

算法分析与实践作业11
1. 问题
代码(码字):Q{001,00,010,11}表示字符a,b,c,d
同一序列:0100001
产生两种译码(产生歧义):01 00 001;010 00 01
二元前缀码:任何字符的代码不能作为其他字符代码的前缀
利用二元前缀码译码:从第一个字符开始依次读入每个字符(0或1),如果发现读到的字串与某个码字相等,就将这个子串译作对应的码字;然后从下一个字符开始继续这个个过程,直到读完输入的字符串为止。
二元前缀编码存储:二叉树结构,每个字符作为树叶,对应这个字符的前缀码看作根到这片树叶的一条路径,每个结点通向左儿子的边记作0,通向右儿子的边记作1。
字符集合C={x1,x2,…,xn}
xi的频率是f(xi)
d(xi)表示字符xi二进制位数,也就是xi的码长
二元前缀编码:二叉树
码字:树叶
码字的二进制位数:树叶的深度
存储一个字符所使用的二进制数的平均值
B=∑(i=1,n)f(xi)d(xi)
最优二元前缀码:每个码字平均使用二进制位数最小的前缀码,称为二元最优前缀码。
问题:给定字符集C={x1,x2,……,xn}和每个字符的频率f(xi),求关于C的一个最优前缀码。
2. 解析
构造最优前缀码的贪心算法是哈夫曼算法。
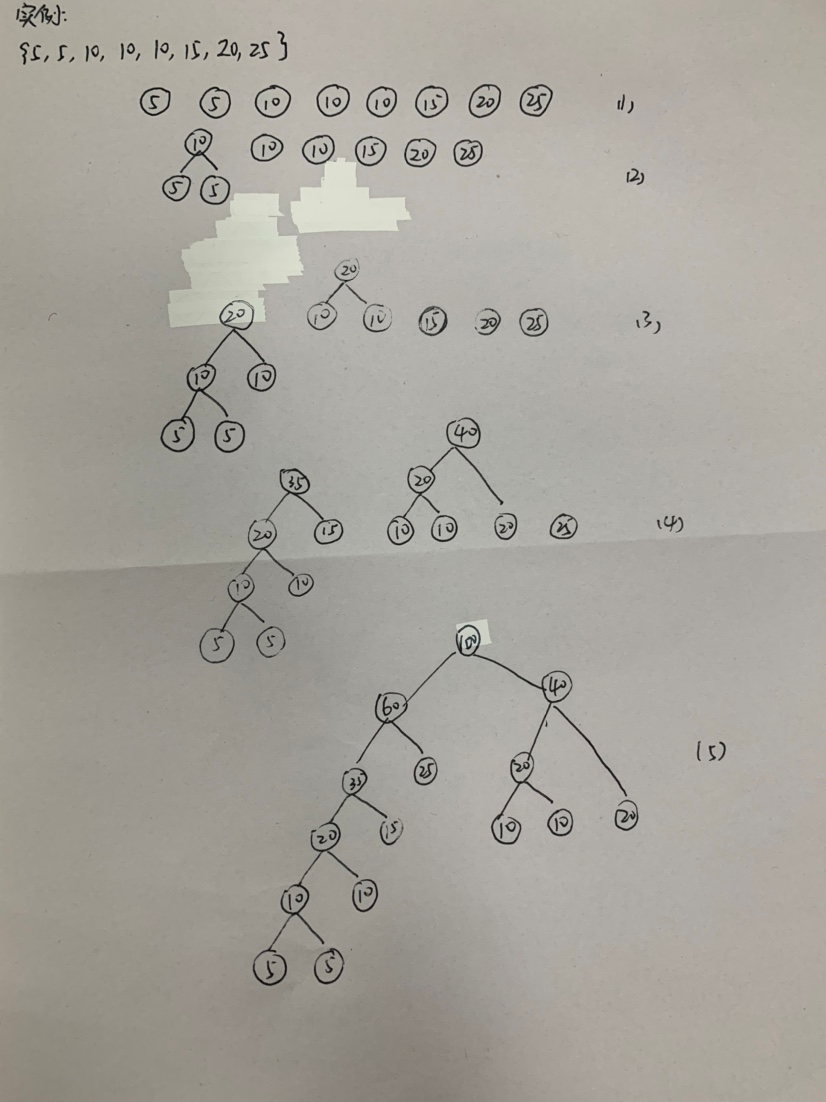
