
4.RDD操作
5.RDD操作综合实例
一、词频统计
A. 分步骤实现
- 准备文件
- 下载小说或长篇新闻稿

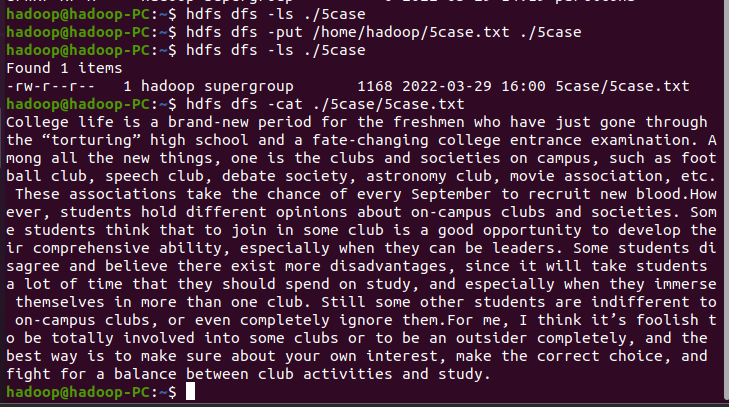
- 上传到hdfs上
hdfs dfs -put /home/hadoop/5case.txt ./5case
- 读文件创建RDD
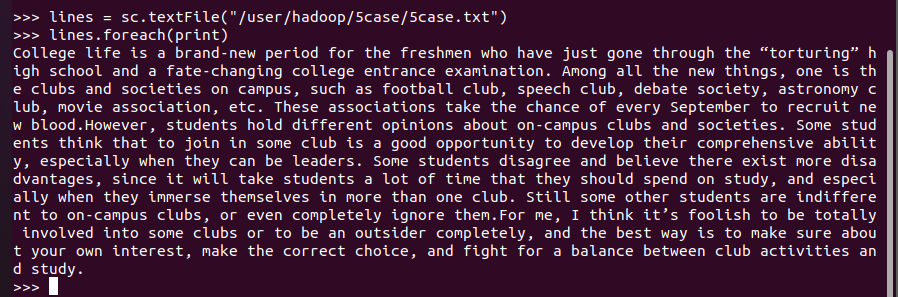
lines = sc.textFile("/user/hadoop/5case/5case.txt")
- 分词
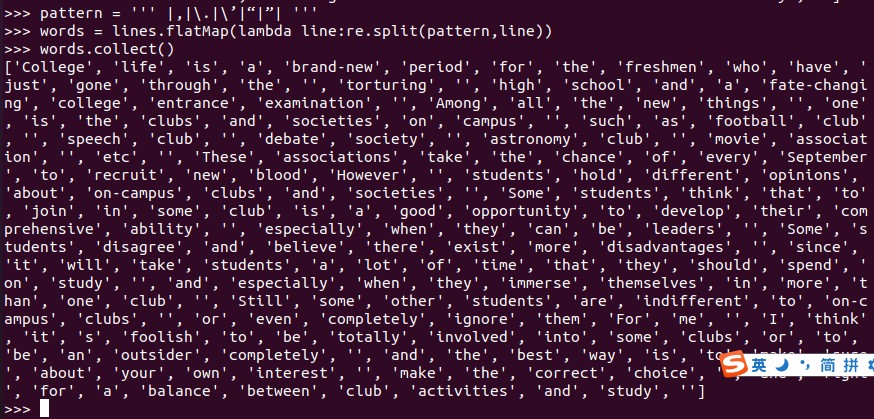
pattern = ''' |,|\.|\’|“|”| ''' |为间隔符 \为防转义符
words = lines.flatMap(lambda line:re.split(pattern,line))
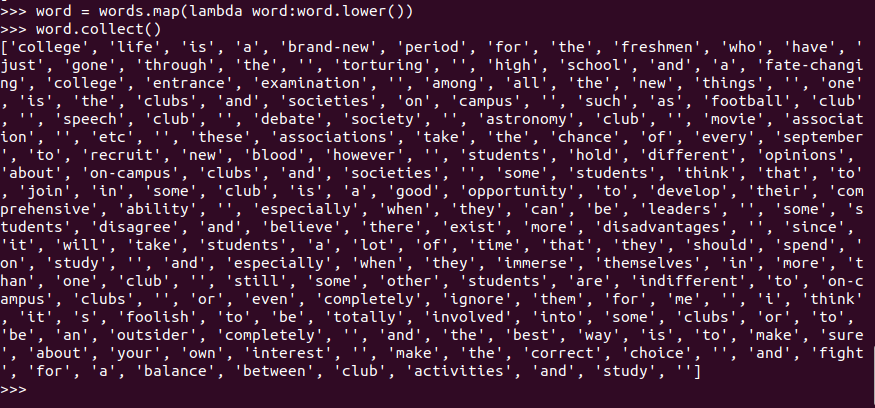
- 排除大小写lower(),map()
