“千言数据集:文本相似度”权威评测,网易易智荣登榜首
日前,网易数帆旗下人工智能技术与服务品牌——网易易智在CCF和百度联合举办的“千言数据集:文本相似度”行业测评中击败多支劲旅,荣登榜首。
文本相似度,即识别两段文本在语义上是否相似,在自然语言处理(NLP)领域是一个重要研究方向,目前已大规模商用于智能客服、信息检索、新闻推荐等领域,如已服务超40万企业客户的网易七鱼智能客服,背后就有这项技术的支撑。
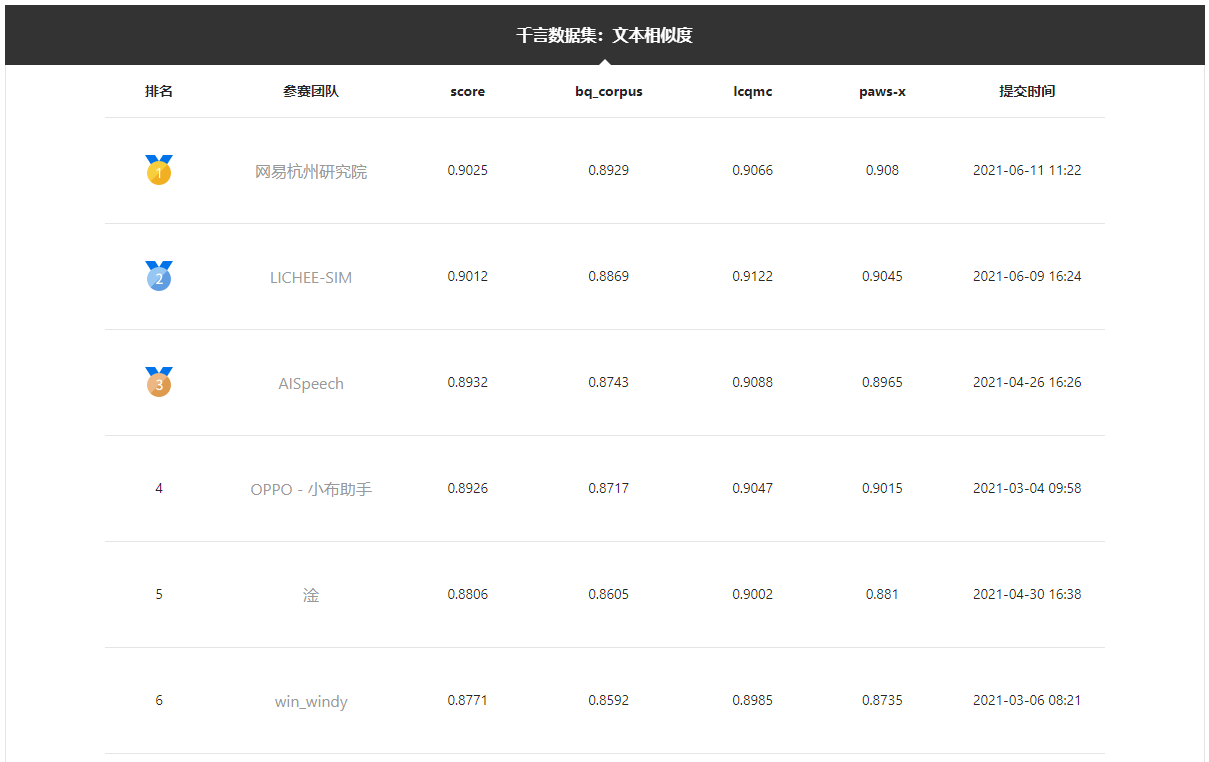
榜单中“网易杭州研究院”为网易易智团队
知识沉淀与技术积累立功,网易易智文本相似度雄踞榜首
“千言数据集”系列评测是中文自然语言处理领域的大规模赛事,其中文本相似度开源项目收集了来自哈尔滨工业大学的LCQMC、BQ Corpus,以及谷歌的PAWS-X(中文)等公开数据集,期望对文本相似度模型效果进行综合的评价,推动文本相似度在自然语言处理领域的应用和发展。
据了解,这些公开数据集在相关论文的支撑下,对现有的公开文本相似度模型进行了较全面的评估,具有较高的权威性,代表了文本相似度技术研究的最高水准。
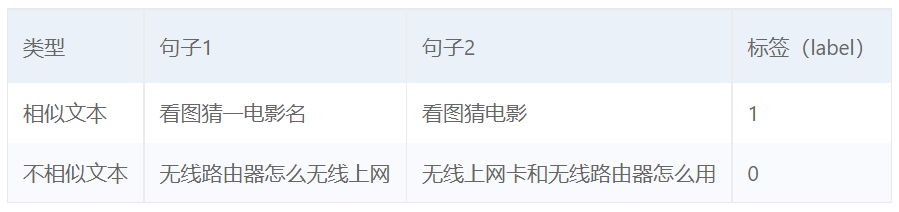
哈尔滨工业大学(深圳)LCQMC数据集任务示例
在本次文本相似度测评中,网易易智结合了多年技术经验积累,和大规模预训练语言模型的运用,再加上对比赛任务进行的针对性优化,取得了目前的优异成绩。
