口使用关键字default定义了一个默认方法notRequired()。DefaultableImpl类实现了这个接口,同时默认继承了这个接口中的默认方法;OverridableImpl类也实现了这个接口,但覆写了该接口的默认方法,并提供了一个不同的实现。 Java 8带来的另一个有趣的特性是在接口中可以定义静态方法,例子代码如下: private interface DefaulableFactory { // Interfaces now allow static methods static Defaulable create( Supplier< Defaulable > supplier ) { return supplier.get(); } } 下面的代码片段整合了默认方法和静态方法的使用场景: public static void main( String[] args ) { Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new ); System.out.println( defaulable.notRequired() ); defaulable = DefaulableFactory.create( OverridableImpl::new ); System.out.println( defaulable.notRequired() ); } 输出结果如下: Default implementation Overridden implementation
-
默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
主要目的是为了升级标准JDK接口,另外也是为了能在JDK8中顺畅的使用Lamb的表达式。
private interface DefaulableFactory { // Interfaces now allow static methods static Defaulable create( Supplier< Defaulable > supplier ) { return supplier.get(); } }
-
新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
- java批量数据操作bulk dataoperations
目的是应用lambda函数来实现包含并行操作在内的多种数据处理功能,而支持并行数据操作是其关键内容。这个并行操作实在java7的java.util.concurrency的Fork/Join机制上实现的。
-
Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
-
Date Time API − 加强对日期与时间的处理。
-
Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
-
Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
- 重复注解:
自从Java 5中引入注解以来,这个特性开始变得非常流行,并在各个框架和项目中被广泛使用。不过,注解有一个很大的限制是:在同一个地方不能多次使用同一个注解。Java 8打破了这个限制,引入了重复注解的概念,允许在同一个地方多次使用同一个注解。
在Java 8中使用@Repeatable注解定义重复注解,实际上,这并不是语言层面的改进,而是编译器做的一个trick,底层的技术仍然相同。可以利用下面的代码说明:
-