words.map(lambda word:word.lower())
标点符号re.split(pattern,str),flatMap(),
停用词,可网盘下载stopwords.txt,filter(),
with open("/home/hadoop/stopwords.txt") as stoplines:
stopwords = stoplines.read().split()
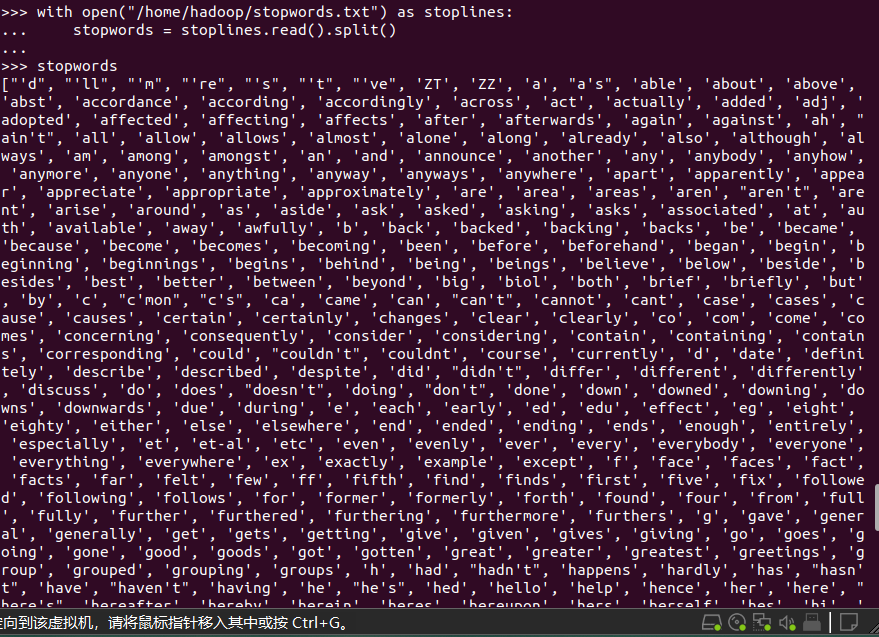
words.filter(lambda words:word not in stopwords)
word.filter(lambda x:x not in stopwords)过滤停顿词
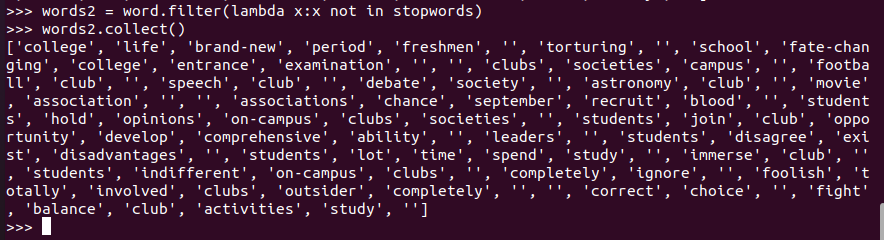
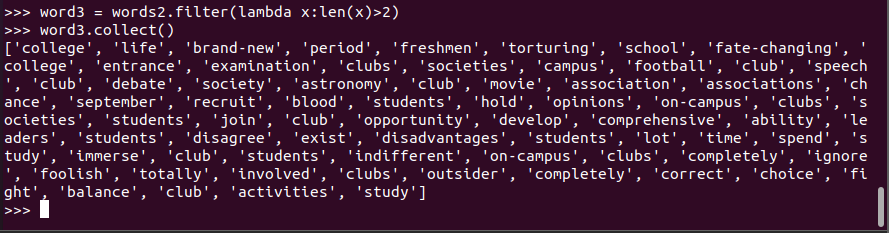
长度小于2的词filter()
word.filter(lambda x:x not in stopwords)
words2.filter(lambda x:len(x)>2) 过滤长度小于2的单词
