
2023数据采集与融合技术实践作业3
2023数据采集与融合技术实践作业3
下面是gitee仓库链接的链接,就不一个一个放在作业内了
唯一链接
作业①
-
实验要求
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
spider代码:
import scrapy
from ..items import ImgItem
from scrapy.selector import Selector
import random
# 爬取网站所有的图片
class FirstSpider(scrapy.Spider):
name = 'first'
start_urls = ['http://www.weather.com.cn/']
count = 1
page = input('请输入要爬取的页数:')
def parse(self, response):
# 获取所有图片的url
response = Selector(response=response)
img_urls = response.css('img::attr(src)').extract()
# 获取任意可跳转的url
next_urls = response.css('a::attr(href)').extract()
if (FirstSpider.count < int(FirstSpider.page)):
FirstSpider.count += 1
nexturl = next_urls[random.randint(0,len(next_urls))]
yield scrapy.Request(url=nexturl, callback=self.parse)
for img in img_urls:
item = ImgItem()
item['img'] = img
yield item
在spider内做了图片链接的收集以及对任意链接的随机进行下一页读取图片。
piplines代码:
from itemadapter import ItemAdapter
import requests
class ImgPipeline:
def process_item(self, item, spider):
url = item['img']
# 下载图片
r = requests.get(url)
