
面向对象第一单元作业反思与总结
面向对象第一单元作业反思与总结
前言
在过去的一个月中,我们进行了面向对象第一单元的学习。第一单元是面向对象课程的一个基础阶段,主要是为了培养我们的对“对象”的认识,从以往的面向过程的思维中跳出来。第一单元的作业内容是多项式展开,包含了三次难度递增的编程任务,如今第一单元已经结束,我来总结一下这一阶段的收获。首先我会介绍这一单元作业的总体设计思路,对于每次作业,阐述具体的架构与代码实现,解释每个类的设计考虑,并展示类的OO度量与整个项目的类图。之后对我自己每次作业出现的bug与hack的别人的bug作简要说明。最后是对于本单元作业的自我点评与心得体会。
1. 设计思路
1.1 表达式分析:递归下降分析法
本单元作业总体任务是对一个表达式作括号展开。从一开始只含有幂函数的单变量表达式,到包含自定义函数,求和函数与三角函等的复杂表达式的展开,难度层层递进,也就是说我们的每次作业是在上一次作业的基础上作迭代开发,所以最开始的设计思路就显得尤为重要。
在我看到第一次作业指导书中的形式化表述一节时,我第一个想到的是递归下降分析法。这个形式化表述就相当于表达式的文法,现在要对表达式进行解析,我观察了一下,文法的结构并不复杂,可以很容易地对每个句型进行最左推导获得我所需要的表达式。而且直接对文法进行分析可以无视诸多限制,只要形式化表述不变,代码的整体结构就完全不需要调整。比如第一次作业指导书中写明输入表达式中至多包含1层括号,但大家都懂后面的作业肯定会允许多层括号,但是这个条件只是人为增加的限制,对形式化表述没有影响,那就不需要考虑。
确定了方法,接下来就要对文法进行简单的处理。以第一次作业为例,文法如下:
E --> B [(+|-) B] T B | E (+|-) B T B
T --> [(+|-) B] F | T B * B F
F --> V | C | X
X --> '(' E ')' [ B P ]
V --> 'x' [ B P ]
P --> '**' B C
C --> [(+|-)] (0|1|2|3|4|5|6|7|8|9) {0|1|2|3|4|5|6|7|8|9}
B --> { ' ' | '\t' }
* E:表达式
* T:项
* F:因子
* B:空白项
* C:常数因子/带符号整数
* V:变量因子/幂函数
* X:表达式因子
* P:指数
后续几次作业只是加了一些句型,本质上没有太大差别,依然可以构造一个文法作类似的分析。
比如第三次作业文法:
* E --> B [(+|-) B] T B | E (+|-) B T B
* T --> [(+|-)B] F | T B * B F
* F --> V | C | X
* V --> M | △ | D | ∑
* C --> [+|-] □
* X --> '(' E ')' [ B Z ]
* M --> ( I | 'i' ) [ B Z ]
* △ --> 'sin' B '(' B F B ')' [ B Z ] | 'cos' B '(' B F B ')' [ B Z ]
* Z --> '**' B [+] □
* □ --> (0|1|2|3|4|5|6|7|8|9) {0|1|2|3|4|5|6|7|8|9}
* B --> { ' ' | '\t' }
* U --> N B ( B I B [ ',' B I B [ ',' B I B ]]) B '=' B Ue
* I --> 'x' | 'y' | 'z'
* D --> N B ( B F B [ ',' B F B [ ',' B F B ]])
* N --> 'f' | 'g' | 'h'
* ∑ --> 'sum' '(' B 'i' B ',' B C B ',' B C B ',' B ∑e B ')'
* Ue --> E
* ∑e --> F
*
* X: 表达式因子
* Z: 指数
* M: 幂函数
* △: 三角函数
* D: 自定义函数调用
* ∑: 求和函数
* I: 函数自变量
* U: 自定义函数定义
* N: 自定义函数名
* Ue: 函数表达式
* ∑e: 求和表达式
*
在自顶向下分析法中有两点需要注意:
-
不允许出现左递归:
在本文法中表达式和项这两个句型出现了左递归:
E --> B [(+|-) B] T B | E (+|-) B T B T --> [(+|-)B] F | T B * B F须先消除左递归,将以上文法规则修改为:
* E --> B [ (+|-) B ] T B E' * E' --> (+|-) B T B E' | ε * T --> [ (+|-) B ] F T' * T' --> B * B F T' | ε其中
ε为空。 -
回溯问题
简单来说就是每次推导必须选择一个确定的非终结符分支,但是如果两个非终结符的串首终结符相同(
first集有重合)就无法确定走哪一个分支,只能继续往后读直到确定一个分支进入。不过幸运的是,本单元的文法只有两个非常简单的回溯:
- 对于终结符
*,无法得知是连接因子的乘运算还是指数运算,必须再往后读取一个字符,若下一个字符还是*那就是指数运算,否则为乘。 - 对于第三次作业出现的求和函数
sum和三角函数sin,也是需要读入两个字符才能确定分支选择。
- 对于终结符
解决了以上两个问题,本次作业的表达式分析就基本完成了。后续只需对每个非终结符建立分析类,按照读入的终结符确定推导的分支即可。
1.2 括号展开与化简
括号展开的运算遵循指导书的基准思路,就不过多赘述。对于化简部分,说实话我在三次作业中做的都不是很好,先说一下思路:
- 在对表达式进行一遍分析之后,对括号进行展开运算获得未化简的结果。
- 此时非常数的因子的存储方式为底与指数, 常数因子只存常数。
- 对于项,用
HashMap存储非常数因子,key是因子的底,value是因子的指数。每存入一个非常数因子就对比现有key集合,如果底已经存在,那么把指数相加。常数因子直接相乘,存为单独的变量(系数),独立于HashMap之外。 - 对于表达式,用
HashMap存储非常数项,key是项中的HashMap,value是项的系数。当key一致时,value相加。
2.作业分析
2.1 第一次作业
2.1.1 代码实现
由于选课较晚,我加入课程仓库时距离第一次作业截止仅剩下不到两天时间,这之中还有一个白天用来设计架构,真正用来写的时间比较紧张,仓促之下本次作业的代码十分的粗糙,仅对三个层次进行抽象:表达式,项和因子。我没有选择用正则表达式进行匹配,而是使用逐字符的读取方式,没有设置专门的类,将这一功能直接整合在其他类中,整体而言就是非常面向过程。最后提交的版本是未化简的版本,本身是有化简的但是交上去有一个点一直没过所以只能交未化简的版本了
值得一提的是,对于消除过左递归的文法比如:
* E --> B [ (+|-) B ] T B E'
* E' --> (+|-) B T B E' | ε
