06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。简而言之,sparkSQL是Spark的前身,是在Hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具。
sparkSQL提供了一个称为DataFrame(数据框)的编程抽象,DF的底层仍然是RDD,并且可以充当分布式SQL查询引擎。
SparkSql有哪些特点呢?
1)引入了新的RDD类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD。
2)在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
3)内嵌了查询优化框架,在把SQL解析成逻辑执行计划之后,最后变成RDD的计算。
2.用spark.read 创建DataFrame
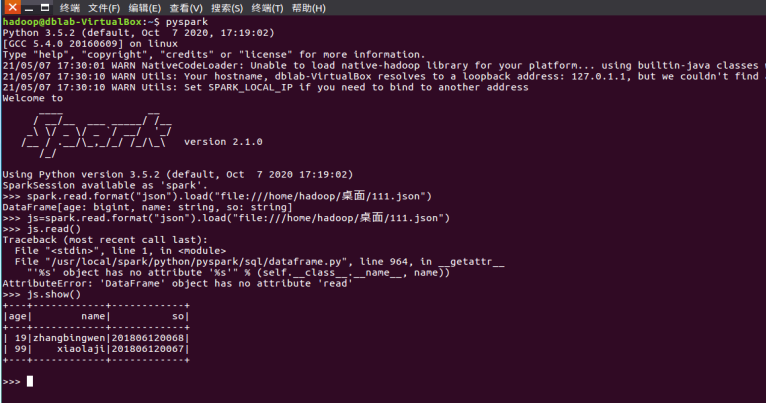
3.观察从不同类型文件创建DataFrame有什么异同?
可以看到通过sparkSession直接读取的文本文件,查询数据发现每一行的数据都统一放到了一个字段,而通过第一种方法就会按照字段分开
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
PandasSpark
工作方式单机 single machine tool,没有并行机制 parallelism
不支持 Hadoop,处理大量数据有瓶颈分布式并行计算框架,内建并行机制 parallelism,所有的数据和操作自动并行分布在各个集群结点上。以处理 in-memory 数据的方式处理 distributed 数据。
支持 Hadoop,能处理大量数据
延迟机制not lazy-evaluatedlazy-evaluated
内存缓存单机缓存persist() or cache() 将转换的 RDDs 保存在内存
DataFrame 可变性Pandas 中 DataFrame 是可变的Spark 中 RDDs 是不可变的,因此 DataFrame 也是不可变的
创建从 spark_df 转换:pandas_df = spark_df.toPandas()从 pandas_df 转换:spark_df = SQLContext.createDataFrame(pandas_df)
另外,createDataFrame 支持从 list 转换 spark_df,其中 list 元素可以为 tuple,dict,rdd
list,dict,ndarray 转换已有的 RDDs 转换
CSV 数据集读取结构化数据文件读取
HDF5 读取JSON 数据集读取
EXCEL 读取Hive 表读取
外部数据库读取
index 索引自动创建没有 index 索引,若需要需要额外创建该列
行结构Series 结构,属于 Pandas DataFrame 结构Row 结构,属于 Spark DataFrame 结构
列结构Series 结构,属于 Pandas DataFrame 结构Column 结构,属于 Spark DataFrame 结构,如:DataFrame[name: string]
列名称不允许重名允许重名
修改列名采用 alias 方法
列添加df[“xx”] = 0df.withColumn(“xx”, 0).show() 会报错
from pyspark.sql import functions
df.withColumn(“xx”, functions.lit(0)).show()
列修改原来有 df[“xx”] 列,df[“xx”] = 1原来有 df[“xx”] 列,df.withColumn(“xx”, 1).show()
显示 df 不输出具体内容,输出具体内容用 show 方法
输出形式:DataFrame[age: bigint, name: string]
df 输出具体内容df.show() 输出具体内容
没有树结构输出形式以树的形式打印概要:df.printSchema()
df.collect()
排序df.sort_index() 按轴进行排序
df.sort() 在列中按值进行排序df.sort() 在列中按值进行排序
选择或切片df.name 输出具体内容df[] 不输出具体内容,输出具体内容用 show 方法
df[“name”] 不输出具体内容,输出具体内容用 show 方法
df[] 输出具体内容,
df[“name”] 输出具体内容df.select() 选择一列或多列
df.select(“name”)
切片 df.select(df[‘name’], df[‘age’]+1)
df[0]
df.ix[0]df.first()
df.head(2)df.head(2) 或者 df.take(2)
df.tail(2)
切片 df.ix[:3] 或者 df.ix[:”xx”] 或者 df[:”xx”]
df.loc[] 通过标签进行选择
df.iloc[] 通过位置进行选择
过滤df[df[‘age’]>21]df.filter(df[‘age’]>21) 或者 df.where(df[‘age’]>21)
整合df.groupby(“age”)
df.groupby(“A”).avg(“B”)df.groupBy(“age”)
df.groupBy(“A”).avg(“B”).show() 应用单个函数