package com.javacodegeeks.java8.repeatable.annotations; import java.lang.annotation.ElementType; import java.lang.annotation.Repeatable; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; public class RepeatingAnnotations { @Target( ElementType.TYPE ) @Retention( RetentionPolicy.RUNTIME ) public @interface Filters { Filter[] value(); } @Target( ElementType.TYPE ) @Retention( RetentionPolicy.RUNTIME ) @Repeatable( Filters.class ) public @interface Filter { String value(); }; @Filter( "filter1" ) @Filter( "filter2" ) public interface Filterable { } public static void main(String[] args) { for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) { System.out.println( filter.value() ); } } }
正如我们所见,这里的Filter类使用@Repeatable(Filters.class)注解修饰,而Filters是存放Filter注解的容器,编译器尽量对开发者屏蔽这些细节。这样,Filterable接口可以用两个Filter注解注释(这里并没有提到任何关于Filters的信息)。
另外,反射API提供了一个新的方法:getAnnotationsByType(),可以返回某个类型的重复注解,例如
Filterable.class.getAnnoation(Filters.class)将返回两个Filter实例,输出到控制台的内容如下所示: filter1 filter2
2、集合:
哈希冲突:
(见博客:https://www.cnblogs.com/wuchaodzxx/p/7396599.html)
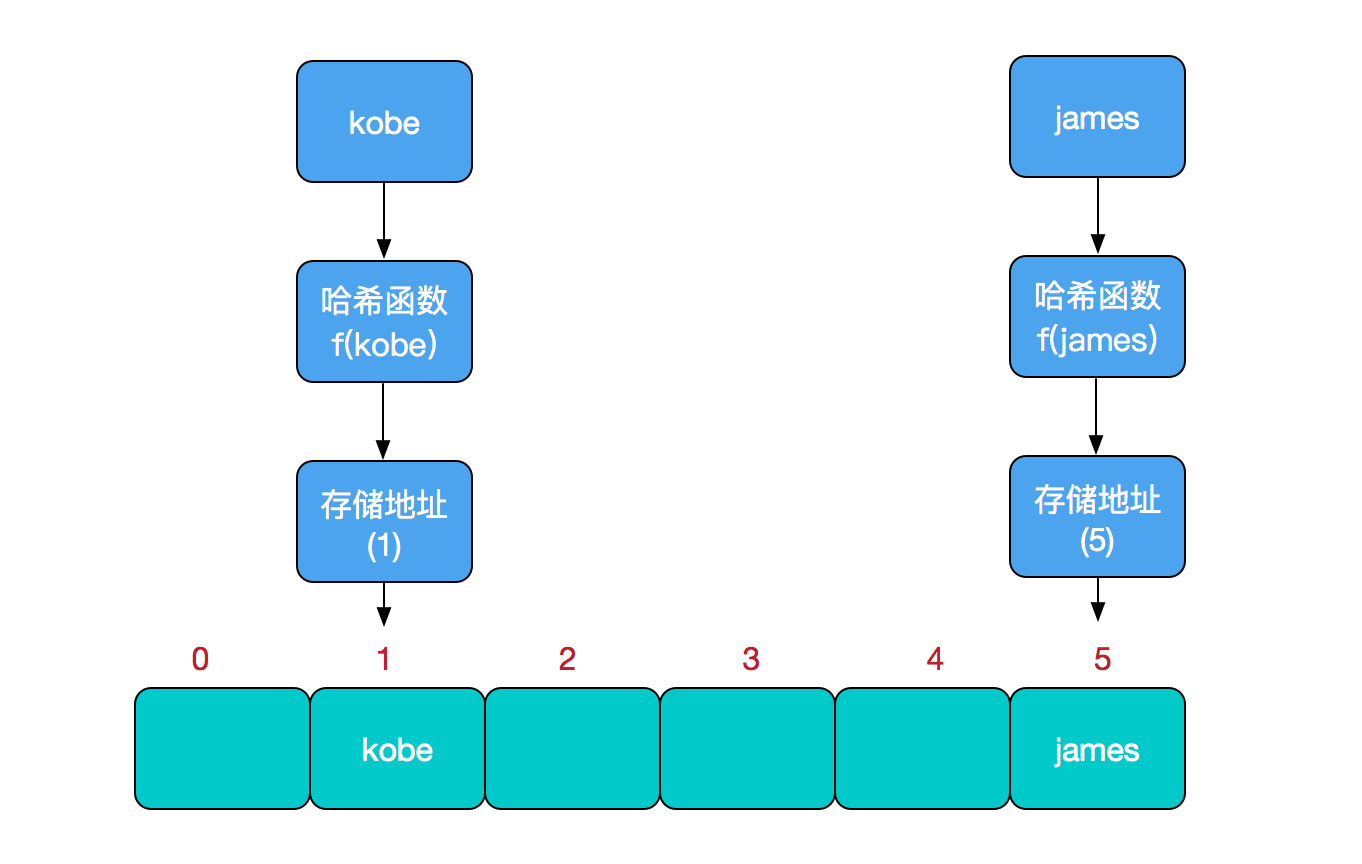
如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
(1)开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:
线性探测再散列
dii=1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
二次探测再散列
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
伪随机探测再散列
di=伪随机数序列。
(2)再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
(3)链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
(4)建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
HashMap的底层原理:
见博客:https://www.cnblogs.com/chengxiao/p/6059914.html