网易易智的参赛队伍表示,这次比赛任务主要有2个难点。一个难点是BQ Corpus数据集是金融领域的数据,该数据集涉及到金融行业的大量知识,而通用预训练语言模型难以捕捉到特定行业的潜在知识。为此,团队采用半监督学习等方式,从网易内部多个业务场景中挖掘出泛金融领域知识,进而获得金融领域预训练语言模型,最终在该任务上较大幅度领先于其他参赛团队。
而另一个难点是PAWS-X数据集的质量问题,该数据来自于英文的翻译,翻译内容与真实中文有出入,尤其会对算法造成干扰的是实体词(如人名、地名)的翻译不统一,即相同的人名,前一个句子保留英文原文,后一个句子却音译为中文。针对这个数据特点,网易易智利用自研的NER(命名实体识别)服务进行实体词的识别与归一化,并利用自研的中文文本纠错服务纠正其中的错别字、语病之后,再进行模型训练,最终在该任务上也取得了第一。
网易易智助力七鱼机器人精准理解客户诉求
网易易智基于文本相似度等系列NLP技术构建了一套智能对话系统,服务集团内部多个业务,如严选客服、IT咨询等,并与七鱼业务联合打造智能客服机器人产品,服务集团外部客户。
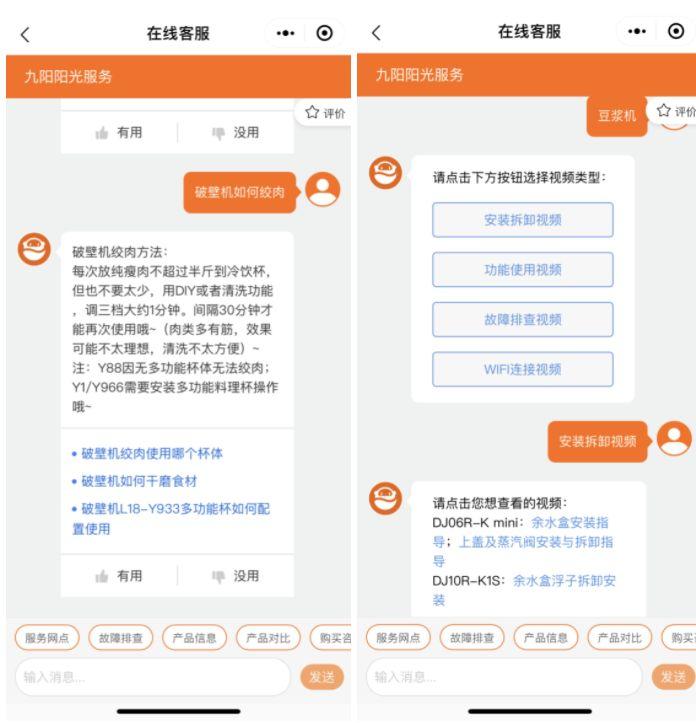
以九阳股份有限公司为例,其核心诉求之一,是通过高效、精准、人性化的咨询服务保障用户的购物体验,如用户对于小家电产品功能、操作、价格、优惠活动、养护、维修等问题的咨询。
为此,九阳接入了网易七鱼在线机器人,在问题匹配率可高达90%以上的基础上,提供更懂用户的智能服务体验。**基于网易易智文本相似度算法,七鱼在线机器人实现了核心语义匹配,从而达成BOT、FAQ等功能。此外,通过语义匹配技术,七鱼在线机器人还实现了对知识库的智能挖掘与生成。**借助这些能力,七鱼在线机器人可以高效、精准地解答不同场景下的客户问题。
