
第4讲、揭秘大模型:理解与预测的核心机制
在人工智能高速发展的今天,大型语言模型(LLM)如ChatGPT、GPT-4、Claude等已经成为热门话题。这些模型能够理解人类语言并生成连贯、有意义的回应,背后是三个核心技术组成的基本运行机制:理解和表示单词、理解输入内容、预测输出内容。本文将深入剖析这三大核心机制,以及支撑它们的Transformer架构,并通过具体案例解释它们如何协同工作。
第一核心:如何理解和表示单词 — 词嵌入向量
大模型理解语言的第一步是将文本转换为计算机可处理的数字形式。这就是词嵌入向量(Word Embedding)的作用。
词嵌入是一种将单词映射到高维向量空间的技术。通过这种映射,语义相近的单词在向量空间中的距离也会相近。例如,"king"和"queen"的向量会比"king"和"apple"的向量更接近。
但仅有词嵌入是不够的。正如一个人认得很多字,却不一定能理解一句话的含义一样,大模型需要理解词汇在特定上下文中的含义和关系。
第二核心:如何理解输入内容 — 注意力机制
传统模型的局限
在Transformer出现之前,循环神经网络(RNN)是处理序列数据的主流模型。RNN自左向右逐词处理文本,但这种方式存在明显问题:
- 单向语义传导导致后期词汇可能"堆积"过多语义
- 难以捕捉长距离依赖关系
- 无法并行计算,影响处理效率
例如,翻译"The animal that I saw in the park last Sunday was a dog"这句话时,"animal"和"dog"之间有着紧密的关系,但在RNN中,这种长距离依赖关系难以被有效捕捉。
注意力机制的革新
注意力机制(Attention Mechanism)借鉴了人类大脑的工作方式,使模型能够"关注"输入序列中的关键部分。它通过计算注意力得分(Attention Score)或注意力权重(Attention Weight)来确定单词之间的关联度。
例如,考虑句子"I have no interest in politics":
score_1 = attention_score('I', 'no')
score_2 = attention_score('have', 'no')
score_3 = attention_score('interest', 'no')
score_4 = attention_score('in', 'no')
score_5 = attention_score('politics', 'no')
在这个例子中,"no"和"interest"之间的注意力得分(score_3)可能最高,表明在处理"no"时,模型应特别关注"interest"这个词。同样,在处理"interest"时,与"politics"和"no"的关联也会被强调。
自注意力机制:Transformer的灵魂
2017年,Google研究团队在论文《Attention Is All You Need》中提出了Transformer架构,其核心是自注意力机制(Self-Attention)。
自注意力机制的独特之处在于:输入序列中的每个词都会与同一序列中的所有词计算注意力得分,包括它自己。这使模型能够全面理解上下文,特别是对多义词的处理。
考虑以下两个句子中的"interest":
- "I have no interest in politics"(兴趣)
- "The bank charges 5% interest on loans"(利息)
人类理解这两句话时,不会逐词从左到右分析,而是自然地将"interest"与上下文中的其他词联系起来,从而确定其准确含义。自注意力机制模拟了这一过程。
技术优势
- 全局语义理解:每个词都能"看到"整个序列
- 并行计算:不依赖于序列顺序,可以高效并行处理
- 长距离依赖捕捉:不受序列长度限制,能有效处理长文本
第三核心:如何预测输出内容 — 生成机制
理解输入后,大模型如何生成回应呢?