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
//HashMap的主干数组,可以看到就是一个Entry数组,初始值为空数组{},主干数组的长度一定是2的次幂,至于为什么这么做,后面会有详细分析。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry是HashMap中的一个静态内部类。代码如下:

static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
自动排序的集合:
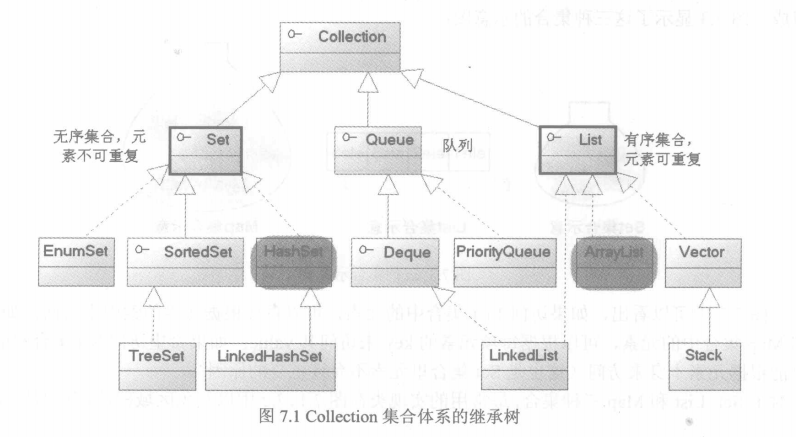
TreeSet(树集)是一个有序集合,可以按照任何顺序将元素插入该集合,当对该集合进行迭代时,各个值将自动以排序后的顺序出现。TreeSet中的元素按照升序排列,缺省是按照自然顺序进行排序,意味着TreeSet中的元素要实现Comparable接口,或者有一个自定义的比较器Comparator。
TreeSet底层使用的是TreeMap,TreeMap的底层实现是红黑树(详细见http://www.cnblogs.com/xujian2014/p/4645943.html)。
public TreeSet()
{
this(new TreeMap<E,Object>());
}
使用示例:
public class Test
{
public static void main(String[] args)
{
TreeSet<String> treeSet=new TreeSet<>();
treeSet.add("Bili");
treeSet.add("Amy");
treeSet.add("cDy");
for (String string : treeSet)
{
System.out.println(string);
}
}
由于String类实现了Comparable接口,它的compareTo方法是按照字典顺序来对字符串进行排序,所以结果如下:

注意:
1、TreeSet的排列顺序必须是全局顺序,也就是说任何两个元素都是必须可比的,同时只有当他们比较相同时才返回0。
2、如果树集包含了n个元素,那么平均需要进行log2n次比较,才能找到新元素的正确位置。
3、线程:
多线程安全运行:
在多个线程并发执行访问同一个数据时,如果不采取相应的措施,将会是非常危险的。为避免这种情况发生,我们要将多个线程对同一数据的访问同步,确保线程安全。
所谓同步(synchronization)就是指一个线程访问数据时,其它线程不得对同一个数据进行访问,即同一时刻只能有一个线程访问该数据,当这一线程访问结束时其它线程才能对这它进行访问。同步最常见的方式就是使用锁(Lock),也称为线程锁。锁是一种非强制机制,每一个线程在访问数据或资源之前,首先试图获取(Acquire)锁,并在访问结束之后释放(Release)锁。在锁被占用时试图获取锁,线程会进入等待状态,直到锁被释放再次变为可用。
Java里面一般用以下几种机制保证线程安全:
1.互斥同步锁(悲观锁)
1)Synchorized
2)ReentrantLock
互斥同步锁也叫做阻塞同步锁,特征是会对没有获取锁的线程进行阻塞。
要理解互斥同步锁,首选要明白什么是互斥什么是同步。简单的说互斥就是非你即我,同步就是顺序访问。互斥同步锁就是以互斥的手段达到顺序访问的目的。操作系统提供了很多互斥机制比如信号量,互斥量,临界区资源等来控制在某一个时刻只能有一个或者一组线程访问同一个资源。