我使用内部类来实现该功能。在Exp类中存在内部类ExpandExp,它可以访问外部类Exp的变量和调用外部类的方法。在ExpandExp类中,如果读取到+或-则进行分析,否则代表该非终结符指向ε,直接跳过。
2.1.2 OO度量与类图
类复杂度:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Calculate | 4.33 | 5 | 13 |
| Exp | 1.71 | 6 | 29 |
| Exp.ExpandExp | 5 | 5 | 5 |
| Factor | 2.82 | 15 | 48 |
| Main | 6 | 6 | 6 |
| Term | 1.62 | 4 | 21 |
| Term.ExpandTerm | 5 | 5 | 5 |
方法复杂度:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Calculate.expMultiply(Exp,Exp) | 3 | 1 | 3 | 3 |
| Calculate.expMultiply(Term,Factor) | 7 | 1 | 5 | 5 |
| Calculate.expandTerm(Term) | 10 | 4 | 5 | 6 |
| Exp.Exp() | 0 | 1 | 1 | 1 |
| Exp.Exp(ArrayList |
0 | 1 | 1 | 1 |
| Exp.Exp(String) | 0 | 1 | 1 | 1 |
| Exp.Exp(String,int,char) | 0 | 1 | 1 | 1 |
| Exp.ExpandExp.analyseExpandExp() | 10 | 1 | 4 | 8 |
| Exp.addTerm(ArrayList |
0 | 1 | 1 | 1 |
| Exp.addTerm(Term) | 0 | 1 | 1 | 1 |
| Exp.analyseExp() | 11 | 1 | 5 | 10 |
| Exp.getCh() | 0 | 1 | 1 | 1 |
| Exp.getExp() | 0 | 1 | 1 | 1 |
| Exp.getIndex() | 0 | 1 | 1 | 1 |
| Exp.getNextChar() | 3 | 2 | 1 | 4 |
| Exp.getTermList() | 0 | 1 | 1 | 1 |
| Exp.hasParentheses() | 6 | 4 | 3 | 4 |
| Exp.isEnd() | 0 | 1 | 1 | 1 |
| Exp.setExp(String) | 0 | 1 | 1 | 1 |
| Exp.setter(Term) | 0 | 1 | 1 | 1 |
| Exp.toString() | 1 | 1 | 2 | 2 |
| Factor.Factor() | 0 | 1 | 1 | 1 |
| Factor.Factor(Exp) | 0 | 1 | 1 | 1 |
| Factor.Factor(String) | 0 | 1 | 1 | 1 |
| Factor.Factor(String,Exp) | 0 | 1 | 1 | 1 |
| Factor.Factor(String,int,char) | 0 | 1 | 1 | 1 |
| Factor.analyseConst() | 7 | 1 | 6 | 7 |
| Factor.analyseExpFactor() | 62 | 1 | 17 | 21 |
| Factor.analyseFactor() | 4 | 1 | 6 | 6 |
| Factor.analysePower() | 7 | 1 | 4 | 5 |
| Factor.analyseVar() | 16 | 1 | 6 | 8 |
| Factor.getCh() | 0 | 1 | 1 | 1 |
| Factor.getExp() | 0 | 1 | 1 | 1 |
| Factor.getFactor() | 0 | 1 | 1 | 1 |
| Factor.getIndex() | 0 | 1 | 1 | 1 |
| Factor.getNextChar() | 3 | 2 | 1 | 4 |
| Factor.isEnd() | 0 | 1 | 1 | 1 |
| Factor.toString() | 0 | 1 | 1 | 1 |
| Main.main(String[]) | 14 | 5 | 6 | 6 |
| Term.ExpandTerm.analyseExpandTerm() | 9 | 1 | 5 | 8 |
| Term.Term() | 0 | 1 | 1 | 1 |
| Term.Term(Factor) | 0 | 1 | 1 | 1 |
| Term.Term(String,int,char,boolean) | 1 | 1 | 2 | 2 |
| Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| Term.analyseTerm() | 7 | 1 | 4 | 6 |
| Term.getCh() | 0 | 1 | 1 | 1 |
| Term.getFactorList() | 0 | 1 | 1 | 1 |
| Term.getIndex() | 0 | 1 | 1 | 1 |
| Term.getNextChar() | 3 | 2 | 1 | 4 |
| Term.isEnd() | 0 | 1 | 1 | 1 |
| Term.multiTerm(Term) | 0 | 1 | 1 | 1 |
| Term.setter(Factor) | 0 | 1 | 1 | 1 |
| Term.toString() | 1 | 1 | 2 | 2 |
复杂度较高的几个方法中无一例外使用了多重循环与嵌套,尤其是Factor.analyseExpFactor()方法,由于调用了Exp类,再加上括号展开的计算,其复杂度直接爆炸。
类图:
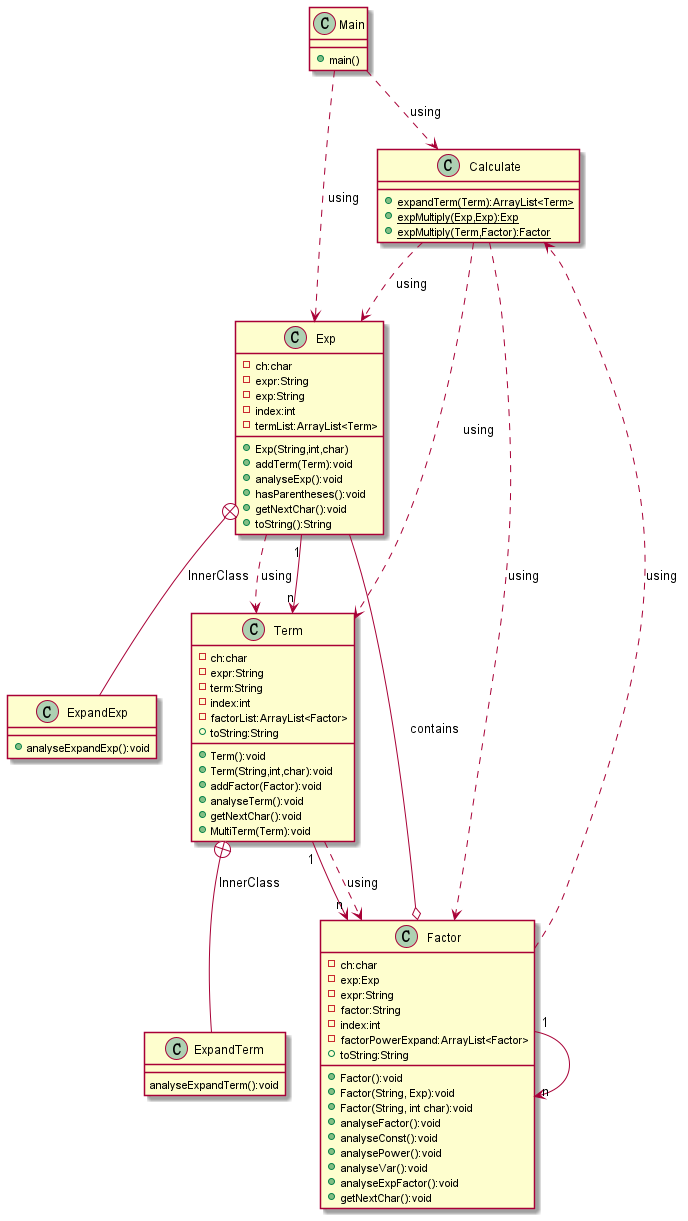
第一次作业中类的关系较为简单:
读入字符串后,送入Exp类进行分析,最终得到一个表达式类。Calculate类中包含静态方法,用来计算括号展开式。括号展开的有关计算被直接放在Main中。Factor中还包含指数展开方法,就是将带指数的因子存成ArrayList,再使用calculate方法进行计算得到一个不含指数的表达式因子。
2.2 第二次作业
2.2.1 代码实现
本次作业有了充足的时间去构造代码,在第一次作业的基础上,我定义了一个读字符类ReadChar():
public class ReadChar {
private String expr; //课程组程序读入的一行字符串
private char ch; //读取的字符