生成过程
- 自注意力机制处理输入,形成深层语义理解
- 前馈神经网络处理这些理解,为每个可能的下一个词计算概率
- 选择概率最高的词作为输出
- 将新词添加到输入中,重复预测过程
这个迭代过程被称为"贪婪搜索"(Greedy Search)。
生成策略优化
简单的贪婪搜索可能导致生成内容偏离主题或不够连贯。为此,现代大模型采用了更复杂的生成策略:
Beam Search:不仅考虑单个词的概率,还考虑整个句子的连贯性,保留多个可能的生成路径。
例如,当生成"The weather today is..."的后续内容时:
- 贪婪搜索可能直接选择概率最高的"sunny"
- Beam Search会同时考虑"sunny and clear"、"cloudy but warm"等多个路径,最终选择整体最优的一条
大模型完整工作流程:案例分析
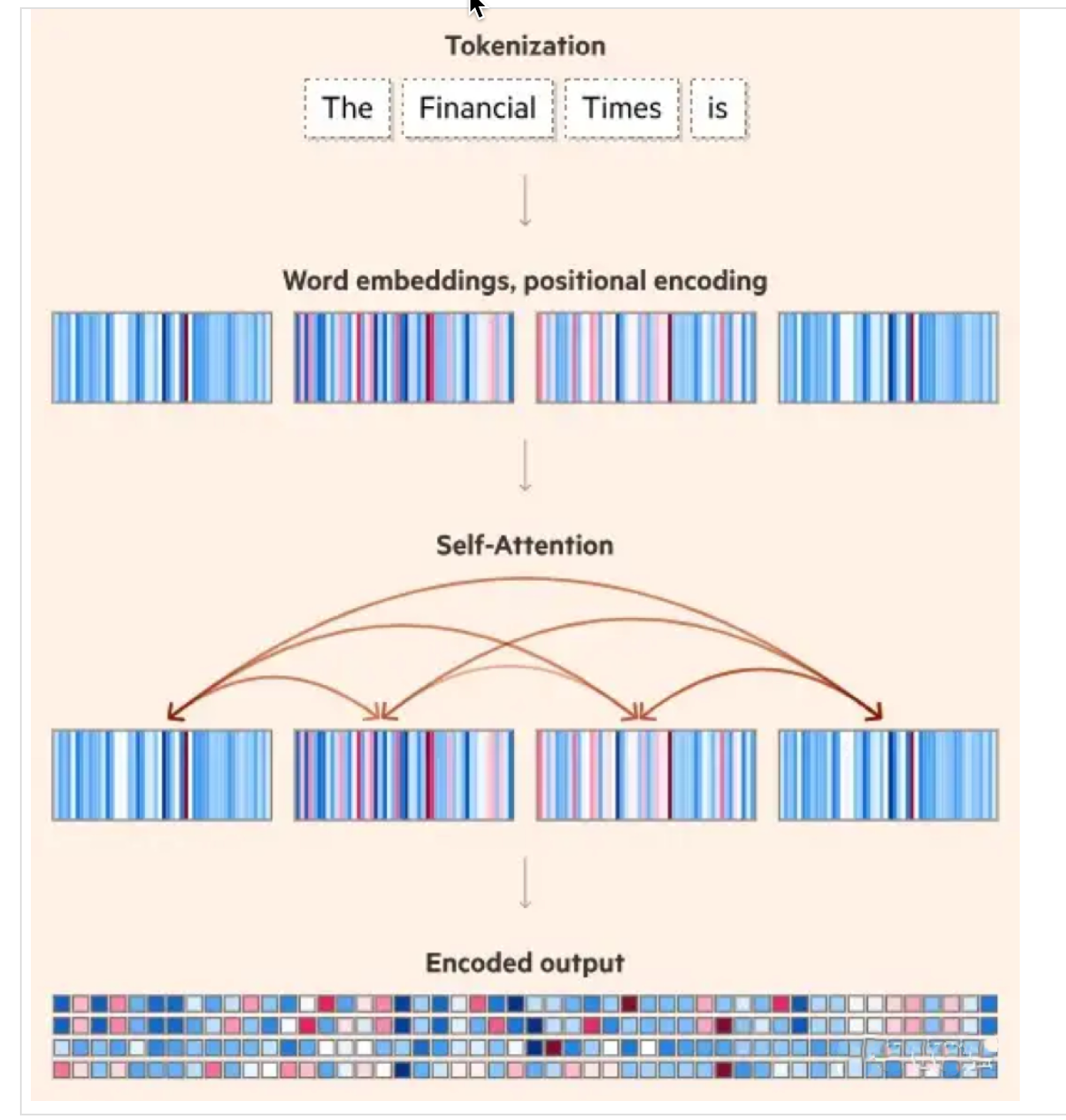
让我们以"The Financial Times is"这个实际输入为例,完整跟踪大模型的四步处理流程:
第一步:标记化(Tokenization)
将输入文本分割成标记(Token):"The"、"Financial"、"Times"、"is"
第二步:向量表示
- 将每个Token转换为词嵌入向量
- 添加位置编码,提供Token的位置信息
第三步:自注意力计算
- "Financial"与"Times"之间可能有高注意力得分,表明它们组成了一个实体
- "is"作为谓语动词,与主语"Financial Times"有较强联系
第四步:内容生成
基于语义理解的前提下,大模型基于训练所掌握的知识,基于概率预测后续的Token,可能生成如下内容:
- "The Financial Times is a daily newspaper focusing on business and economic news."
- "The Financial Times is owned by the Japanese company Nikkei Inc."
- "The Financial Times is known for its distinctive salmon-pink newsprint."
从理论到实践:大模型的应用案例
了解了大模型的核心运行机制后,让我们看看这些技术如何应用于实际场景。
多轮对话理解
在多轮对话中,大模型需要维持上下文连贯性。例如:
用户:"我想去纽约旅游"
大模型:"纽约有很多著名景点,如自由女神像、中央公园和帝国大厦。"
用户:"那里的天气怎么样?"