# 保存图片
print('-----------------------')
with open('D:\作业\数据采集实践\Text3\img\\' + url.split('/')[-1], 'wb') as f:
f.write(r.content)
return item
在piplines内做了下载图片并存储的操作
运行结果
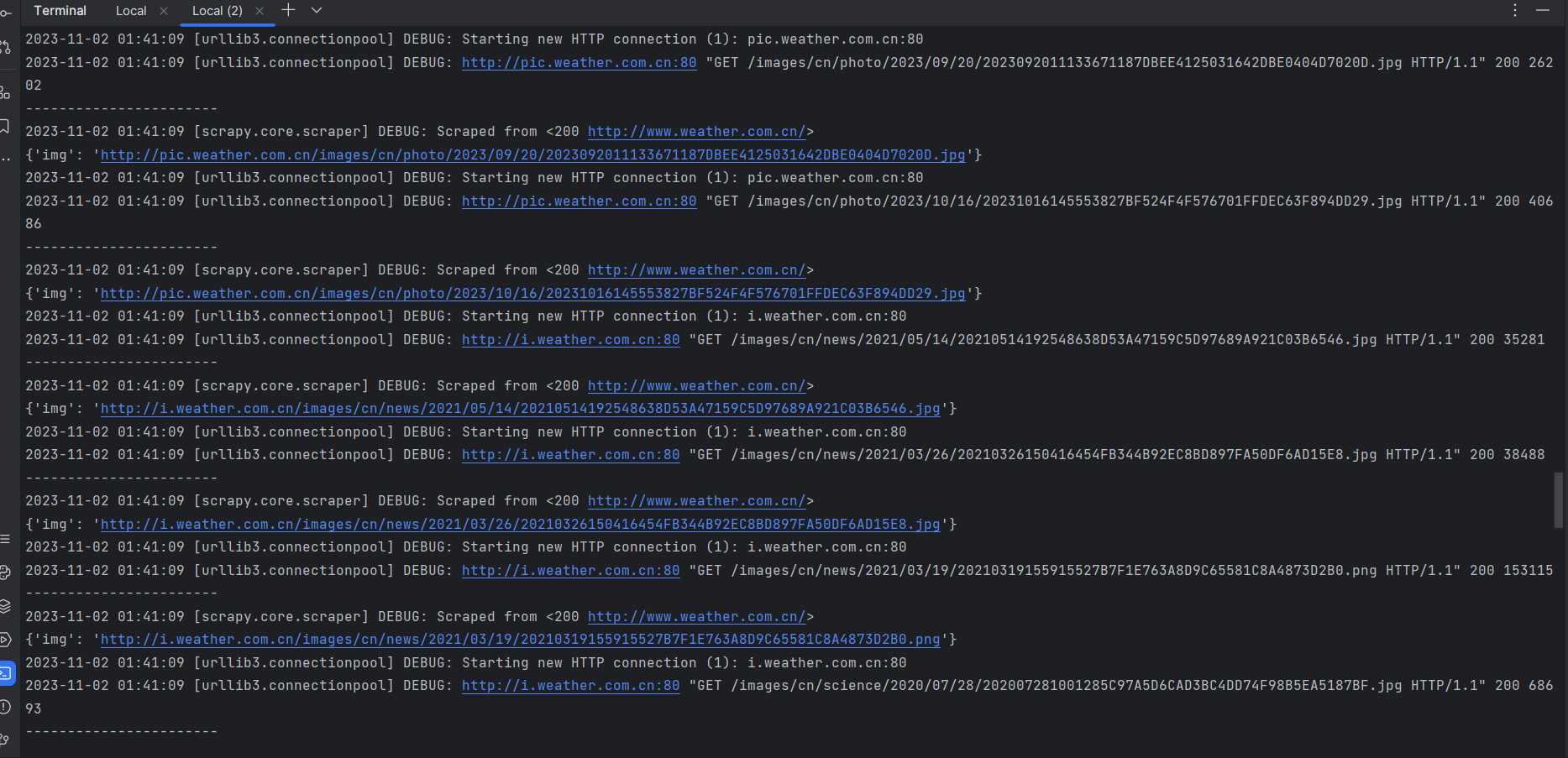
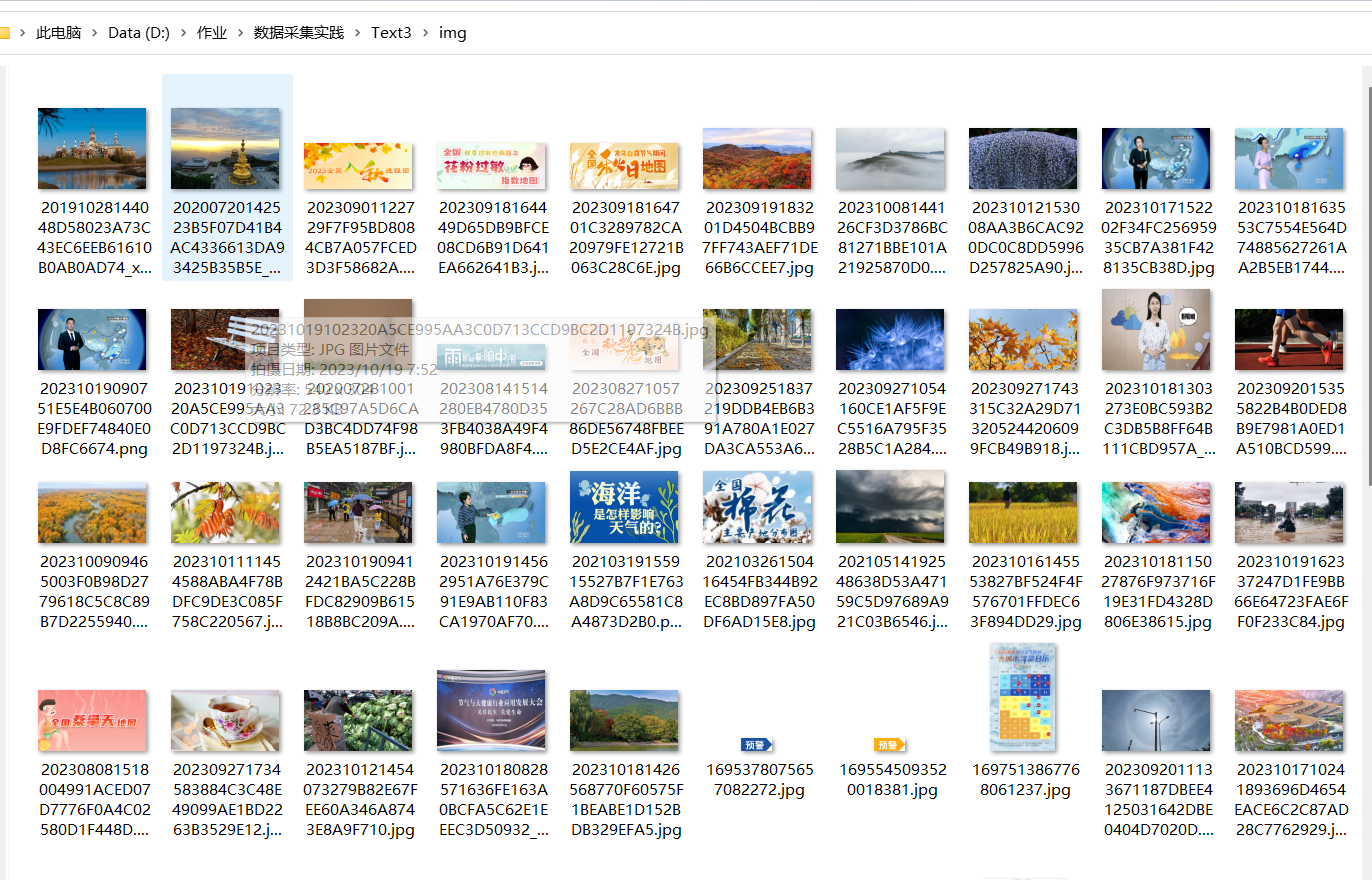
心得体会
对于多个界面的读取来说scrapy本身就是多线程执行,当我们把next_url用yield传送到调度中心时它会自动送入spider进行解析,而不用等待直到当前的spider运行结束。对于图片下载的多进程则是同理,在这个程序中我把下载放到了一个个的piplines内进行,也相当于多进程进行下载
作业②
爬取股票相关信息实验
- 实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
代码展示:
import scrapy
import re
from ..items import StockItem
class FirstSpider(scrapy.Spider):
name = 'first'
k = 1
start_urls = ['https://83.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407209120313174064_1697706313422&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14&_=1697706313423']
page = input('请输入要查询的页数:')
def parse(self, response):
html = response.text
info = []
for i in range(2, 7):
r = r'f' + str(i) + '":(.*?),'
info.append(re.findall(r, html))
info.append(re.findall(r'f12":"(.*?)",', html))
info.append(re.findall(r'f14":"(.*?)"', html))