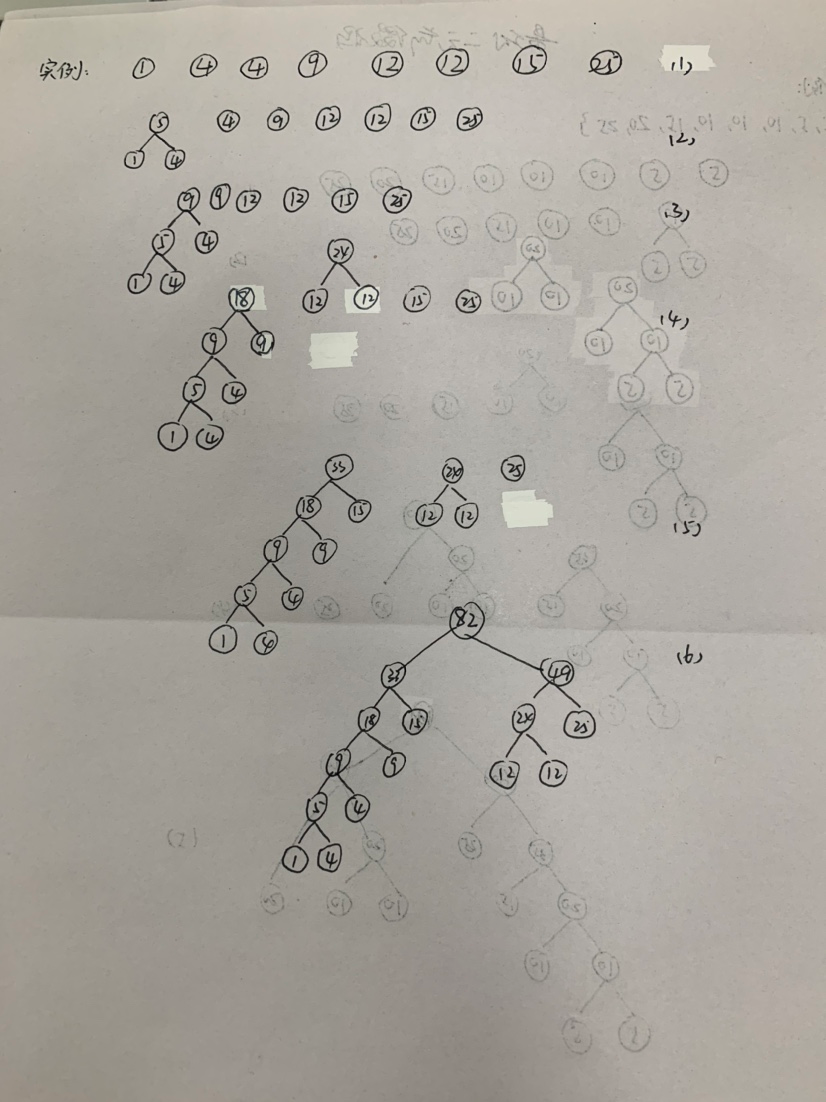
3. 设计
Huffman算法:
输入:C={x1,x2,…,xn}字符集,每个字符的频率f(xi),i=1,2,…,n.
输出:Q
1.n<-|C|
2.Q<-C //按频率递增构成队列 Q
3.for i<-1 to n-1 do
4. z<-Allocate-Node()
5. z.left<-Q中最小元 //取出Q中最小元作为z的左儿子
6. z.right<-Q中最小元 //取出Q中最小元作为z的右儿子
7. f(z)<-f(x)+f(y)
8. Insert(Q,z)
9.return Q
4. 分析
运行截图:
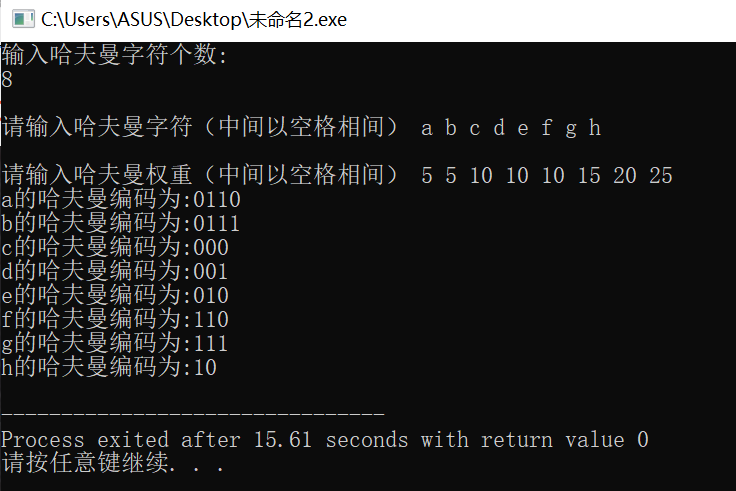
O(nlogn)频率排序:for 循环O(n),插入操作O(logn),算法时间复杂度是O(nlogn)
5. 源码
github地址:https://github.com/122cmy/myGitTemp11
博客地址:https://www.cnblogs.com/122cmy/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号