
大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
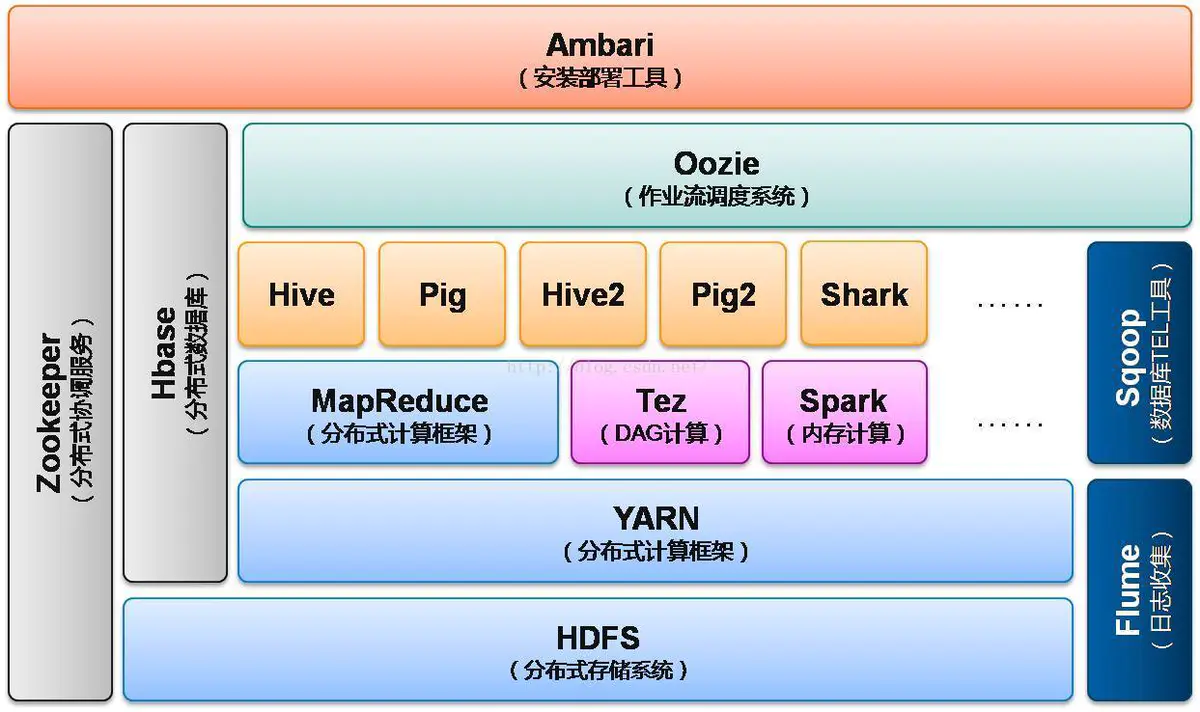
1,HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。
2,mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。
3, hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
4,hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。
5,zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6,sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。
7,pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。
8,flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。
9,yarn(资源管理器)
ResourceManager(JobTracker):负责调度DataManager上的资源,每个DataNode都有一个NodeManager(TaskTracker)来执行实际工作。
10,Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。
11,Ambari(安装部署配置管理工具)
Apache Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。
12,Tez(DAG计算模型)
Tez是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分。
2.对比Hadoop与Spark的优缺点。

3.如何实现Hadoop与Spark的统一部署?
Hadoop和Spark都可以在资源管理器yarn时运行,所以可以在yarn上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号