x64体系的变化

x64体系的变化
1. x64体系寄存器
|---- 64位(8字节) ----|---- 32位(4字节) ----|---- 16位(2字节) ----|---- 8位(1字节) ----|
Rax Eax ax al, ah
Rcx Ecx cx cl, ch
Rdx Edx dx dl, dh
Rbx Ebx bx bl, bh
Rsp Esp sp spl,
Rbp Ebp bp bpl,
Rsi Esi si sil,
Rdi Edi di dil,
R8 R8d R8w R8b
R9 R9d R9w R9b
R10 R10d R10w R10b
R11 R11d R11w R11b
R12 R12d R12w R12b
R13 R13d R13w R13b
R14 R14d R14w R14b
R15 R15d R15w R15b
Rip
2. 操作数大小统一变成 8 字节操作(PUSH、POP等等)
Rip可读取, 例如 mov rax, [rip + 0x32]
3. 符号拓展
X64体系中只实现了48位的虚拟地址, 高16位被用做符号拓展。着高16位必须要么全是0, 要么全是1, 而这种形式的地址被称为 Canonical。

4. X64体系中默认采取Rsp寻址的方式, 且函数调用约定均为X64 fastCall
5. X64 下 GS Ring0 指向 KPCR, Ring3 指向 TEB64, FS Ring3 指向 TEB32, Ring0 指向 TEB32
6. 对于 32 位寄存器的写操作(包括运算结果), 相对应的64位寄存器的高32位清0
7. x64虚拟地址空间变化
User 空间开头 16 位一定为0,Kernel 空间开头 16 位一定为1
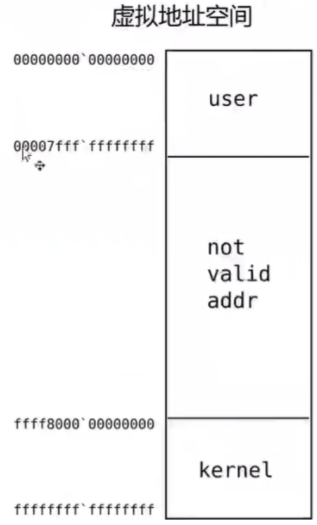
8. 内存优先使用相对偏移寻址, 直接寻址指令较少
9. x64 跳转目标地址得方式
短跳: EB FE jmp 自己(寻址范围 上下 128 字节)
普通跳: jmp xxxxxxxx (寻址范围 上下 2GB)
大跳1: FF 25 jmp qword ptr [xxxxxxxx] (读取8字节内存地址并跳转, 寻址范围 上下 8GB)
大跳2: (寻址范围 上下 8GB, 利用寄存器跳转)
mov rax, 0x123456789
jmp rax
大跳3: (寻址范围 上下 8GB, 利用寄存器跳转)
mov rax, 0x123456789
push rax
ret
一般大跳返回方式1: (寻址范围 上下 8GB, 但不影响关键寄存器, 注意 rsp 无法直接 mov qword)
sub rsp, 0x8;
mov dword ptr ss:[rsp], 0x1234
mov dword ptr ss:[rsp + 0x4], 0x56789ABC
ret
一般大跳返回方式2: (寻址范围 上下 8GB, 但不影响关键寄存器, 注意 rsp 无法直接 mov qword)
push 0x12345678
mov dword ptr ss:[rsp + 0x4], 0x56789ABC
ret
// 注意一个奇怪跳转,编译器不会报错
jmp qword ptr [0x123456789] // 这种跳转内存地址,汇编翻译最后会被截断为内存地址后4字节
10. x64 fastCall 讲解
X64 体系中不存在其他调用约定只有一个 X64fastCall 调用, 它与 X86 的 fastCall 不一样
函数传参从右往左依次赋值并压入 R9、R8、Rdx、Rcx, 若超过4个参数则会调用堆栈传参
// 以下是手写的一段汇编代码
// 编译器默认会认为子函数可能会用用堆栈, 所以先在主函数开辟了堆栈(注意是外平栈)
// 要注意如果是 4 个参数, 建议开辟 sub rsp,20h 空间
// 第五个参数传入了 [rsp + 20h] 处
// 最后要注意 X64 调用多个函数时, 会在主函数先把各个子函数所需要的最大堆栈开辟出来
asm_fun proc
mov rcx, 1h;
mov rdx, 2h;
mov r8, 3h;
mov r9, 4h;
sub rsp, 28h;
mov qword ptr [rsp + 20h], 5h;
call func;
add rsp, 28h;
ret;
asm_fun endp;
// func 函数
void func(ULONG64 arg1, ULONG64 arg2, ULONG64 arg3, ULONG64 arg4, ULONG64 arg5)
{
printf("arg1: %x\n", arg1);
printf("arg2: %x\n", arg2);
printf("arg3: %x\n", arg3);
printf("arg4: %x\n", arg4);
printf("arg4: %x\n", arg5);
}
// func 函数汇编
// 开门见山将前四个参数压入到之前主函数开辟的堆栈中
00007FF720EF76C0 mov qword ptr [rsp+20h],r9
00007FF720EF76C5 mov qword ptr [rsp+18h],r8
00007FF720EF76CA mov qword ptr [rsp+10h],rdx
00007FF720EF76CF mov qword ptr [rsp+8],rcx
00007FF720EF76D4 push rbp
00007FF720EF76D5 push rdi
00007FF720EF76D6 sub rsp,0E8h
00007FF720EF76DD lea rbp,[rsp+20h]
00007FF720EF76E2 mov rdi,rsp
00007FF720EF76E5 mov ecx,3Ah
00007FF720EF76EA mov eax,0CCCCCCCCh
00007FF720EF76EF rep stos dword ptr [rdi]
00007FF720EF76F1 mov rcx,qword ptr [rsp+0000000000000108h]
00007FF720EF76F9 lea rcx,[00007FF720FFB033h]
00007FF720EF7700 call 00007FF720EF1825
printf("arg1: %x\n", arg1);
00007FF720EF7705 mov rdx,qword ptr [rbp+00000000000000E0h] // 随后通过 Rbp 寻址
00007FF720EF770C lea rcx,[00007FF720FBCF88h]
00007FF720EF7713 call 00007FF720EF27F2
...
以上就是X64特色调用约定