private int index = 0; //当前字符所在索引,初值为0
private boolean end = false; //是否结束
...
}
类中定义读字符函数
private void getNextChar() {
......
ch = expr.charAt(index); // 读取字符串在index处的字符ch
index++;
if (index == expr.length()) {
end = true;
}
......
}
每读入一个字符,确定下一个转移状态。为了回溯,类中定义了临时变量与存储方法:
private int tmpIndex; //存储当前index
private char tmpCh; //存储当前字符
private boolean nowEnd; //确认当前是否已经读完字符串
public void flag() { //在回溯时调用,存档回溯点
tmpIndex = index;
tmpCh = ch;
nowEnd = end;
}
public void recall() { //回溯完成调用,回到上一个存档点
index = tmpIndex;
ch = tmpCh;
end = nowEnd;
}
本次作业对代码结构进行了优化,将同一目标的类放在一个包下,更方便管理。
新增自定义函数,三角函数与求和函数,在设计思路部分就已阐明,原理上一致,只是在文法上添加了新的句型,体现在代码层面就是需要建立新的类以及依赖关系。
其中最需要注意的就是三角函数,由于其自带括号,在计算括号展开式时会造成影响,因此我将三角函数的括号用其他字符替换:
'(' --> '#'
')' --> '%'
这样在最后进行括号展开时就不会被干扰,获取到最终结果后再将其替换即可。
result = result.replaceAll("#", "(");
result = result.replaceAll("%", ")");
对于自定义函数,我用一个HashMap将形参与实参联系起来,并在函数调用时进行替换,替换之后的表达式再送入Exp类中进行分析。
求和函数就更简单了,直接一个for循环展开,先给他算完再进行优化。
这里其实已经有点问题了,之前研讨课也有同学分享过,先计算再优化的情况下很容易导致RTE,事实也确实如此,所以后面在改bug时我改成了只要出现一次Exp或Term就调用一次化简函数,保证每次进行计算时都是当前最简的形式。
我认为这一次作业最坑的地方就是三角函数中不能是表达式,只能是因子,如果有表达式就必须用括号括起来才行。这个问题也好解决,就是在上述替换特殊字符的时候多加一层括号就好了。在这之前的括号展开已经保证了这个表达式不会含有任何括号(三角函数的括号此时还是特殊字符),因此可以简单地把特殊字符替换为两个相连的括号。
result = result.replaceAll("#", "((");
result = result.replaceAll("%", "))");
下面结合类图来进行分析。
2.2.2 OO度量与类图
复杂度分析如下:
类复杂度:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Main | 8 | 8 | 8 |
| base.Blank | 1.25 | 2 | 5 |
| base.Const | 1.4 | 3 | 7 |
| base.Exp | 1.55 | 4 | 17 |
| base.Exp.ExpandExp | 2 | 3 | 4 |
| base.Power | 1.6 | 4 | 8 |
| base.Term | 1.67 | 4 | 15 |
| base.Term.ExpandTerm | 3 | 3 | 3 |
| calculate.Calculate | 3.17 | 5 | 19 |
| cusfunc.CusFuncDef | 1.33 | 3 | 8 |
| cusfunc.CusFuncExp | 1 | 1 | 5 |
| factor.ConstFac | 1.4 | 3 | 7 |
| factor.ExpFac | 1.86 | 7 | 13 |
| factor.Factor | 1.88 | 8 | 15 |
| factor.VarFac | 2 | 7 | 12 |
| factor.var.CusFuncCall | 1.43 | 3 | 10 |
| factor.var.PowerFunc | 1.2 | 2 | 6 |
| factor.var.SumFunc | 1.29 | 3 | 9 |
| factor.var.TriFunc | 3.33 | 9 | 20 |
| input.ReadChar | 1.21 | 4 | 17 |
方法复杂度:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Main.main(String[]) | 17 | 5 | 9 | 9 |
| base.Blank.Blank() | 0 | 1 | 1 | 1 |
| base.Blank.Blank(ReadChar) | 0 | 1 | 1 | 1 |
| base.Blank.analyseBlank() | 2 | 1 | 3 | 3 |
| base.Blank.getReadChar() | 0 | 1 | 1 | 1 |
| base.Const.Const() | 0 | 1 | 1 | 1 |
| base.Const.Const(ReadChar) | 0 | 1 | 1 | 1 |
| base.Const.analyseConst() | 3 | 1 | 3 | 3 |
| base.Const.getConstZero() | 0 | 1 | 1 | 1 |
| base.Const.getReadChar() | 0 | 1 | 1 | 1 |
| base.Exp.Exp() | 0 | 1 | 1 | 1 |
| base.Exp.Exp(ArrayList |
0 | 1 | 1 | 1 |
| base.Exp.Exp(ReadChar) | 0 | 1 | 1 | 1 |
| base.Exp.ExpandExp.ExpandExp() | 0 | 1 | 1 | 1 |
| base.Exp.ExpandExp.analyseExpandExp() | 4 | 1 | 3 | 4 |
| base.Exp.addTerm(ArrayList |
0 | 1 | 1 | 1 |
| base.Exp.addTerm(Term) | 0 | 1 | 1 | 1 |
| base.Exp.analyseExp() | 4 | 1 | 3 | 4 |
| base.Exp.getExp() | 0 | 1 | 1 | 1 |
| base.Exp.getReadChar() | 0 | 1 | 1 | 1 |
