第四次作业
作业①
爬取当当网图书数据
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
关键词:学生自由选择
输出信息:MYSQL的输出信息如下

代码:
spider.py
import scrapy
from dangdang.items import DangdangItem
class SpiderSpider(scrapy.Spider):
name = 'spider'
start_urls = ['http://search.dangdang.com/?key=python%B1%E0%B3%CC&act=input']
id=0
def parse(self, response):
li_list = response.xpath('//*[@id="component_59"]/li') # 解析文本,每个li对应一个商品信息
for li in li_list:
self.id+=1
item = DangdangItem()
# Id = li.xpath("./@ddt-pit").extract_first()
Title = li.xpath("./a[1]/@title").extract_first()
Author = li.xpath("./p[@class='search_book_author']/span[1]/a[1]/@title").extract_first()
Pubilsher = li.xpath("./p[@class='search_book_author']/span[3]/a/@title").extract_first()
Date = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first()
Price = li.xpath("./p[@class='price']/span[1]/text()").extract_first()
Detail = li.xpath("./p[@class='detail']/text()").extract_first()
item['Id'] = self.id
item['Title'] = Title
item['Author'] = Author
item['Publisher'] = Pubilsher
item['Date'] = Date #有些书本数据是没有出版日期的
item['Price'] = Price
item['Detail'] = Detail #有时没有,结果为None
cur_page = response.xpath('//*[@id="t__cp"]/@value').extract_first() #获取当前页码
all_page = response.xpath('//*[@id="12810"]/div[5]/div[2]/div/ul/li[last()-2]/a/text()').extract_first() #总页码
if int(cur_page) < int(all_page):
new_url = self.start_urls[0]+"&page_index="+str(int(cur_page)+1) #下一页
yield scrapy.Request(url=new_url, callback=self.parse)
yield item
items.py
import scrapy
class DangdangItem(scrapy.Item): #对象结构定义
# define the fields for your item here like:
# name = scrapy.Field()
Id=scrapy.Field()
Title=scrapy.Field()
Author=scrapy.Field()
Publisher=scrapy.Field()
Date=scrapy.Field()
Price=scrapy.Field()
Detail=scrapy.Field()
pipilines.py
import pymysql
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class mysqlPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='root', db='spider', # 连接数据库
charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try: # 插入数据
self.cursor.execute('insert into dangdang values(%s,%s,%s,%s,%s,%s,%s)',
(item["Id"], item["Title"], item['Author'], item['Publisher'], item['Date'],
item['Price'], item['Detail']))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close() # 关闭连接
self.conn.close()
settings.py
BOT_NAME = 'dangdang'
SPIDER_MODULES = ['dangdang.spiders']
NEWSPIDER_MODULE = 'dangdang.spiders'
LOG_LEVEL = 'ERROR' # 日志级别设为ERROR
# 设置user——agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
ROBOTSTXT_OBEY = False # 不遵从robots协议
ITEM_PIPELINES = {
'dangdang.pipelines.mysqlPipeline': 300, # 打开管道
}
运行结果部分展示:

心得体会
加深scrapy的了解以及MySQL数据库的操作
问题与思考
关于xpath中的tbody,在用xpath解析网页的时候,会遇到tbody标签。tbody标签有的时候可以解析,有的时候不可以解析,遇到tbody标签时要看网页源代码,如果源代码有tbody标签,就要加上tbody标签才能解析。如果源代码没有tbody标签,那么tbody标签是浏览器对html文本进行一定的规范化而强行加上去的,这时如果xpath中有tbody则无法解析出来,此时去掉xpath中的tbody即可。
作业②
爬取股票信息
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:

