


第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC
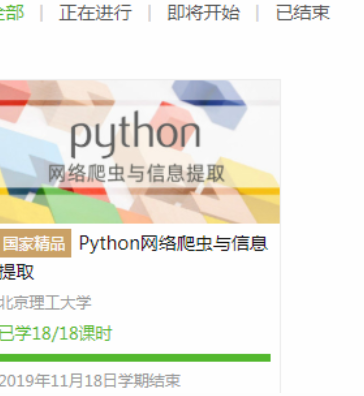
3.学习完成第0周至第4周的课程内容,并完成各周作业
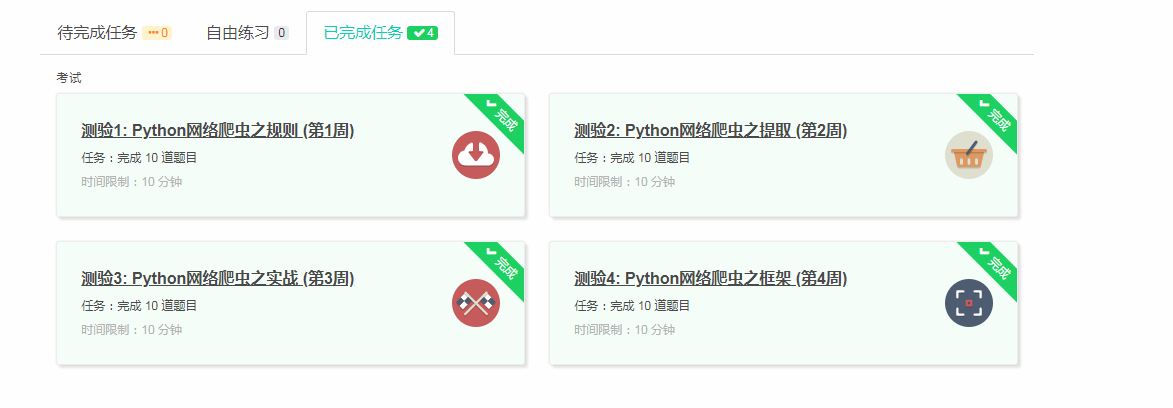
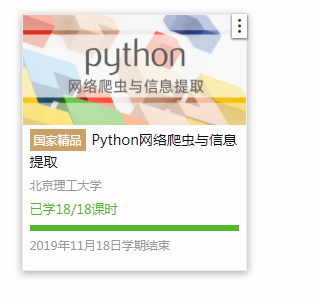
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
老师让我们找到北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程,我学习了其中四周的内容,并完成了课堂测试,收获了许多,Python是一个非常广泛使用的脚本语言,我们现在的学习生活和将来的工作生活都会很多地接触python。其自带了urllib、urllib2等基本的库,而我们看的爬虫是python最基本的库;对于“爬虫”这个名词,我感觉它是非常抽象的,这个词很形象地将它的功能必须成现实的东西,又诠释了它的功能方式。网络爬虫就是根据网页的地址来寻找网页的,也就是URL。通过四周课时的学习,我对它的理解增进了很多。
下面是我的一些读书笔记:
requests库:
requests.requests()构造一个请求,支撑一下各方法的基础方法
requests.get()获取HTML网页的主要方法,对应于HTTP的GET
requests.head()获取HRML网页头信息的方法,对应于HTTP的head
requests.post()向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put()向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch()向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete()向HTML页面提交删除请求,对应于HTTP的DELETE
requests.requests(method,url,**kwargs)
method:请求方式,对应get/put/post等7种
例:r = requests.requests('GET',url,**kwargs)
url:拟获取页面的url链接
**kwargs:控制访问的参数,共12个,分别为params,data,json,header,cookies,auth,files,timeout,proxies,allow_redirects,stream,verify,cert。
BeautifulSoup库:
BeautifulSoup类的基本元素:
Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾标签
Name:标签的名字, <>...</p>的名字是'p' ,格式: <tag> . name :
Attributes:标签的属性, 字典形式组织,格式: <tag>. attrs
NavigableString: 标签内非属性字符串,<..</>中字符串,格式: <tag>.string
Comment: 标签内字符串的注释部分, 一种特殊的Comment类型
有时候觉得python和网站的互动还是挺有意思的,但是,有可能是自身的学习程度不够,所以在看实例的时候有些吃力,理解需要花费一点时间。这次的学习让我学到了很多,受益匪浅,,也会对我以后的工作生活会有相对的帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号