Java里面的互斥同步锁就是Synchorized和ReentrantLock,前者是由语言级别实现的互斥同步锁,理解和写法简单但是机制笨拙,在JDK6之后性能优化大幅提升,即使在竞争激烈的情况下也能保持一个和ReentrantLock相差不多的性能,所以JDK6之后的程序选择不应该再因为性能问题而放弃synchorized。ReentrantLock是API层面的互斥同步锁,需要程序自己打开并在finally中关闭锁,和synchorized相比更加的灵活,体现在三个方面:等待可中断,公平锁以及绑定多个条件。但是如果程序猿对ReentrantLock理解不够深刻,或者忘记释放lock,那么不仅不会提升性能反而会带来额外的问题。另外synchorized是JVM实现的,可以通过监控工具来监控锁的状态,遇到异常JVM会自动释放掉锁。而ReentrantLock必须由程序主动的释放锁。
互斥同步锁都是可重入锁,好处是可以保证不会死锁。但是因为涉及到核心态和用户态的切换,因此比较消耗性能。JVM开发团队在JDK5-JDK6升级过程中采用了很多锁优化机制来优化同步无竞争情况下锁的性能。比如:自旋锁和适应性自旋锁,轻量级锁,偏向锁,锁粗化和锁消除。
2.非阻塞同步锁
1) 原子类(CAS)
非阻塞同步锁也叫乐观锁,相比悲观锁来说,它会先进行资源在工作内存中的更新,然后根据与主存中旧值的对比来确定在此期间是否有其他线程对共享资源进行了更新,如果旧值与期望值相同,就认为没有更新,可以把新值写回内存,否则就一直重试直到成功。它的实现方式依赖于处理器的机器指令:CAS(Compare And Swap)
JUC中提供了几个Automic类以及每个类上的原子操作就是乐观锁机制。
不激烈情况下,性能比synchronized略逊,而激烈的时候,也能维持常态。激烈的时候,Atomic的性能会优于ReentrantLock一倍左右。但是其有一个缺点,就是只能同步一个值,一段代码中只能出现一个Atomic的变量,多于一个同步无效。因为他不能在多个Atomic之间同步。
非阻塞锁是不可重入的,否则会造成死锁。
3.无同步方案
1)可重入代码
在执行的任何时刻都可以中断-重入执行而不会产生冲突。特点就是不会依赖堆上的共享资源
2)ThreadLocal/Volaitile
线程本地的变量,每个线程获取一份共享变量的拷贝,单独进行处理。
3) 线程本地存储
如果一个共享资源一定要被多线程共享,可以尽量让一个线程完成所有的处理操作,比如生产者消费者模式中,一般会让一个消费者完成对队列上资源的消费。典型的应用是基于请求-应答模式的web服务器的设计
4、String和StringBuffer
(1)String:是对象不是原始类型.为不可变对象,一旦被创建,就不能修改它的值.对于已经存在的String对象的修改都是重新创建一个新的对象,然后把新的值保存进去.String 是final类,即不能被继承
String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且大量浪费有限的内存空间。
String a = "a"; //假设a指向地址0x0001
a = "b";//重新赋值后a指向地址0x0002,但0x0001地址中保存的"a"依旧存在,但已经不再是a所指向的,a 已经指向了其它地址。
因此String的操作都是改变赋值地址而不是改变值操作。
(2)StringBuffer:是一个可变对象,当对他进行修改的时候不会像String那样重新建立对象。它只能通过构造函数来建立对象被建立以后,在内存中就会分配内存空间,并初始保存一个null.向StringBuffer中赋值的时候可以通过它的append方法.
StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。 每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量。
StringBuffer buf=new StringBuffer(); //分配长16字节的字符缓冲区
StringBuffer buf=new StringBuffer(512); //分配长512字节的字符缓冲区
StringBuffer buf=new StringBuffer("this is a test")//在缓冲区中存放了字符串,并在后面预留了16字节的空缓冲区。
💗StringBuffer类中的方法要偏重于对字符串的变化例如追加、插入和删除等,这个也是StringBuffer和String类的主要区别。
1、append方法
public StringBuffer append(boolean b)
该方法的作用是追加内容到当前StringBuffer对象的末尾,类似于字符串的连接。调用该方法以后,StringBuffer对象的内容也发生改变
2、deleteCharAt方法
public StringBuffer deleteCharAt(int index)
该方法的作用是删除指定位置的字符,然后将剩余的内容形成新的字符串。例如:
StringBuffer sb = new StringBuffer(“Test”);
sb. deleteCharAt(1);
该代码的作用删除字符串对象sb中索引值为1的字符,也就是删除第二个字符,剩余的内容组成一个新的字符串。所以对象sb的值变为”Tst”。
还存在一个功能类似的delete方法:
public StringBuffer delete(int start,int end)
该方法的作用是删除指定区间以内的所有字符,包含start,不包含end索引值的区间。例如:
StringBuffer sb = new StringBuffer(“TestString”);
sb. delete (1,4);
该代码的作用是删除索引值1(包括)到索引值4(不包括)之间的所有字符,剩余的字符形成新的字符串。则对象sb的值是”TString”。
3、insert方法
public StringBuffer insert(int offset, String s)
该方法的作用是在StringBuffer对象中插入内容,然后形成新的字符串。例如:
StringBuffer sb = new StringBuffer(“TestString”);
sb.insert(4,“false”);
该示例代码的作用是在对象sb的索引值4的位置插入字符串false,形成新的字符串,则执行以后对象sb的值是”TestfalseString”。
4、reverse方法
public StringBuffer reverse()
该方法的作用是将StringBuffer对象中的内容反转,然后形成新的字符串。例如:
StringBuffer sb = new StringBuffer(“abc”);
sb.reverse();
经过反转以后,对象sb中的内容将变为”cba”。
5、setCharAt方法
public void setCharAt(int index, char ch)
该方法的作用是修改对象中索引值为index位置的字符为新的字符ch。例如:
StringBuffer sb = new StringBuffer(“abc”);
sb.setCharAt(1,’D’);
则对象sb的值将变成”aDc”。
6、trimToSize方法
public void trimToSize()
该方法的作用是将StringBuffer对象的中存储空间缩小到和字符串长度一样的长度,减少空间的浪费。
7、构造方法:
StringBuffer s0=new StringBuffer();分配了长16字节的字符缓冲区
StringBuffer s1=new StringBuffer(512);分配了512字节的字符缓冲区
8、获取字符串的长度: length()
StringBuffer s = new StringBuffer("www");
int i=s.length();
m.返回字符串的一部分值
substring(int start) //返回从start下标开始以后的字符串
substring(int start,int end) //返回从start到 end-1字符串
9.替换字符串
replace(int start,int end,String str)
s.replace(0,1,"qqq");
10.转换为不变字符串:toString()。
StringBuffer和StringBuilder类功能基本相似,主要区别在于StringBuffer类的方法是多线程、安全的,而 StringBuilder不是线程安全的,相比而言,StringBuilder类会略微快一点。对于经常要改变值的字符串应该使用 StringBuffer和StringBuilder类。
线程安全
StringBuffer 线程安全
StringBuilder 线程不安全
速度
一般情况下,速度从快到慢:StringBuilder>StringBuffer>String,这种比较是相对的,不是绝对的。
总结