代码:
stock.py
import scrapy
from selenium import webdriver
from stocks.items import StocksItem
class StockSpider(scrapy.Spider):
name = 'stock'
start_urls = ['http://quote.eastmoney.com/center/gridlist.html#hs_a_board'] #加入其他模块会乱序,就只爬一个板块。
def __init__(self): #开启实验性功能参数
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
self.bro = webdriver.Chrome(options=options)
# self.bro=webdriver.Chrome()
def parse(self, response):
tr_list = response.xpath('//*[@id="table_wrapper-table"]/tbody/tr')
for tr in tr_list:
item = StocksItem()
id = tr.xpath("./td[1]/text()").extract_first()
no = tr.xpath("./td[2]/a/text()").extract_first()
name = tr.xpath("./td[3]/a/text()").extract_first()
latest_price = tr.xpath("./td[5]/span/text()").extract_first()
range = tr.xpath("./td[6]/span/text()").extract_first()
amount = tr.xpath("./td[7]/span/text()").extract_first()
trading = tr.xpath("./td[8]/text()").extract_first()
transaction = tr.xpath("./td[9]/text()").extract_first()
item['id'] = id
item['no'] = no
item['name'] = name
item['latest_price'] = latest_price
item['range'] = range
item['amount'] = amount
item['trading'] = trading
item['transaction'] = transaction
yield item
def closed(self, spider):
self.bro.quit() #关闭浏览器
items.py
import scrapy
class StocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id=scrapy.Field()
no=scrapy.Field()
name=scrapy.Field()
latest_price=scrapy.Field()
range=scrapy.Field()
amount=scrapy.Field()
trading=scrapy.Field()
transaction=scrapy.Field()
pipielines.py
import pymysql
class StocksPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='root', db='spider',
charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into stocks values("%s","%s","%s","%s","%s","%s","%s","%s")' %
(item["id"], item["no"], item['name'], item['latest_price'], item['range'],
item['amount'], item['trading'],item['transaction']))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
middlewares.py
from scrapy.http import HtmlResponse
from time import sleep
from scrapy.selector import Selector
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class StocksDownloaderMiddleware:
def process_request(self, request, spider):
return None
# 该方法拦截响应对象,进行篡改
def process_response(self, request, response, spider): # spider爬虫对象
html = ""
page = 1
all_page = 2
# Called with the response returned from the downloader.
bro = spider.bro # 获取了在爬虫类中定义的浏览器对象
bro.get(request.url)
sleep(2)
while (int(page) < 3): # 我只爬了三页,如果需要可以爬取全部while (int(page)<int(all_page))
bro.execute_script('window.scrollTo(0, document.body.scrollHeight)')
sleep(2)
page_text = bro.page_source
html = html + page_text #多页数据拼接
text = Selector(text=page_text)
page = text.xpath(
'//*[@id="main-table_paginate"]/span[1]/a[@class="paginate_button current"]/text()').extract_first()
all_page = text.xpath('//*[@id="main-table_paginate"]/span[1]/a[last()]/text()').extract_first()
if int(page) < 3:
bro.find_element_by_xpath('//*[@id="main-table_paginate"]/a[2]').click()
# 篡改response
# 实例化一个新的响应对象(符合需求:包含动态加载出的股票数据),替代原来旧的响应对象
new_response = HtmlResponse(url=request.url, body=bytes(html, encoding='utf-8'), request=request)
return new_response
def process_exception(self, request, exception, spider):
pass
settings.py
BOT_NAME = 'stocks'
SPIDER_MODULES = ['stocks.spiders']
NEWSPIDER_MODULE = 'stocks.spiders'
ROBOTSTXT_OBEY =False
LOG_LEVEL='ERROR'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
DOWNLOADER_MIDDLEWARES = {
'stocks.middlewares.StocksDownloaderMiddleware': 543,
} #开启下载中间件
ITEM_PIPELINES = {
'stocks.pipelines.StocksPipeline': 300,
}
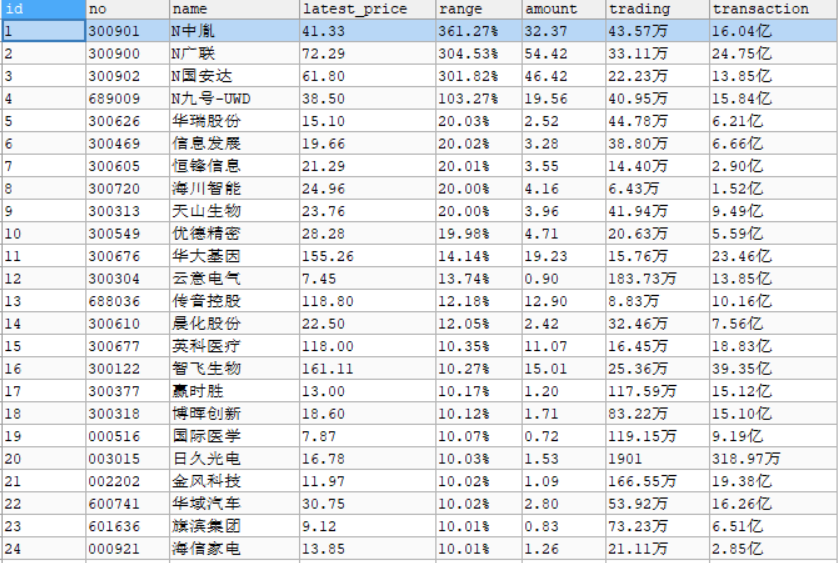
运行结果部分展示:
心得体会
了解scrapy爬虫框架与selenium搭配使用
问题与思考

