

ComputerVision:图片分类01
目标: 实现图片分类
input: 一组图片数据 (x,y)
output:预测一组新图片(给定x)的y值
工具
要实现这个目标,需要工具(概念+思路)。
思路
1.数据读取,
2.建立模型,
3.预测
所以我们需要3个.py文件:
model.py:用来编写我们设计的模型。【这样我们可以根据预测效果来调整模型/更换模型】
train.py:用来读取图片数据/训练模型/验证模型(定超参数)/输出训练后的模型参数以及相关参数(图片标签编码数据)。
predict.py:用来读取待预测的图片数据/数据预处理/加载训练后的模型/预测图片标签值。
建议使用命令行操作,具体优点参见该国外大牛的网站:https://www.pyimagesearch.com/。
概念
0.参数解析
由于你需要在将本地图片数据加载到程序中,所以在通过命令行运行.py脚本的时候,你得传入相关参数,告知你要去哪里调用你的图片文件。
例如:我下载了kaggle比赛数据(植物幼苗图片分类:Plant Seedlings Classification)
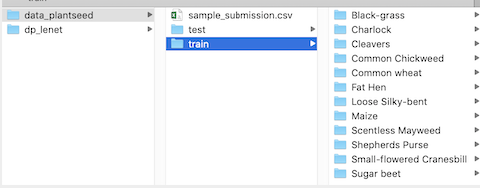
编写train.py文件
#配置参数
import argparse
import os
from imutils import paths
ap = argparse.ArgumentParser()
ap.add_argument('-d','--dataset',required=True,help='path to input dataset of images')
args = vars(ap.parse_args())
imagePaths = sorted(list(paths.list_images(args['dataset'])))
运行如下命令,即可完成图片文件路径加载:
python train.py --dataset /data_plantseed/train
1.图片
读取:image = cv2.imread(imagePath) #opencv
格式:image.shape #eg:(1365, 2048, 3),(高度,宽度,通道数)
尺寸转化:image = cv2.resize(image,(28,28)) #压缩图片高度和宽度
标签编码:
lb = LabelBinarizer()
trainlabels = lb.fit_transform(trainlabels)
testlabels = lb.transform(testlabels)
由于实际处理数据中,不像MNIST数据集可以直接通过tensorflow.keras.datasets导入,需要自己完成数据导入。所有在处理图片数据的时候,需要借助两个工具:from imutils import paths 和 import os 。
imagePaths = sorted(list(paths.list_images(args['dataset'])))
random.seed(42)
random.shuffle(imagePaths)
data = []
labels = []
for imagePath in imagePaths:
image = cv2.imread(imagePath)
image = cv2.resize(image,(28,28))
data.append(image)
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
data = np.array(data,dtype='float')/255.0
labels = np.array(labels)
将所有图片加载到tensor中,可以再进行scale,从而得到符合入模型的预处理数据。紧接着可以进行数据集划分(train,validation)
2.
参考来源:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号