11. 进入 call 之前rsp满足0x10字节对齐
12. 易变寄存器: rax, rcx, rdx, r8, r9, r10, r11(容易被使用的寄存器)
13. 一次函数分析
typedef struct MyStruct
{
int a;
int b;
int c;
};
// Code
int main()
{
MyStruct struMe = { 0x0 };
Test(struMe, 1, 2, 3);
return 0x0;
}
MyStruct Test(MyStruct stru, int x, int y, int z)
{
stru.a = x;
stru.b = y;
stru.c = z;
return stru;
}
MyStruct struMe = { 0x0 };
00007FF6C3E718FC lea rax,[struMe]
00007FF6C3E71900 mov rdi,rax
00007FF6C3E71903 xor eax,eax
00007FF6C3E71905 mov ecx,0Ch
00007FF6C3E7190A rep stos byte ptr [rdi] // 通过循环填充0x0到结构体 struMe 中
Test(struMe, 1, 2, 3);
00007FF6C3E7190C lea rax,[rbp+160h]
00007FF6C3E71913 lea rcx,[struMe]
00007FF6C3E71917 mov rdi,rax
00007FF6C3E7191A mov rsi,rcx
00007FF6C3E7191D mov ecx,0Ch
00007FF6C3E71922 rep movs byte ptr [rdi],byte ptr [rsi] // 将 struMe 进行了一波浅拷贝
00007FF6C3E71924 mov dword ptr [rsp+20h],3 // 传参
00007FF6C3E7192C mov r9d,2 // 传参
00007FF6C3E71932 mov r8d,1 // 传参
00007FF6C3E71938 lea rdx,[rbp+160h] // 传参
00007FF6C3E7193F lea rcx,[rbp+128h] // 传参
00007FF6C3E71946 call Test (07FF6C3E71005h)
00007FF6C3E7194B lea rcx,[rbp+0F8h]
00007FF6C3E71952 mov rdi,rcx
00007FF6C3E71955 mov rsi,rax // Rax = (rbp+128h), 存储返回值
00007FF6C3E71958 mov ecx,0Ch
00007FF6C3E7195D rep movs byte ptr [rdi],byte ptr [rsi] // 拷贝返回值到(rbp+0F8h)
MyStruct Test(MyStruct stru, int x, int y, int z)
{
00007FF6C3E71730 mov dword ptr [rsp+20h],r9d // 将参数存入到内存中
00007FF6C3E71735 mov dword ptr [rsp+18h],r8d // 将参数存入到内存中
00007FF6C3E7173A mov qword ptr [rsp+10h],rdx // 将参数存入到内存中
00007FF6C3E7173F mov qword ptr [rsp+8],rcx // 将参数存入到内存中
00007FF6C3E71744 push rbp
00007FF6C3E71745 push rsi
00007FF6C3E71746 push rdi
00007FF6C3E71747 sub rsp,0E0h
00007FF6C3E7174E lea rbp,[rsp+20h]
00007FF6C3E71753 mov rdi,rsp
00007FF6C3E71756 mov ecx,38h
00007FF6C3E7175B mov eax,0CCCCCCCCh
00007FF6C3E71760 rep stos dword ptr [rdi]
00007FF6C3E71762 mov rcx,qword ptr [rsp+108h]
00007FF6C3E7176A lea rcx,[__EC49B3D1_x64test@cpp (07FF6C3E81009h)]
00007FF6C3E71771 call __CheckForDebuggerJustMyCode (07FF6C3E71087h)
stru.a = x;
00007FF6C3E71776 mov rax,qword ptr [&stru] // 将数据填充到 stru 中
00007FF6C3E7177D mov ecx,dword ptr [x]
00007FF6C3E71783 mov dword ptr [rax],ecx
stru.b = y;
00007FF6C3E71785 mov rax,qword ptr [&stru]
00007FF6C3E7178C mov ecx,dword ptr [y]
00007FF6C3E71792 mov dword ptr [rax+4],ecx
stru.c = z;
00007FF6C3E71795 mov rax,qword ptr [&stru]
00007FF6C3E7179C mov ecx,dword ptr [z]
00007FF6C3E717A2 mov dword ptr [rax+8],ecx
return stru;
00007FF6C3E717A5 mov rdi,qword ptr [rbp+0E0h]
00007FF6C3E717AC mov rsi,qword ptr [&stru]
00007FF6C3E717B3 mov ecx,0Ch
00007FF6C3E717B8 rep movs byte ptr [rdi],byte ptr [rsi] // 将 stru 循环拷贝到 (rbp+128h)
00007FF6C3E717BA mov rax,qword ptr [rbp+0E0h] // 返回 (rbp+128h)
}
00007FF6C3E717C1 lea rsp,[rbp+0C0h]
00007FF6C3E717C8 pop rdi
00007FF6C3E717C9 pop rsi
00007FF6C3E717CA pop rbp
00007FF6C3E717CB ret
// 从上面汇编我们不难看出相比 X86 体系, X64体系代码更少效率要高点, 这一切都源自于编译器的及时编译

 浙公网安备 33010602011771号
浙公网安备 33010602011771号