(1)如果要操作少量的数据用 = String
(2)单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
(3)多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
JVM:
1、运行流程
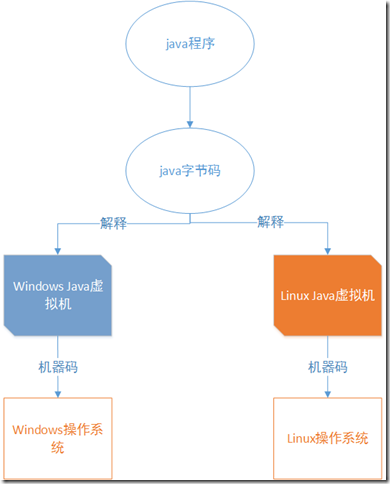
java程序经过一次编译之后,将java代码编译为字节码也就是class文件,然后在不同的操作系统上依靠不同的java虚拟机进行解释,最后再转换为不同平台的机器码,最终得到执行。这样我们是不是可以推演,如果要在mac系统上运行,是不是只需要安装mac java虚拟机就行了。那么了解了这个基本原理后,我们尝试去做更深的研究,一个普通的java程序它的执行流程到底是怎样的呢?例如我们写了一段这样的代码:
public class HelloWorld { public static void main(String[] args) { System.out.print("Hello world"); } }
这段程序从编译到运行,最终打印出“Hello world”中间经过了哪些步骤呢?我们直接上图:

2、内部结构
class文件被jvm装载以后,经过jvm的内存空间调配,最终是由执行引擎完成class文件的执行。当然这个过程还有其他角色模块的协助,这些模块协同配合才能让一个java程序成功的运行

3、JVM内存空间包含:方法区、java堆、java栈、本地方法栈。
方法区是各个线程共享的区域,存放类信息、常量、静态变量。
java堆也是线程共享的区域,我们的类的实例就放在这个区域,可以想象你的一个系统会产生很多实例,因此java堆的空间也是最大的。如果java堆空间不足了,程序会抛出OutOfMemoryError异常。
java栈是每个线程私有的区域,它的生命周期与线程相同,一个线程对应一个java栈,每执行一个方法就会往栈中压入一个元素,这个元素叫“栈帧”,而栈帧中包括了方法中的局部变量、用于存放中间状态值的操作栈,这里面有很多细节,我们以后再讲。如果java栈空间不足了,程序会抛出StackOverflowError异常,想一想什么情况下会容易产生这个错误,对,递归,递归如果深度很深,就会执行大量的方法,方法越多java栈的占用空间越大。
本地方法栈角色和java栈类似,只不过它是用来表示执行本地方法的,本地方法栈存放的方法调用本地方法接口,最终调用本地方法库,实现与操作系统、硬件交互的目的。
PC寄存器,说到这里我们的类已经加载了,实例对象、方法、静态变量都去了自己该去的地方,那么问题来了,程序该怎么执行,哪个方法先执行,哪个方法后执行,这些指令执行的顺序就是PC寄存器在管,它的作用就是控制程序指令的执行顺序。
执行引擎当然就是根据PC寄存器调配的指令顺序,依次执行程序指令。
LINUX:
1、查找文件内容命令:
在使用linux时,经常需要进行文件查找。其中查找的命令主要有find和grep。两个命令是有区的。
区别:(1)find命令是根据文件的属性进行查找,如文件名,文件大小,所有者,所属组,是否为空,访问时间,修改时间等。
(2)grep是根据文件的内容进行查找,会对文件的每一行按照给定的模式(patter)进行匹配查找。
一.find命令
基本格式:find path expression
1.按照文件名查找
(1)find / -name httpd.conf #在根目录下查找文件httpd.conf,表示在整个硬盘查找
(2)find /etc -name httpd.conf #在/etc目录下文件httpd.conf
(3)find /etc -name '*srm*' #使用通配符*(0或者任意多个)。表示在/etc目录下查找文件名中含有字符串‘srm’的文件
(4)find . -name 'srm*' #表示当前目录下查找文件名开头是字符串‘srm’的文件
2.按照文件特征查找
(1)find / -amin -10 # 查找在系统中最后10分钟访问的文件(access time)
(2)find / -atime -2 # 查找在系统中最后48小时访问的文件
(3)find / -empty # 查找在系统中为空的文件或者文件夹
(4)find / -group cat # 查找在系统中属于 group为cat的文件
(5)find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件(modify time)
(6)find / -mtime -1 #查找在系统中最后24小时里修改过的文件
(7)find / -user fred #查找在系统中属于fred这个用户的文件
(8)find / -size +10000c #查找出大于10000000字节的文件(c:字节,w:双字,k:KB,M:MB,G:GB)
(9)find / -size -1000k #查找出小于1000KB的文件
3.使用混合查找方式查找文件
参数有: !,-and(-a),-or(-o)。
(1)find /tmp -size +10000c -and -mtime +2 #在/tmp目录下查找大于10000字节并在最后2分钟内修改的文件
(2)find / -user fred -or -user george #在/目录下查找用户是fred或者george的文件文件