from pyspark.sql import functions
df.groupBy(“A”).agg(functions.avg(“B”), functions.min(“B”), functions.max(“B”)).show() 应用多个函数
统计df.count() 输出每一列的非空行数df.count() 输出总行数
df.describe() 描述某些列的 count, mean, std, min, 25%, 50%, 75%, maxdf.describe() 描述某些列的 count, mean, stddev, min, max
合并Pandas 下有 concat 方法,支持轴向合并
Pandas 下有 merge 方法,支持多列合并
同名列自动添加后缀,对应键仅保留一份副本Spark 下有 join 方法即 df.join()
同名列不自动添加后缀,只有键值完全匹配才保留一份副本
df.join() 支持多列合并
df.append() 支持多行合并
缺失数据处理对缺失数据自动添加 NaNs不自动添加 NaNs,且不抛出错误
fillna 函数:df.fillna()fillna 函数:df.na.fill()
dropna 函数:df.dropna()dropna 函数:df.na.drop()
SQL 语句import sqlite3
pd.read_sql(“SELECT name, age FROM people WHERE age>= 13 AND age <= 19″)表格注册:把 DataFrame 结构注册成 SQL 语句使用类型
df.registerTempTable(“people”) 或者 sqlContext.registerDataFrameAsTable(df, “people”)
sqlContext.sql(“SELECT name, age FROM people WHERE age>= 13 AND age <= 19″)
功能注册:把函数注册成 SQL 语句使用类型
sqlContext.registerFunction(“stringLengthString”, lambda x: len(x))
sqlContext.sql(“SELECT stringLengthString(‘test’)”)
两者互相转换pandas_df = spark_df.toPandas()spark_df = sqlContext.createDataFrame(pandas_df)
函数应用df.apply(f)将 df 的每一列应用函数 fdf.foreach(f) 或者 df.rdd.foreach(f) 将 df 的每一列应用函数 f
df.foreachPartition(f) 或者 df.rdd.foreachPartition(f) 将 df 的每一块应用函数 f
map-reduce 操作map(func, list),reduce(func, list) 返回类型 seqdf.map(func),df.reduce(func) 返回类型 seqRDDs
diff 操作有 diff 操作,处理时间序列数据(Pandas 会对比当前行与上一行)没有 diff 操作(Spark 的上下行是相互独立,分布式存储的)
PandasSpark工作方式单机 single machine tool,没有并行机制 parallelism不支持 Hadoop,处理大量数据有瓶颈分布式并行计算框架,内建并行机制 parallelism,所有的数据和操作自动并行分布在各个集群结点上。以处理 in-memory 数据的方式处理 distributed 数据。支持 Hadoop,能处理大量数据延迟机制not lazy-evaluatedlazy-evaluated内存缓存单机缓存persist() or cache() 将转换的 RDDs 保存在内存DataFrame 可变性Pandas 中 DataFrame 是可变的Spark 中 RDDs 是不可变的,因此 DataFrame 也是不可变的创建从 spark_df 转换:pandas_df = spark_df.toPandas()从 pandas_df 转换:spark_df = SQLContext.createDataFrame(pandas_df)另外,createDataFrame 支持从 list 转换 spark_df,其中 list 元素可以为 tuple,dict,rddlist,dict,ndarray 转换已有的 RDDs 转换CSV 数据集读取结构化数据文件读取HDF5 读取JSON 数据集读取EXCEL 读取Hive 表读取 外部数据库读取index 索引自动创建没有 index 索引,若需要需要额外创建该列行结构Series 结构,属于 Pandas DataFrame 结构Row 结构,属于 Spark DataFrame 结构列结构Series 结构,属于 Pandas DataFrame 结构Column 结构,属于 Spark DataFrame 结构,如:DataFrame[name: string]列名称不允许重名允许重名修改列名采用 alias 方法列添加df[“xx”] = 0df.withColumn(“xx”, 0).show() 会报错from pyspark.sql import functionsdf.withColumn(“xx”, functions.lit(0)).show()列修改原来有 