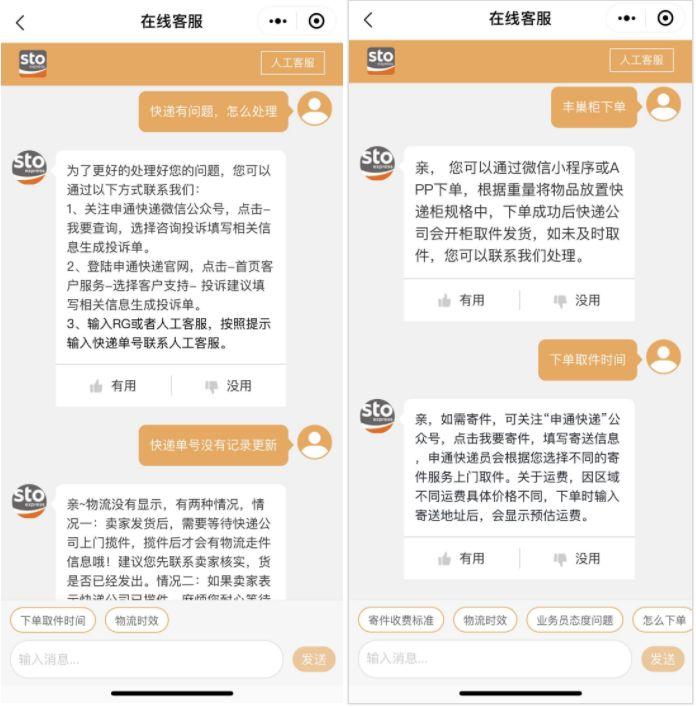
而在快递领域,申通快递也接入了七鱼智能客服应对快递咨询问题,这是一个与上述金融、小家电完全不同的领域,然而运用网易易智同样的技术原理,智能客服快速实现了相似的效果。
网易易智NLP促进数字业务创新
文本相似度技术的商业价值并不局限于智能客服领域。据网易易智负责人介绍,文本相似度技术大类归于文本匹配,除了对话引擎里,该技术在网易内部还有更多的应用落地,如网易云音乐中的评论智能挖掘、直播/短视频中的歌词匹配以及知识公路业务中的视频选题相似度检测等创新解决方案应用。
而从整个技术领域来看,作为一门让机器理解人类语言的技术,NLP素有“人工智能皇冠上的明珠”之称,既是难以攻克的前沿课题,也对数字业务创新具有重要的意义。除了文本相似度,网易易智也一直在探索NLP技术与业务创新的最大公约数,并取得了一些阶段性的成果。
例如,语义解析技术在软件测试中的使用,显著提升自动化水平、实现降本增效,这对于数字化软件质量的保障非常有利;文本纠错技术在网易新闻等文稿审校场景中大规模使用,将拼写及语法等错误及时发现并予以纠正,大幅提升用户阅读体验,同时降低内容生产的工作量。
未来,网易易智还将联合网易数帆旗下有数团队,探索NLP在大数据系统中的应用,如支持业务人员与分析系统的自然语言交互,使得企业能够更好地发挥大数据的价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号