| base.Exp.getTermList() | 0 | 1 | 1 | 1 |
| base.Exp.hasParentheses() | 6 | 4 | 3 | 4 |
| base.Exp.toString() | 1 | 1 | 2 | 2 |
| base.Power.Power() | 0 | 1 | 1 | 1 |
| base.Power.Power(ReadChar) | 0 | 1 | 1 | 1 |
| base.Power.analysePower() | 7 | 3 | 4 | 4 |
| base.Power.getPower() | 0 | 1 | 1 | 1 |
| base.Power.getReadChar() | 0 | 1 | 1 | 1 |
| base.Term.ExpandTerm.analyseExpandTerm() | 3 | 1 | 4 | 4 |
| base.Term.Term() | 0 | 1 | 1 | 1 |
| base.Term.Term(Factor) | 0 | 1 | 1 | 1 |
| base.Term.Term(ReadChar,boolean) | 1 | 1 | 2 | 2 |
| base.Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| base.Term.analyseTerm() | 4 | 1 | 4 | 4 |
| base.Term.getFactorList() | 0 | 1 | 1 | 1 |
| base.Term.getReadChar() | 0 | 1 | 1 | 1 |
| base.Term.multiTerm(Term) | 0 | 1 | 1 | 1 |
| base.Term.toString() | 6 | 4 | 6 | 8 |
| calculate.Calculate.expMultiply(Exp,Exp) | 5 | 2 | 5 | 5 |
| calculate.Calculate.expMultiply(Term,Factor) | 7 | 1 | 5 | 5 |
| calculate.Calculate.expandTerm(Term) | 10 | 4 | 5 | 6 |
| calculate.Calculate.getCusFuncDef() | 0 | 1 | 1 | 1 |
| calculate.Calculate.isNumber(String) | 3 | 3 | 2 | 3 |
| calculate.Calculate.setCusFuncDef(CusFuncDef) | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.CusFuncDef() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.CusFuncDef(ReadChar) | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.analyseCusFuncDef(ReadChar) | 3 | 1 | 3 | 3 |
| cusfunc.CusFuncDef.getName2ExpMap() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.getName2FormalMap() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.getReadChar() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.CusFuncExp() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.CusFuncExp(ReadChar) | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.analyseCusFuncExp() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.getExp() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.getReadChar() | 0 | 1 | 1 | 1 |
| factor.ConstFac.ConstFac() | 0 | 1 | 1 | 1 |
| factor.ConstFac.ConstFac(ReadChar) | 0 | 1 | 1 | 1 |
| factor.ConstFac.analyseConstFac() | 5 | 1 | 6 | 6 |
| factor.ConstFac.getConstFac() | 0 | 1 | 1 | 1 |
| factor.ConstFac.getReadChar() | 0 | 1 | 1 | 1 |
| factor.ExpFac.ExpFac() | 0 | 1 | 1 | 1 |
| factor.ExpFac.ExpFac(Exp) | 0 | 1 | 1 | 1 |
| factor.ExpFac.ExpFac(ReadChar) | 0 | 1 | 1 | 1 |
| factor.ExpFac.analyseExpFac() | 9 | 1 | 7 | 7 |
| factor.ExpFac.getExp() | 0 | 1 | 1 | 1 |
| factor.ExpFac.getExpFac() | 0 | 1 | 1 | 1 |
| factor.ExpFac.getReadChar() | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(ExpFac) | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(ReadChar) | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(String) | 0 | 1 | 1 | 1 |
| factor.Factor.analyseFactor() | 11 | 1 | 16 | 16 |
| factor.Factor.getExpFac() | 0 | 1 | 1 | 1 |
| factor.Factor.getFactor() | 0 | 1 | 1 | 1 |
| factor.Factor.getReadChar() | 0 | 1 | 1 | 1 |
| factor.Factor.toString() | 0 | 1 | 1 | 1 |
