mysql之查询语句练习题
一、连接启动数据库
1.打开phpstudy启动mysql
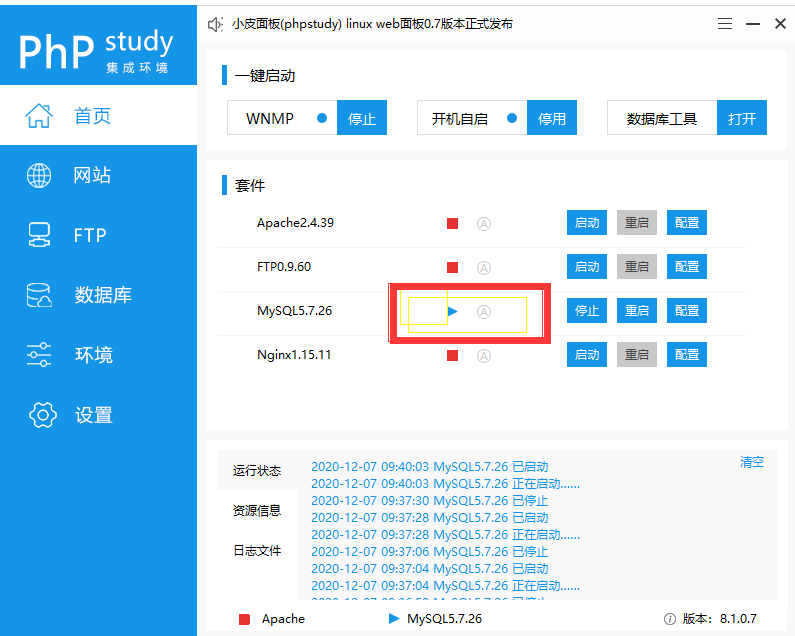
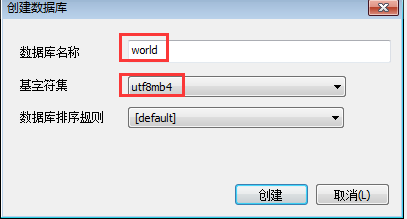
2.创建数据库
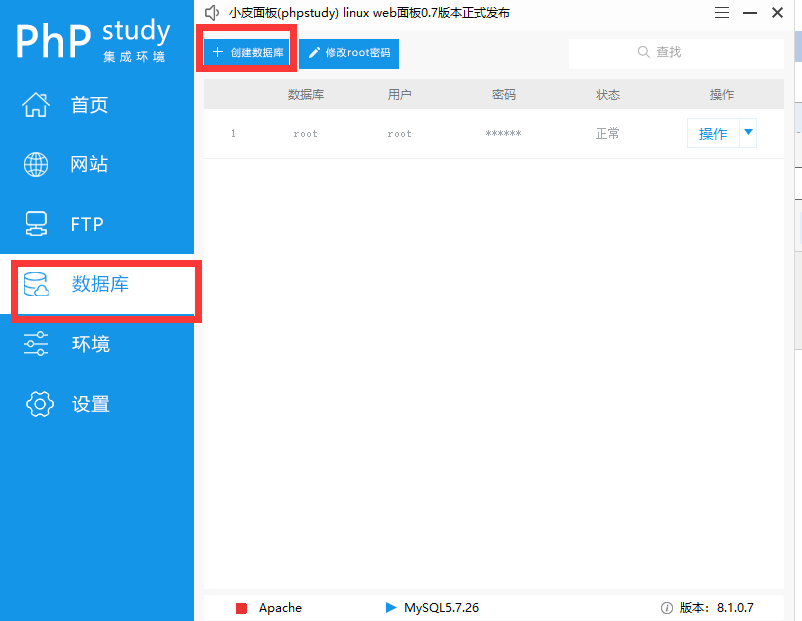
3.
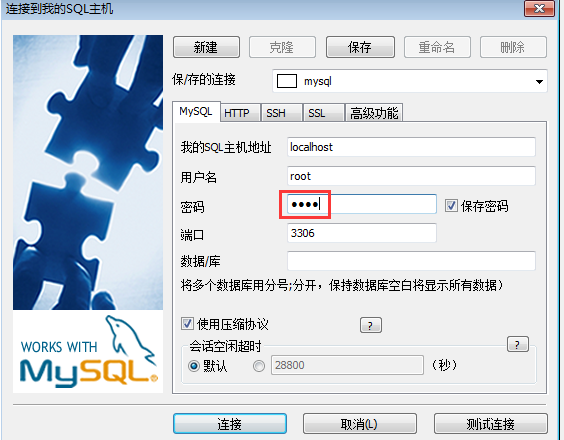
4.测试连接
5.连接
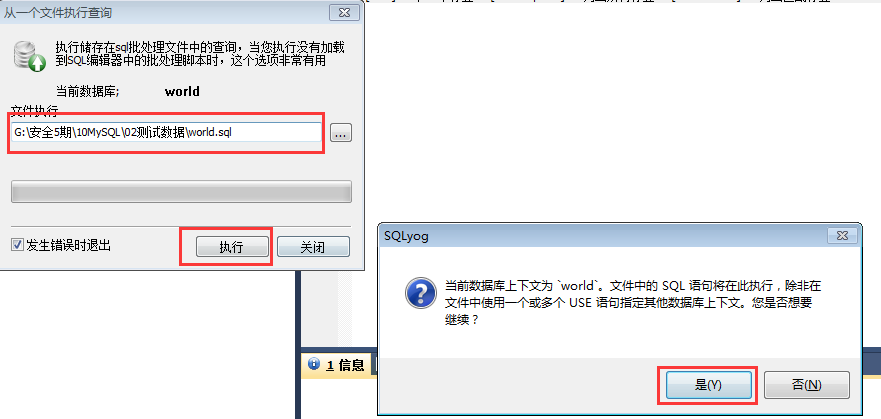
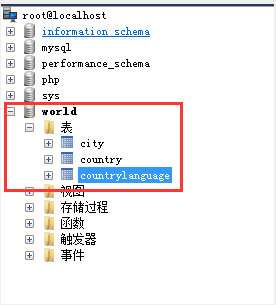
6.导入数据库
二、查询语句练习题
1.查询表里所有的数据
SELECT * FROM City;
2.查询部分字段的数据
select * from 表 where 字段
3.查询city表中,所有中国的城市信息 CHN
SELECT * FROM city WHERE CountryCode='CHN';
4.查询city表中,城市名称叫北京的信息
SELECT * FROM city WHERE NAME='Peking';
5.查询人口数小于100人城市信息
SELECT * FROM city WHERE Population<100;
6.查询中国,人口数超过500w的所有城市信息
SELECT * FROM city WHERE CountryCode='CHN' AND Population>5000000;
7.查询中国或美国的城市信息
SELECT * FROM city WHERE CountryCode='CHN' OR CountryCode='USA';
8.查询人口数为100w-200w(包括两头)城市信息
SELECT * FROM city WHERE Population >=1000000 AND Population<=2000000;
9.查询中国或美国,人口数大于500w的城市
SELECT * FROM city WHERE (CountryCode = 'CHN' OR 'USA') AND Population>5000000;
10.查询城市名为qing开头的城市信息
SELECT * FROM city WHERE NAME LIKE 'qing%';
11.查询城市名为jing结尾的城市信息
SELECT * FROM city WHERE NAME LIKE '%jing';
12.查询mysql里都有哪些用户和主机地址
SELECT USER,HOST FROM mysql.`user`;
13.查询表的字段都有哪些
desc city;
1.统计city表的行数
SELECT COUNT(*) FROM city;
2.统计中国城市的个数
SELECT COUNT(*) FROM city WHERE CountryCode='CHN';
3.统计中国的总人口数
SELECT SUM(Population) FROM city WHERE CountryCode='CHN';
4.统计每个国家的城市个数 group by
SELECT COUNT(*),CountryCode FROM city GROUP BY CountryCode;
5.统计每个国家的总人口数
SELECT SUM(Population),CountryCode FROM city GROUP BY CountryCode;
6.统计中国每个省的城市个数及城市名列表
SELECT District,COUNT(NAME),GROUP_CONCAT(NAME)
FROM city WHERE CountryCode= 'CHN' GROUP BY District;
7.计算人口数超过1亿的国家
SELECT SUM(Population),CountryCode
FROM city GROUP BY CountryCode
HAVING SUM(Population)>100000000;
8.查询所有城市信息,并按照人口数排序输出
SELECT NAME,Population FROM city ORDER BY Population;