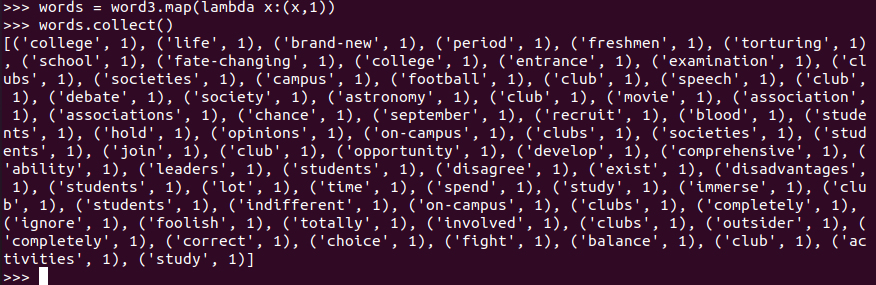
- 统计词频
word = words.map(lambda word:(word,1))
- 按词频排序
words.reduceByKey(lambda a,b:a+b)
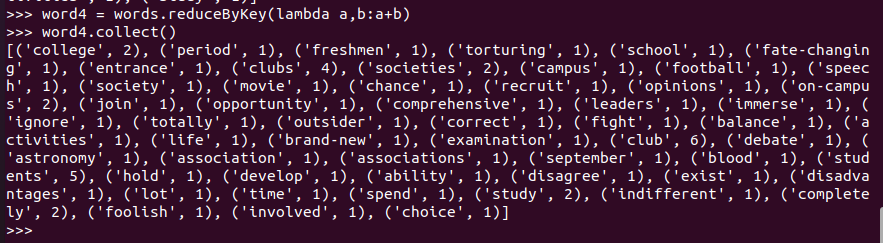
word4.sortBy(lambda x:x[1],False,1) ('students', 5) x[ 1 ]è5 False为降序,True为升序 1为处理存放的块数,默认为10块
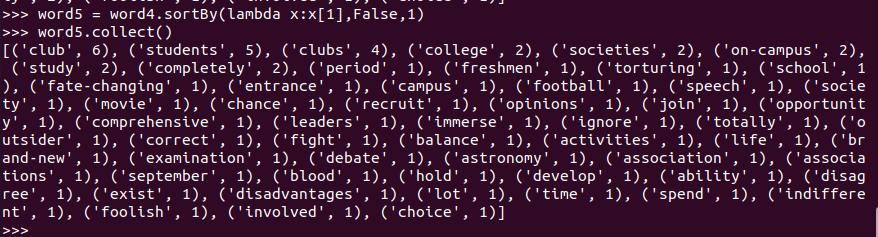
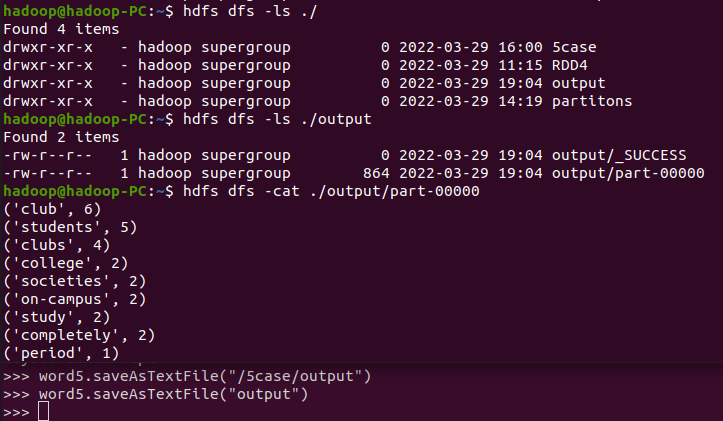
- 输出到文件
word5.saveAsTextFile("output")
- 查看结果
dfs dfs -cat /user/Hadoop/文件所在路径

 浙公网安备 33010602011771号
浙公网安备 33010602011771号