(3)find /tmp ! -user panda #在/tmp目录中查找所有不属于panda用户的文件
二、grep命令
基本格式:find expression
命令:grep
格式:grep [option] pattern filenames
功能:逐行搜索所指定的文件或标准输入,并显示匹配模式的每一行。
选项:-i 匹配时忽略大小写
-v 找出模式失配的行
例如:% grep -i 'java*' ./test/run.sh
1.主要参数
[options]主要参数:
-c:只输出匹配行的计数。
-i:不区分大小写
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达 式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
.:所有的单个字符。
* :有字符,长度可以为0。
2.实例
(1)grep 'test' d* #显示所有以d开头的文件中包含 test的行
(2)grep ‘test’ aa bb cc #显示在aa,bb,cc文件中包含test的行
(3)grep ‘[a-z]\{5\}’ aa #显示所有包含每行字符串至少有5个连续小写字符的字符串的行
(4)grep magic /usr/src #显示/usr/src目录下的文件(不含子目录)包含magic的行
(5)grep -r magic /usr/src #显示/usr/src目录下的文件(包含子目录)包含magic的行
(6)grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
2、GC状态命令
ps命令查找与进程相关的PID号:
ps a 显示现行终端机下的所有程序,包括其他用户的程序。
ps -A 显示所有程序。
使用kill命令结束进程:kill xxx
常用:kill -9 324
大数据:
HDFS节点、角色
1.Namenode名称节点
目录的管理者,每一个集群都有一个,记录实时的数据变化,如果没有namenode,HDFS就无法工作,系统中的文件将会全部丢失,就无法将位于不同datanode上的文件快(blocks)重建文件。因此它的容错机制很有必要。
它主要负责:
- 接收用户的请求;
- 维护文件系统的目录结构;
- 管理文件与Block之间的练习;
2.Datanode数据节点
是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索,并且定期向namenode发送他们所存储的块(block)的列表。
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
它主要负责:
- 存放数据;
- 文件被分割以Block的形式被存储在磁盘上;
3.Secondarynode
SecondaryNameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个SecondaryNameNode,并且部署在一个单独的服务器上。
SecondaryNameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的快照。由于NameNode是单点的,通过SecondaryNameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,SecondaryNameNode可以及时地作为备用NameNode使用。
它主要将namenode image(fsimage)和Edit log合并的。
SecondaryNameNode的处理,是将fsimage和edites文件周期的合并,不会造成nameNode重启时造成长时间不可访问的情况。
4.Resourcemanager
(1)与客户端进行交互,处理来自于客户端的请求,如查询应用的运行情况等。
(2)启动和管理各个应用的ApplicationMaster,并且为ApplicationMaster申请第一个Container用于启动和在它运行失败时将它重新启动。
(3)管理NodeManager,接收来自NodeManager的资源和节点健康情况汇报,并向NodeManager下达管理资源命令,例如kill掉某个container。
(4)资源管理和调度,接收来自ApplicationMaster的资源申请,并且为其进行分配。这个是它的最重要的职能。
5.Nodemanager
NM是ResourceManager在每台机器上的代理,负责容器管理,并监控它们的资源使用情况,以及向ResourceManager/Scheduler提供资源使用报告。
总结:
(1)NameNode与ResourceManager分开部署(都是老大)
(2)NodeManager 也就是Resoucemanager 的“小弟”,它来做这事情,读取hdfs 上的数据,数据保存在datanode上,所以如果数据集群,datanode 与NodeManager ,一定要保存在同一个节点上
(3)Resoucemanager : 占用端口:8088 进行调度资源(老大),进行任务分配的,谁来做这个事情

 浙公网安备 33010602011771号
浙公网安备 33010602011771号