

re模块
findall(正则表达式,字符串)
s = 'hghg659.,jh3565' ret = re.findall('\d+', s) print(ret)
返回一个匹配后的列表
search(正则表达式,字符串)
s = 'hghg659.,jh3565' ret = re.search('\d+', s) if ret: print(ret.group()) else: print(ret)
匹配到的值需要用group()方法取值
match(正则表达式,字符串)
s = '654woheni521今天七夕' ret = re.match('\w+', s) print(ret.group())
匹字符串开始的位置
split(正则表达式,字符串)
s = '今天七夕521你过得好吗525,其实不好对吧222' ret = re.split('\d{3},?', s) print(ret) 使用正则切割字符串,返回一个列表
sub(正则表达式,替换的新的内容,字符串,替换次数)
s = '今天七夕521你过得好吗525,其实不好对吧222' ret = re.sub('\d{3},?', '666', s, 2) print(ret)
compile(正则表达式)
ret = re.compile('\d{3},?') result = ret.findall(s) print(result) result = ret.search(s) print(result.group()) 这个是先编译好一个正则,然后后续匹配直接使用
比较节省时间
filter(正则表达式,字符串)
ret = re.finditer('\d{3},?', s) print(list(el.group() for el in ret)) filter()返回的是一个迭代器
他比较节省空间
括号的优先级和使用
s = 'hehe65hh' ret = re.findall('\w(\d+)\w',s) print(ret) # 本来我们想要的是'e65h',但是由于()的优先级导致我们的结果是'65' #想要取消()优先级 s = 'hehe65hh' ret = re.findall('\w(?:\d+)\w',s) print(ret) #()的使用 s = 'hehe65hh' ret = re.search('\w(?P<name>\d+)\w',s) print(ret.group('name')) #可以通过命名来获取到值
注意:在search()方法中是不存在括号优先级的,但如果你用的是()来命名取值的则是取到()里的值
random模块
random()方法:
r = random.random() #获取0-1之间的随机小数 print(r)
randint()方法:
r = random.randint(a,b) #获取a-b之间的随机整数,顾头顾尾 print(r)
uniform()方法:
r = random.uniform(a,b) #获取a-b之间的随机小数,顾头顾尾 print(r)
randrange()方法:
r = random.randrange(a,b) #获取a-b之间的随机整数,顾头不顾尾 print(r)
sample()方法:
lst = [2,6,9,45] r = random.sample(lst,2) #从lst中随机取出两个组成一个新列表 print(r) #[6, 9]
shuffle()方法
li = [1, 2, (2, 3), 'haha'] print(random.shuffle(li)) #随机打乱这个列表序列
choice()方法
li = [1, 2, (2, 3), 'haha'] print(random.choice(li)) #从列表中随机选择一个
time模块
time模块是用来表示时间的模块
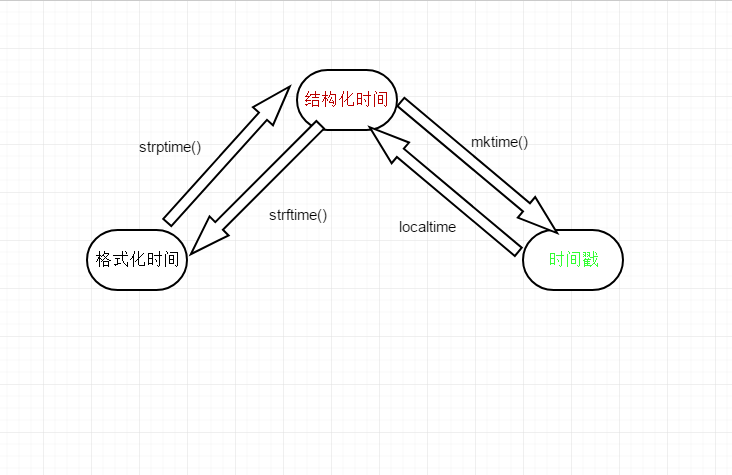
time模块一般是有三种时间形式:
- 时间戳时间>>>>就是从某一个时间开始已知道此时的时间秒数
- 结构化时间
- 格式化时间(字符串格式)
time()方法:获取当前时间的时间戳
localtime(时间戳)方法:把传入的时间戳转换成结构化时间
strptime()方法;将结构化时间转成格式化时间
strftime()方法:将格式化时间转成结构化时间
mktime()方法:将结构化时间转成时间戳
t = time.time() #获取当前时间时间戳 print(t) #1535375940.3338828 t1 = time.localtime(t) # 将时间戳转成结构化时间 print(t1) #time.struct_time(tm_year=2018, tm_mon=8, tm_mday=27, tm_hour=21, tm_min=26, tm_sec=46, tm_wday=0, tm_yday=239, tm_isdst=0) t2 = time.strftime('%Y-%m-%d %H:%M:%S',t1) #将结构化时间转成格式化时间 print(t2) #2018-08-27 21:31:37 t3 = time.strptime('2018-08-27 21:31:37','%Y-%m-%d %H:%M:%S') #将字符串时间转成结构化时间 print(t3) #time.struct_time(tm_year=2018, tm_mon=8, tm_mday=27, tm_hour=21, tm_min=31, tm_sec=37, tm_wday=0, tm_yday=239, tm_isdst=-1) t4 = time.mktime(t3) # 将结构化时间转成时间戳 print(t4) #1535376697.0
图示:
json模块
json模块一般是用来把写入文件的转义成可以写入文件的格式,然后取出来,json模块是支持不同语言之间的传读文件的
dic = {'name': '杨', 'age': '21'}
with open('json', mode='a', encoding='utf-8') as f:
ret = json.dumps(dic)
f.write(ret+"\n")
# 将字典转化字符串写入
with open('json', mode='r', encoding='utf-8') as f1:
print(json.loads(f1.read()))
# 将文件的字符串转换成字典读出
# 但要注意dumps和loads方法只支持单个的读存
with open('json', 'r') as f1: for line in f1: print(json.loads(line.strip())['name']) #读取的时候是可以遍历文件一行一行取的 # 存的时候只能多次执行存操作来完成存多行 dic = {'name': '杨', 'age': '21'} with open('json', mode='a', encoding='utf-8') as f: ret = json.dumps(dic) f.write(ret+'\n') ret = json.dumps(dic) f.write(ret+'\n') ret = json.dumps(dic) f.write(ret+'\n')
pickle模块
pickle模块是来完成将要存入文件的格式转换成bytes格式的,取的时候在转回来,只支持python之间的传递
# 序列化之后写入文件 dic = {'name': '杨', 'age': '21'} with open('pickle', mode='ab') as f: a = pickle.dumps(dic) # 序列化 f.write(a) # 反序列化读出 with open('pickle', mode='rb') as f1: print(pickle.load(f1)) # 反序列化取出
因为序列化之后是bytes格式,所以读取要用wb,rb等模式
# 如果文件有多条,持续读出 with open('pickle', mode='rb') as f1: while 1: try: print(pickle.load(f1)) except EOFError: # 抛出异常 break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号