9.计算人口数超过500万的国家并且降序排序
SELECT SUM(Population),CountryCode FROM city
GROUP BY CountryCode
HAVING SUM(Population)>5000000 ORDER BY
SUM(Population)DESC;
10.查询中国所有的城市信息,并按照人口数从大到小排序输出,只显示前十名
SELECT NAME,Population FROM city
WHERE CountryCode='chn' ORDER BY Population DESC
LIMIT 10;
11.查询中国所有的城市信息,并按照人口数从大到小排序输出,跳过前6行,显示后面10行
SELECT id,NAME,Population FROM city
WHERE CountryCode='chn' ORDER BY Population DESC
LIMIT 6,10;
12.执行顺序
select select_list from where group_by having order by limit
4 1 2 3 5 6 7
SELECT SUM(Population),countrycode
FROM city
GROUP BY countrycode
HAVING SUM(Population) > 50000000
ORDER BY SUM(Population) DESC
LIMIT 10;
三、having用法
用法与where用法类似,但是又三点不同
1.having只用于group by (分组统计语句)
2.Where是用于初始表中筛选查询,having用于where和group by 结果中查询
3.having可以使用聚合函数,但是where不行
4.例
计算人口数超过500万的国家并且降序排序;
SELECT SUM(Population),CountryCode FROM city
GROUP BY CountryCode
HAVING SUM(Population)>5000000 ORDER BY
SUM(Population)DESC;
先用group by用来分组,再用having进行过滤大于500万的,
例:
Select city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
作用的对象不同。WHERE 子句作用于表和视图,HAVING 子句作用于组。
WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算),
而 HAVING 在分组和聚集之后选取分组的行。因此,WHERE 子句不能包含聚集函数;
因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。 相反,HAVING 子句
总是包含聚集函数。(严格说来,你可以写不使用聚集的 HAVING 子句,但这样做只
是白费劲。同样的条件可以更有效地用于 WHERE 阶段。)在前面的例子里,我们可
以在 WHERE 里应用城市名称限制,因为它不需要聚集。 这样比在 HAVING 里增加
限制更加高效,因为我们避免了为那些未通过 WHERE 检查的行进行分组和聚集计算
综上所述:
having一般跟在group by之后,执行记录组选择的一部分来工作的。
where则是执行所有数据来工作的。
再者having可以用聚合函数,如having sum(qty)>1000
四、group by 与having
1.group by语句,从英文的字面意思来讲就是“根据(by)一定的规则进行分组(group)
作用:用过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理,
注意:group by是先排序后分组
举例说明:如果用到group by 一般用到的就是“每”这个字,例如现在有这样一个需求:
查询每个部门有多少人,就要用到分组的技术
2.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号