在回答第二个问题时,大模型需要理解"那里"指的是"纽约",这正是通过自注意力机制实现的:
- 词嵌入表示各个单词
- 自注意力计算发现"那里"与前文的"纽约"有高关联度
- 基于这种理解,模型能够准确回答纽约的天气情况
程序代码生成
当要求模型生成Python函数来计算斐波那契数列时:
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
大模型会:
- 理解"斐波那契数列"的含义(通过词嵌入和训练数据)
- 捕捉函数定义的结构(通过自注意力机制)
- 基于概率预测生成正确的代码语法和逻辑(通过生成机制)
案例代码:
import streamlit as st
import time
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import jieba
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib
# 指定中文字体路径(macOS)
font_path = "/System/Library/Fonts/PingFang.ttc" # macOS 中文字体
my_font = fm.FontProperties(fname=font_path)
# 设置 matplotlib 默认字体
matplotlib.rcParams['font.family'] = my_font.get_name()
matplotlib.rcParams['axes.unicode_minus'] = False
# 判断是否包含中文
def contains_chinese(text):
for ch in text:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
# 页面标题
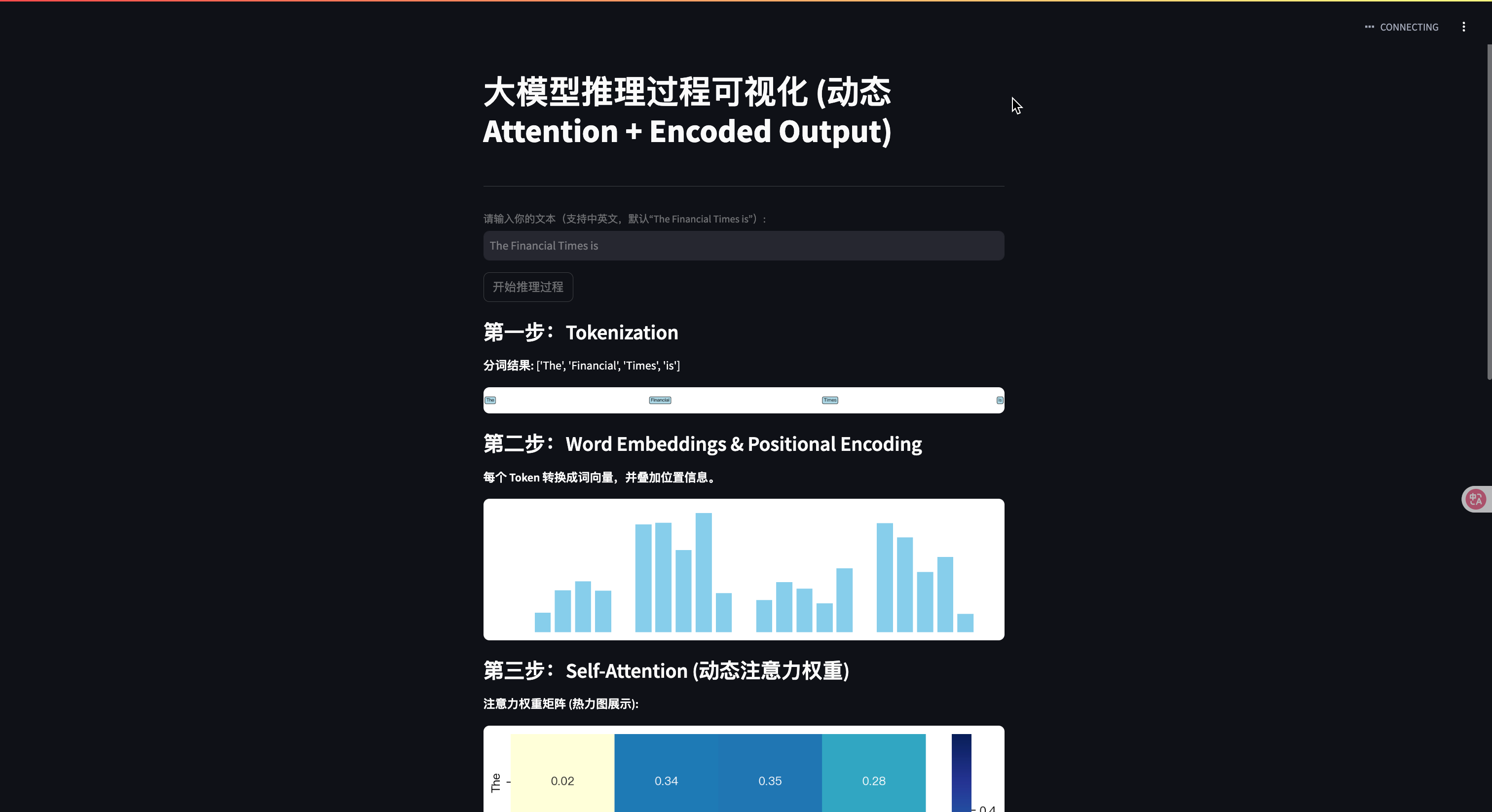
st.title("大模型推理过程可视化 (动态 Attention + Encoded Output)")
# 顶部流程总览图
st.image("/mnt/data/fa64a4f9-824c-4ac1-846f-c8d348428831.png", caption="大模型推理总览", use_column_width=True)
st.markdown("---")
# 输入框
input_text = st.text_input("请输入你的文本(支持中英文,默认“The Financial Times is”):", "The Financial Times is")
# 点击按钮
if st.button("开始推理过程"):
with st.spinner("正在推理中..."):
time.sleep(1)
# 1. 分词
if contains_chinese(input_text):
tokens = jieba.lcut(input_text)
else:
tokens = input_text.split()
st.subheader("第一步:Tokenization")
st.write(f"**分词结果:** {tokens}")
fig, ax = plt.subplots(figsize=(8, 1))
ax.axis('off')
for i, token in enumerate(tokens):
ax.text(i, 0.5, token, fontsize=12, ha='center', va='center',
bbox=dict(boxstyle='round', facecolor='lightblue'))
st.pyplot(fig)
time.sleep(1)
# 2. Embedding
st.subheader("第二步:Word Embeddings & Positional Encoding")
st.write("**每个 Token 转换成词向量,并叠加位置信息。**")
fig, ax = plt.subplots(figsize=(8, 2))
ax.axis('off')
for i, token in enumerate(tokens):
embedding = np.random.rand(5)
ax.bar(np.arange(i * 6, i * 6 + 5), embedding, color='skyblue')
