hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
问题的可解决提供方案:分布式文件系统(GFS),可用于处理海量网页的存储,分布式计算框架(MAPREDUCE),可用于处理海量网页的索引计算问题。Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
Hadoop发展:Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
(1)名称节点最主要功能:名称节点记录了每个文件中各个块所在的数据节点的位置信息,负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog。
(2)第二名称节点主要功能:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。在紧急情况下,可辅助恢复名称节点。
(3)数据节点主要功能:分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
(4)相互关系:分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群,这些节点分为主从节点,主节点可叫作名称节点,从节点可叫作数据节点。名称节点为了防止
EditLog过大的问题:引入了第二名称节点。
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
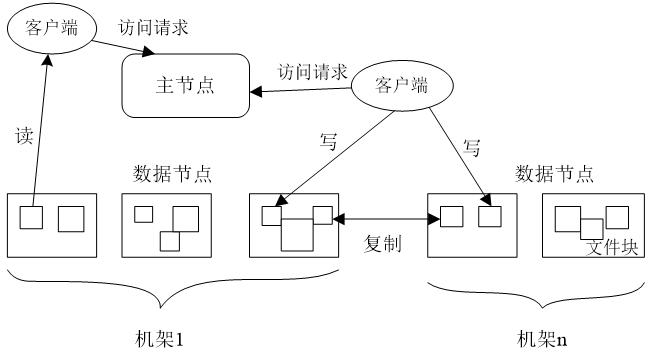
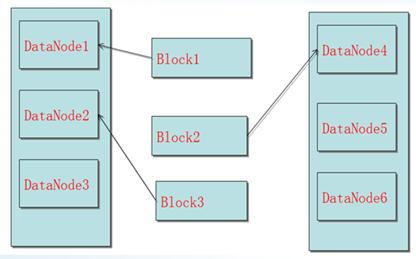
冗余数据保存
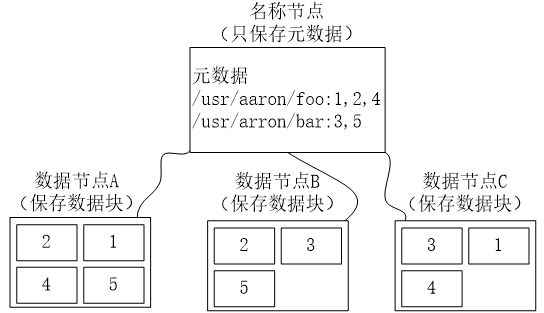
数据存储策略
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 与HDFS的关联
Master主服务器的功能:基于分而治之的思想,将一个原始任务分解为若干个语义等同的子任务,并由专门的工作者线程来并行执行这些任务,原始任务的结果是通过整合各个子任务的处理结果形成的表在行方向上,按照行健范围分成若干的Region。
每个表最初只有一个Region,当记录数增加到超过某个阈值时,开始分裂成两个Region。
物理上所有的数据存放在HDFS,由Region服务器提供region的管理。
一台物理节点只能跑一个Hregionserver.
一个region实例包括Hlog和存放数据的store。
hmaster作为总控节点
zookeeper负责调度
- Zookeeper协同的功能
分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列等功能。
例如在Hadoop中,HDFS采用了基于Master/Slave主从架构的分布式文件系统,一个HDFS集群包含一个单独的Master节点和多个Slave节点服务器,这里的一个单独的Master节点的含义是HDFS系统中只存在一个逻辑上的Master组件。一个逻辑的Master节点可以包括两台物理主机,即两台Master服务器、多台Slave服务器。一台Master服务器组成单NameNode集群,两台Master服务器组成双NameNode集群,并且同时被多个客户端访问,所有的这些机器通常都是普通的Linux机器,运行着用户级别(user-level)的服务进程.
. 客户端发起请求(Client Hello包)
a) 三次握手,建立TCP连接
b) 支持的协议版本(TLS/SSL)
c) 客户端生成的随机数client.random,后续用于生成“对话密钥”
d) 客户端支持的加密算法
e) sessionid,用于保持同一个会话(如果客户端与服务器费尽周折建立了一个HTTPS链接,刚建完就断了,也太可惜)
二、Master、RegionServer、Zookeeper、Client、Hdfs之间的关系与联系
1、Hbase集群有两种服务器:一个Master服务器和多个RegionServer服务器;
2、Master服务负责维护表结构信息和各种协调工作,比如建表、删表、移动region、合并等操作;
3、客户端获取数据是由客户端直连RegionServer的,所以Master服务挂掉之后依然可以查询、存储、删除数据,就是不能建新表了;
4、RegionServer非常依赖Zookeeper服务,Zookeeper管理Hbase所有的RegionServer信息,包括具体的数据段存放在那个RegionServer上;
5、客户端每次与Hbase连接,其实都是先于Zookeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer;客户端从Zookeeper获取了RegionServer的地址后,会直接从RegionServer获取数据;
6、RegionServer保存的数据直接存储在Hadoop的HDFS上;
5.理解并描述Hbase表与Region的关系。
6.理解并描述Hbase的三级寻址。
寻找RegionServer
ZooKeeper–> -ROOT-(单Region)–> .META.–> 用户表
-ROOT-表
表包含.META.表所在的region列表,该表只会有一个Region;
Zookeeper中记录了-ROOT-表的location。
.META.表
表包含所有的用户空间region列表,以及RegionServer的服务器地址。
7.通过HBase的三级寻址方式,理论上Hbase的数据表最大有多少个Region?
HBase中数据一开始会写入memstore,满128MB(看配置)以后,会flush到disk上而成为storefile。当storefile数量超过触发因子时(可以配置),会启动compaction过程将它们合并为一个storefile。对集群的性能有一定影响。而当合并后的storefile大于max.filesize,会触发分割动作,将它切分成两个region。
分配合理的region数量,根据写请求量的情况,一般20-200个之间
8.MapReduce的架构,各部分的功能。

MapReduce包含四个组成部分,分别为Client,JobTracker,TaskTracker,Task。
a)client客户端
每一个Job都会在用户端通过Client类将应用程序以及参数配置Configuration打包成Jar文件存储在HDFS,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask),将它们分发到各个TaskTracker服务中去执行。
b)JobTracker
JobTracker负责资源监控和作业调度。JobTracker监控所有的TaskTracker与job的健康状况,一旦发现失败,就将相应的任务转移到其它节点;同时JobTracker会跟踪任务的执行进度,资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用于可以根据自己的需要设计相应的调度器。
c)TaskTracker
TaskTracker会周期性地通过HeartBeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时执行JobTracker发送过来的命令 并执行相应的操作(如启动新任务,杀死任务等)。TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(cpu,内存等) 。一个Task获取到一个slot之后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为MapSlot和ReduceSlot两种,分别提供MapTask和ReduceTask使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
d)Task
Task分为MapTask和Reduce Task两种,均由TaskTracker启动。HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
9.MapReduce的工作过程。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号