| factor.VarFac.VarFac() | 0 | 1 | 1 | 1 |
| factor.VarFac.VarFac(ReadChar) | 0 | 1 | 1 | 1 |
| factor.VarFac.analyseVar() | 9 | 1 | 12 | 12 |
| factor.VarFac.getExpFac() | 0 | 1 | 1 | 1 |
| factor.VarFac.getReadChar() | 0 | 1 | 1 | 1 |
| factor.VarFac.getVarFac() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.CusFuncCall() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.CusFuncCall(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.analyseCusFuncCall() | 3 | 1 | 3 | 3 |
| factor.var.CusFuncCall.getCusFuncCall() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.getExp() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.getFuncExp() | 1 | 1 | 2 | 2 |
| factor.var.CusFuncCall.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.PowerFunc() | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.PowerFunc(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.analysePowerFunc() | 2 | 1 | 5 | 5 |
| factor.var.PowerFunc.getPowerFunc() | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.SumFunc() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.SumFunc(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.analyseSumFunc() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.getExp() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.getSumExp() | 4 | 1 | 3 | 3 |
| factor.var.SumFunc.getSumFunc() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.TriFunc() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.TriFunc(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.analyseTriFunc() | 16 | 1 | 11 | 11 |
| factor.var.TriFunc.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.getTriFunc() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.paraExpansion(Factor) | 20 | 6 | 7 | 7 |
| input.ReadChar.ReadChar() | 0 | 1 | 1 | 1 |
| input.ReadChar.ReadChar(String) | 0 | 1 | 1 | 1 |
| input.ReadChar.ReadChar(String,int,char,boolean) | 0 | 1 | 1 | 1 |
| input.ReadChar.flag() | 0 | 1 | 1 | 1 |
| input.ReadChar.getCh() | 0 | 1 | 1 | 1 |
| input.ReadChar.getExpr() | 0 | 1 | 1 | 1 |
| input.ReadChar.getIndex() | 0 | 1 | 1 | 1 |
| input.ReadChar.getNextChar() | 3 | 2 | 1 | 4 |
| input.ReadChar.isEnd() | 0 | 1 | 1 | 1 |
| input.ReadChar.recall() | 0 | 1 | 1 | 1 |
| input.ReadChar.setCh(char) | 0 | 1 | 1 | 1 |
| input.ReadChar.setEnd(boolean) | 0 | 1 | 1 | 1 |
| input.ReadChar.setExpr(String) | 0 | 1 | 1 | 1 |
| input.ReadChar.setIndex(int) | 0 | 1 | 1 | 1 |
可以很明显地看出第二次作业的复杂度显著降低,除了计算展开式需要多次循环之外,其他方法中循环与递归调用的情况得到改善,一方面因为类的分布更加合理,各司其职耦合度大大降低,另一方面优化了算法,尽量降低循环使用次数(然后多了很多if语句。。好像也有点不太合适的样子)。
类图:
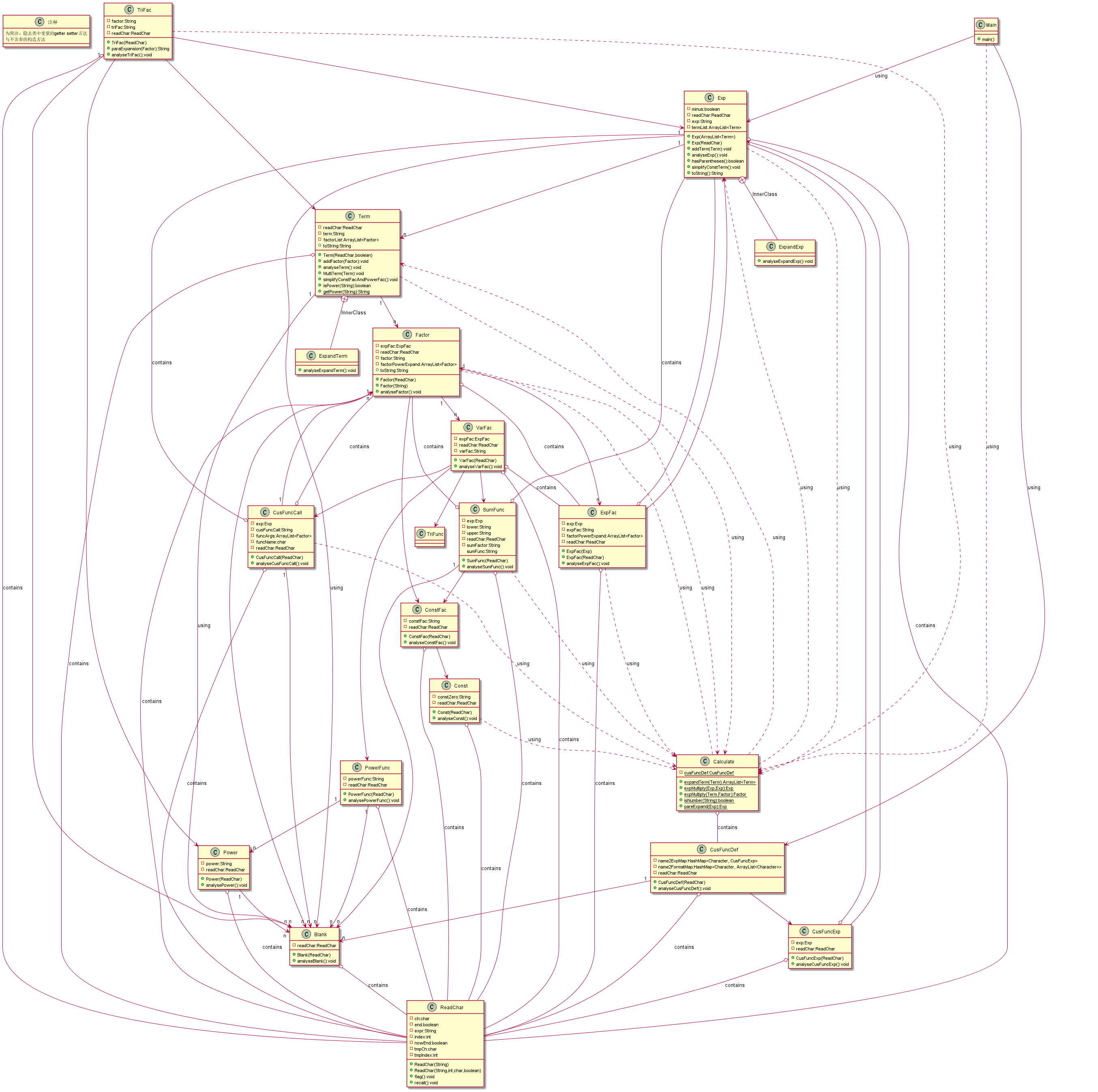
本次作业的结构是复杂了许多,但是脉络非常清晰,就是根据形式化表述将每一个非终结符都抽象成一个类,这一次作业相对于我最初的设计思路来说完成度非常高,基本实现了我预想的情况。这里其实还可以作一个优化:应用工厂模式。将Factor写成一个接口,其他几个类实现这个接口,在具体的识别过程中直接将字符串扔进Factor让它去判断应该送入哪一个类存储。
2.3 第三次作业
2.3.1 代码实现
正如我在设计思路中讲的,第三次作业中形式化表述没有改变,因此我直接用第二次作业的程序提交都没有太大问题。
啊当然还是有一些问题的,输出字符串的长度还需优化,加上多层括号的嵌套之后还用我之前的方法,长度方面难以控制。最终我还是尽力优化了指性能分加起来不超过5
还有一点,我将三角函数文法中的因子全部替换成了表达式,因为在消除括号之后我总会在三角函数中增加一层括号将其中字符串变为表达式因子,所以为了在中间过程识别方便,就直接套用表达式,本次作业没有Wrong Format因此本方法可行。