st.pyplot(fig)
time.sleep(1)
# 3. Self-Attention with Heatmap
st.subheader("第三步:Self-Attention (动态注意力权重)")
# 随机生成注意力权重矩阵
num_tokens = len(tokens)
attention_scores = np.random.rand(num_tokens, num_tokens)
attention_scores = attention_scores / attention_scores.sum(axis=1, keepdims=True)
st.write("**注意力权重矩阵 (热力图展示):**")
fig, ax = plt.subplots(figsize=(8, 6))
sns.heatmap(attention_scores, xticklabels=tokens, yticklabels=tokens, cmap='YlGnBu', annot=True, fmt=".2f",
cbar=True)
st.pyplot(fig)
st.info("热力图解释:行表示 Query,列表示 Key,每个单元格表示注意力权重大小。")
time.sleep(1)
# 4. 生成预测输出
st.subheader("第四步:生成后续内容")
st.write("**模型在理解语义的基础上,预测出下一个 Token 以及后续内容。**")
dummy_output = ",汪汪叫着走了过来。" if contains_chinese(input_text) else "a leading newspaper."
st.success(f"**最终生成:** {input_text}{dummy_output}")
st.markdown("### 生成内容可视化")
full_text = tokens + (jieba.lcut(dummy_output) if contains_chinese(dummy_output) else dummy_output.split())
fig, ax = plt.subplots(figsize=(10, 1))
ax.axis('off')
for i, word in enumerate(full_text):
color = 'lightgreen' if i >= len(tokens) else 'lightblue'
ax.text(i, 0.5, word, fontsize=12, ha='center', va='center', bbox=dict(boxstyle='round', facecolor=color))
st.pyplot(fig)
time.sleep(1)
# 5. Encoded Output (最终编码表示)
st.subheader("第五步:Encoded Output")
st.write("**最终每个 Token 的编码向量,可供后续解码使用。**")
# 生成编码后的向量(比如每个Token是一个小向量,随机模拟)
encoded_output = np.random.rand(num_tokens, 20) # 20维编码向量
fig, ax = plt.subplots(figsize=(12, 2))
sns.heatmap(encoded_output, cmap='coolwarm', cbar=True, xticklabels=False, yticklabels=tokens)
st.pyplot(fig)
st.info("这里展示的是每个 Token 最终编码后的向量 (高维稠密表示),供解码器使用。")
st.balloons()
运行:streamlit run xxx.py

结语
大模型的三大核心运行机制 —— 理解和表示单词、理解输入内容、预测输出内容,共同构成了其强大能力的基础。通过词嵌入向量技术,模型能够理解单词;通过自注意力机制,模型能够理解上下文;通过概率预测,模型能够生成连贯的输出。
随着技术不断进步,这些核心机制也在不断优化,大模型的能力边界正在不断扩展,为我们带来更多令人惊叹的应用可能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号