现在不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为
undefined。而使用selenium访问则该值为true。只需要设置Chromedriver的启动参数即可解决问题。在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为[‘enable-automation’]
scrapy框架+selenium的使用:
当引擎将url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的数据。要想获取动态加载的数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
selenium在scrapy中的使用流程:
重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
在配置文件中开启下载中间件
作业③
爬取外汇网站数据
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
输出信息:MYSQL数据库存储和输出格式

代码:
spider.py
import scrapy
from cmbchina.items import CmbchinaItem
class SpiderSpider(scrapy.Spider):
name = 'spider'
start_urls = ['http://fx.cmbchina.com/hq/']
id=0
def parse(self, response):
tr_list=response.xpath('//*[@id="realRateInfo"]/table//tr')
for tr in tr_list[1:]:
self.id+=1
Id=str(self.id)
Currency = tr.xpath("./td[1]/text()").extract_first().strip()
TSP = tr.xpath("./td[4]/text()").extract_first().strip()
CSP = tr.xpath("./td[5]/text()").extract_first().strip()
TBP = tr.xpath("./td[6]/text()").extract_first().strip()
CBP = tr.xpath("./td[7]/text()").extract_first().strip()
Time= tr.xpath("./td[8]/text()").extract_first().strip()
item=CmbchinaItem()
item['Id']=Id
item['Currency'] = Currency
item['TSP'] = TSP
item['CSP'] = CSP
item['TBP'] =TBP
item['CBP'] = CBP
item['Time'] = Time
yield item
items.py
class CmbchinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Id = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP= scrapy.Field()
TBP= scrapy.Field()
CBP = scrapy.Field()
Time= scrapy.Field()
pipelines.py
import pymysql
class CmbchinaPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='root', db='spider',
charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into cmbchina values("%s","%s","%s","%s","%s","%s","%s")' %
(item['Id'],item['Currency'],item['TSP'],item['CSP'],item['TBP'],item['CBP'],item['Time']))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
settings.py
BOT_NAME = 'cmbchina'
SPIDER_MODULES = ['cmbchina.spiders']
NEWSPIDER_MODULE = 'cmbchina.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
ITEM_PIPELINES = {
'cmbchina.pipelines.CmbchinaPipeline': 300,
}
心得体会
加深scrapy的了解


 浙公网安备 33010602011771号
浙公网安备 33010602011771号