df[“xx”] 列,df[“xx”] = 1原来有 df[“xx”] 列,df.withColumn(“xx”, 1).show()显示 df 不输出具体内容,输出具体内容用 show 方法输出形式:DataFrame[age: bigint, name: string]df 输出具体内容df.show() 输出具体内容没有树结构输出形式以树的形式打印概要:df.printSchema() df.collect()排序df.sort_index() 按轴进行排序 df.sort() 在列中按值进行排序df.sort() 在列中按值进行排序选择或切片df.name 输出具体内容df[] 不输出具体内容,输出具体内容用 show 方法df[“name”] 不输出具体内容,输出具体内容用 show 方法df[] 输出具体内容,df[“name”] 输出具体内容df.select() 选择一列或多列df.select(“name”)切片 df.select(df[‘name’], df[‘age’]+1)df[0]df.ix[0]df.first()df.head(2)df.head(2) 或者 df.take(2)df.tail(2) 切片 df.ix[:3] 或者 df.ix[:”xx”] 或者 df[:”xx”] df.loc[] 通过标签进行选择 df.iloc[] 通过位置进行选择 过滤df[df[‘age’]>21]df.filter(df[‘age’]>21) 或者 df.where(df[‘age’]>21)整合df.groupby(“age”)df.groupby(“A”).avg(“B”)df.groupBy(“age”)df.groupBy(“A”).avg(“B”).show() 应用单个函数from pyspark.sql import functionsdf.groupBy(“A”).agg(functions.avg(“B”), functions.min(“B”), functions.max(“B”)).show() 应用多个函数统计df.count() 输出每一列的非空行数df.count() 输出总行数df.describe() 描述某些列的 count, mean, std, min, 25%, 50%, 75%, maxdf.describe() 描述某些列的 count, mean, stddev, min, max合并Pandas 下有 concat 方法,支持轴向合并 Pandas 下有 merge 方法,支持多列合并同名列自动添加后缀,对应键仅保留一份副本Spark 下有 join 方法即 df.join()同名列不自动添加后缀,只有键值完全匹配才保留一份副本df.join() 支持多列合并 df.append() 支持多行合并 缺失数据处理对缺失数据自动添加 NaNs不自动添加 NaNs,且不抛出错误fillna 函数:df.fillna()fillna 函数:df.na.fill()dropna 函数:df.dropna()dropna 函数:df.na.drop()SQL 语句import sqlite3pd.read_sql(“SELECT name, age FROM people WHERE age>= 13 AND age <= 19″)表格注册:把 DataFrame 结构注册成 SQL 语句使用类型df.registerTempTable(“people”) 或者 sqlContext.registerDataFrameAsTable(df, “people”)sqlContext.sql(“SELECT name, age FROM people WHERE age>= 13 AND age <= 19″)功能注册:把函数注册成 SQL 语句使用类型sqlContext.registerFunction(“stringLengthString”, lambda x: len(x))sqlContext.sql(“SELECT stringLengthString(‘test’)”)两者互相转换pandas_df = spark_df.toPandas()spark_df = sqlContext.createDataFrame(pandas_df)函数应用df.apply(f)将 df 的每一列应用函数 fdf.foreach(f) 或者 df.rdd.foreach(f) 将 df 的每一列应用函数 fdf.foreachPartition(f) 或者 df.rdd.foreachPartition(f) 将 df 的每一块应用函数 fmap-reduce 操作map(func, list),reduce(func, list) 返回类型 seqdf.map(func),df.reduce(func) 返回类型 seqRDDsdiff 操作有 diff 操作,处理时间序列数据(Pandas 会对比当前行与上一行)没有 diff 操作(Spark 的上下行是相互独立,分布式存储的)————————————————版权声明:本文为CSDN博主「小晓酱手记」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/sinat_26811377/article/details/99780553

 浙公网安备 33010602011771号
浙公网安备 33010602011771号