2.3.2 OO度量与类图
类复杂度如下:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Main | 3 | 3 | 3 |
| base.Blank | 1.25 | 2 | 5 |
| base.Const | 1.4 | 3 | 7 |
| base.Exp | 1.92 | 4 | 23 |
| base.Exp.ExpandExp | 2 | 3 | 4 |
| base.Power | 1.6 | 4 | 8 |
| base.Term | 2 | 8 | 32 |
| base.Term.ExpandTerm | 3 | 3 | 3 |
| calculate.Calculate | 3.29 | 6 | 23 |
| cusfunc.CusFuncDef | 1.33 | 3 | 8 |
| cusfunc.CusFuncExp | 1 | 1 | 5 |
| factor.ConstFac | 1.4 | 3 | 7 |
| factor.ExpFac | 1.86 | 7 | 13 |
| factor.Factor | 1.82 | 8 | 20 |
| factor.VarFac | 2 | 7 | 12 |
| factor.var.CusFuncCall | 1.43 | 3 | 10 |
| factor.var.PowerFunc | 1.6 | 4 | 8 |
| factor.var.SumFunc | 1.29 | 3 | 9 |
| factor.var.TriFunc | 2.83 | 11 | 17 |
| input.ReadChar | 1.21 | 4 | 17 |
方法复杂度如下:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Main.main(String[]) | 3 | 1 | 4 | 4 |
| base.Blank.Blank() | 0 | 1 | 1 | 1 |
| base.Blank.Blank(ReadChar) | 0 | 1 | 1 | 1 |
| base.Blank.analyseBlank() | 2 | 1 | 3 | 3 |
| base.Blank.getReadChar() | 0 | 1 | 1 | 1 |
| base.Const.Const() | 0 | 1 | 1 | 1 |
| base.Const.Const(ReadChar) | 0 | 1 | 1 | 1 |
| base.Const.analyseConst() | 3 | 1 | 3 | 3 |
| base.Const.getConstZero() | 0 | 1 | 1 | 1 |
| base.Const.getReadChar() | 0 | 1 | 1 | 1 |
| base.Exp.Exp() | 0 | 1 | 1 | 1 |
| base.Exp.Exp(ArrayList |
0 | 1 | 1 | 1 |
| base.Exp.Exp(ReadChar) | 0 | 1 | 1 | 1 |
| base.Exp.ExpandExp.ExpandExp() | 0 | 1 | 1 | 1 |
| base.Exp.ExpandExp.analyseExpandExp() | 4 | 1 | 3 | 4 |
| base.Exp.addTerm(ArrayList |
0 | 1 | 1 | 1 |
| base.Exp.addTerm(Term) | 0 | 1 | 1 | 1 |
| base.Exp.analyseExp() | 5 | 1 | 4 | 5 |
| base.Exp.getExp() | 0 | 1 | 1 | 1 |
| base.Exp.getReadChar() | 0 | 1 | 1 | 1 |
| base.Exp.getTermList() | 0 | 1 | 1 | 1 |
| base.Exp.hasParentheses() | 6 | 4 | 3 | 4 |
| base.Exp.simplifyConstTerm() | 6 | 1 | 5 | 5 |
| base.Exp.toString() | 3 | 3 | 2 | 3 |
| base.Power.Power() | 0 | 1 | 1 | 1 |
| base.Power.Power(ReadChar) | 0 | 1 | 1 | 1 |
| base.Power.analysePower() | 7 | 3 | 4 | 4 |
| base.Power.getPower() | 0 | 1 | 1 | 1 |
| base.Power.getReadChar() | 0 | 1 | 1 | 1 |
| base.Term.ExpandTerm.analyseExpandTerm() | 3 | 1 | 4 | 4 |
| base.Term.Term() | 0 | 1 | 1 | 1 |
| base.Term.Term(Factor) | 0 | 1 | 1 | 1 |
| base.Term.Term(ReadChar) | 0 | 1 | 1 | 1 |
| base.Term.Term(ReadChar,boolean) | 1 | 1 | 2 | 2 |
| base.Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| base.Term.analyseTerm() | 4 | 1 | 4 | 4 |
| base.Term.equals(Object) | 3 | 3 | 2 | 4 |
| base.Term.getFactorList() | 0 | 1 | 1 | 1 |
| base.Term.getPower(String) | 2 | 2 | 2 | 2 |
| base.Term.getReadChar() | 0 | 1 | 1 | 1 |
| base.Term.hashCode() | 0 | 1 | 1 | 1 |
| base.Term.isPower(String) | 0 | 1 | 1 | 1 |
| base.Term.multiTerm(Term) | 3 | 3 | 3 | 3 |
| base.Term.setFactorList(ArrayList |
0 | 1 | 1 | 1 |
| base.Term.simplifyConstFacAndPowerFac() | 10 | 1 | 9 | 9 |
| base.Term.toString() | 1 | 1 | 2 | 2 |
| calculate.Calculate.expMultiply(Exp,Exp) | 5 | 2 | 5 | 5 |
| calculate.Calculate.expMultiply(Term,Factor) | 7 | 1 | 5 | 5 |
| calculate.Calculate.expandTerm(Term) | 10 | 4 | 5 | 6 |
| calculate.Calculate.getCusFuncDef() | 0 | 1 | 1 | 1 |
| calculate.Calculate.isNumber(String) | 0 | 1 | 1 | 1 |
| calculate.Calculate.pareExpand(Exp) | 14 | 5 | 6 | 6 |
| calculate.Calculate.setCusFuncDef(CusFuncDef) | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.CusFuncDef() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.CusFuncDef(ReadChar) | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.analyseCusFuncDef(ReadChar) | 3 | 1 | 3 | 3 |
| cusfunc.CusFuncDef.getName2ExpMap() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.getName2FormalMap() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncDef.getReadChar() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.CusFuncExp() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.CusFuncExp(ReadChar) | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.analyseCusFuncExp() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.getExp() | 0 | 1 | 1 | 1 |
| cusfunc.CusFuncExp.getReadChar() | 0 | 1 | 1 | 1 |
| factor.ConstFac.ConstFac() | 0 | 1 | 1 | 1 |
| factor.ConstFac.ConstFac(ReadChar) | 0 | 1 | 1 | 1 |
| factor.ConstFac.analyseConstFac() | 5 | 1 | 6 | 6 |
| factor.ConstFac.getConstFac() | 0 | 1 | 1 | 1 |
| factor.ConstFac.getReadChar() | 0 | 1 | 1 | 1 |
| factor.ExpFac.ExpFac() | 0 | 1 | 1 | 1 |
| factor.ExpFac.ExpFac(Exp) | 0 | 1 | 1 | 1 |
| factor.ExpFac.ExpFac(ReadChar) | 0 | 1 | 1 | 1 |
| factor.ExpFac.analyseExpFac() | 9 | 1 | 7 | 7 |
| factor.ExpFac.getExp() | 0 | 1 | 1 | 1 |
| factor.ExpFac.getExpFac() | 0 | 1 | 1 | 1 |
| factor.ExpFac.getReadChar() | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(ExpFac) | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(ReadChar) | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(String) | 0 | 1 | 1 | 1 |
| factor.Factor.Factor(String,BigInteger) | 0 | 1 | 1 | 1 |
| factor.Factor.analyseFactor() | 11 | 1 | 16 | 16 |
| factor.Factor.equals(Object) | 3 | 3 | 2 | 4 |
| factor.Factor.getExpFac() | 0 | 1 | 1 | 1 |
| factor.Factor.getFactor() | 0 | 1 | 1 | 1 |
| factor.Factor.getReadChar() | 0 | 1 | 1 | 1 |
| factor.Factor.hashCode() | 0 | 1 | 1 | 1 |
| factor.Factor.toString() | 0 | 1 | 1 | 1 |
| factor.VarFac.VarFac() | 0 | 1 | 1 | 1 |
| factor.VarFac.VarFac(ReadChar) | 0 | 1 | 1 | 1 |
| factor.VarFac.analyseVar() | 9 | 1 | 12 | 12 |
| factor.VarFac.getExpFac() | 0 | 1 | 1 | 1 |
| factor.VarFac.getReadChar() | 0 | 1 | 1 | 1 |
| factor.VarFac.getVarFac() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.CusFuncCall() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.CusFuncCall(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.analyseCusFuncCall() | 3 | 1 | 3 | 3 |
| factor.var.CusFuncCall.getCusFuncCall() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.getExp() | 0 | 1 | 1 | 1 |
| factor.var.CusFuncCall.getFuncExp() | 1 | 1 | 2 | 2 |
| factor.var.CusFuncCall.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.PowerFunc() | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.PowerFunc(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.analysePowerFunc() | 5 | 4 | 6 | 7 |
| factor.var.PowerFunc.getPowerFunc() | 0 | 1 | 1 | 1 |
| factor.var.PowerFunc.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.SumFunc() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.SumFunc(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.analyseSumFunc() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.getExp() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.SumFunc.getSumExp() | 4 | 1 | 3 | 3 |
| factor.var.SumFunc.getSumFunc() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.TriFunc() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.TriFunc(ReadChar) | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.analyseTriFunc() | 18 | 3 | 12 | 13 |
| factor.var.TriFunc.getReadChar() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.getTriFunc() | 0 | 1 | 1 | 1 |
| factor.var.TriFunc.paraExpansion(Factor) | 1 | 2 | 2 | 2 |
| input.ReadChar.ReadChar() | 0 | 1 | 1 | 1 |
| input.ReadChar.ReadChar(String) | 0 | 1 | 1 | 1 |
| input.ReadChar.ReadChar(String,int,char,boolean) | 0 | 1 | 1 | 1 |
| input.ReadChar.flag() | 0 | 1 | 1 | 1 |
| input.ReadChar.getCh() | 0 | 1 | 1 | 1 |
| input.ReadChar.getExpr() | 0 | 1 | 1 | 1 |
| input.ReadChar.getIndex() | 0 | 1 | 1 | 1 |
| input.ReadChar.getNextChar() | 3 | 2 | 1 | 4 |
| input.ReadChar.isEnd() | 0 | 1 | 1 | 1 |
| input.ReadChar.recall() | 0 | 1 | 1 | 1 |
| input.ReadChar.setCh(char) | 0 | 1 | 1 | 1 |
| input.ReadChar.setEnd(boolean) | 0 | 1 | 1 | 1 |
| input.ReadChar.setExpr(String) | 0 | 1 | 1 | 1 |
| input.ReadChar.setIndex(int) | 0 | 1 | 1 | 1 |
可以看出除了包含循环的计算类,其他类的复杂度控制的都还可以。
类图:
同第二次作业,我没有新添加任何类或方法,只是修改了原有方法中的一些算法。

3 Bug and Hack
第一次作业由于没有优化导致我的性能分惨不忍睹,但是好歹中测强测都AC, 也没有发现bug。在互测时我的思路也非常直接,我选择用非常简单的表达式:比如(002632426151125325132500)**(000000)测试一些容易忽略的地方因为我自己的优化都没做好所以也不敢用很长的边界数据来测最后成功hack两人,当时我觉得这些其实都是低级错误,在编程的时候稍微细心一点就可以避免发生。
一语成谶,到了第二次作业的时候我也犯了一个低级错误,甚至到最后也没检查出来,中测的最后一个点没有过。最后bug修复时查找原因,是这样的结构:(0)**0在我的函数中识别时一旦发现底为0就直接返回0,结果忘记特殊情况零的零次幂等于1我好恨啊!。本次作业没有进入互测。强测有几个输出超过了数据长度限制,是我没有优化好的结果。
为了避免这样的情况再次发生,第三次作业我测了两天,用很多数据去跑,最后结果还不错,没有发现bug,只是性能分依然很低。这和我本身的处理也有关系。我为了求稳,在三角函数的括号内又添加一层括号,也就是把括号内的所有成分一概视为表达式因子,这样做正确性得到了保证,但是遇到三角函数很多的表达式,最后的结果就会很长很长,性能分极低。
第三次作业我们房间的大家都很优秀,我用了几个边界数据去测都没有命中,好像同学们的代码都写的很好,完成度很高。
4.自我点评与心得体会
这三次作业对于我来说难度其实不是非常大,主要是体会面向对象的思想在具体问题中的应用。我在对象的设计,方法的构造以及类与类的安排上面仍有所欠缺。比如对于因子的解析,三角函数因子、幂函数因子、求和函数因子、自定义函数因子等等,里面包含一些相同的变量与方法,这时就可以将因子写成一个接口,让下面几个分支去实现,然后应用工厂模式自动识别分支进行匹配。
在代码优化方面,本单元作业我偷懒颇多。其实第二次作业在强测部分就已经有长度超过限制的情况了,不得已删减了一些冗余项,但始终无法优化到一个比较简洁的水平,说起来还是因为懒,担心写多错多不肯好好调试。
在调试方面,我的测试方法还是偏向于读代码,没有像讨论区大佬一样自动构建数据进行黑盒测试。虽然时间花的比较久,但是我认为我还是有一些收获,起码能够对于各种特殊情况和边界数据更加敏锐,说不定也是一件好事。
说点好的。本单元作业从没有出现代码风格扣分的情况,而且基本都是一遍过没有修改太多,说明整体架构做的不错。虽然具体算法细节上还需改进,但是面向对象的思维模式有了一定理解。着手写代码之前一定要先做一个完整的合理的设计,这样不容易出错,效率会提升非常多,而且编程的时候也不会像没头苍蝇一样乱撞,一会在这里加个变量一会在那里加个方法。本次作业我在每个类中都写了大量的注释,不管是写程序还是debug都有很大的帮助。
希望一个学期的学习能让我的能力更上一层楼。