for i in range(0, len(info[0])):
print(str(i + 1) + ' ' + info[6][i] + ' ' + info[5][i] + ' ' + info[0][i] + ' ' + info[1][i] + '% ' + info[2][
i] + '% ' + info[3][i] + ' ' + info[4][i])
# 序号' + ' ' + '名称' + ' ' + '代码' + ' ' + '最新价' + ' ' + '涨跌幅' + ' ' + '涨跌额' + ' ' + '成交量' + ' ' + '成交额'
item = StockItem()
item['stock_id'] = str(i + 1 + (self.k - 1) * 20)
item['stock_name'] = info[6][i]
item['stock_code'] = info[5][i]
item['stock_price'] = info[0][i]
item['stock_change_percent'] = info[1][i]
item['stock_change_amount'] = info[2][i]
item['stock_volume'] = info[3][i]
item['stock_turnover'] = info[4][i]
yield item
if self.k < int(self.page):
self.k += 1
yield scrapy.Request(url='https://85.push2.eastmoney.com/api/qt/clist/get?cb='
'jQuery112409728831597559529_1697699443372&pn=' + str(self.k) +
'&pz=20&po=1&np=1'
'&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web'
'&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697699443373',
callback=self.parse)
利用re来获取需要的信息,比较实用省去load数据的操作
运行结果
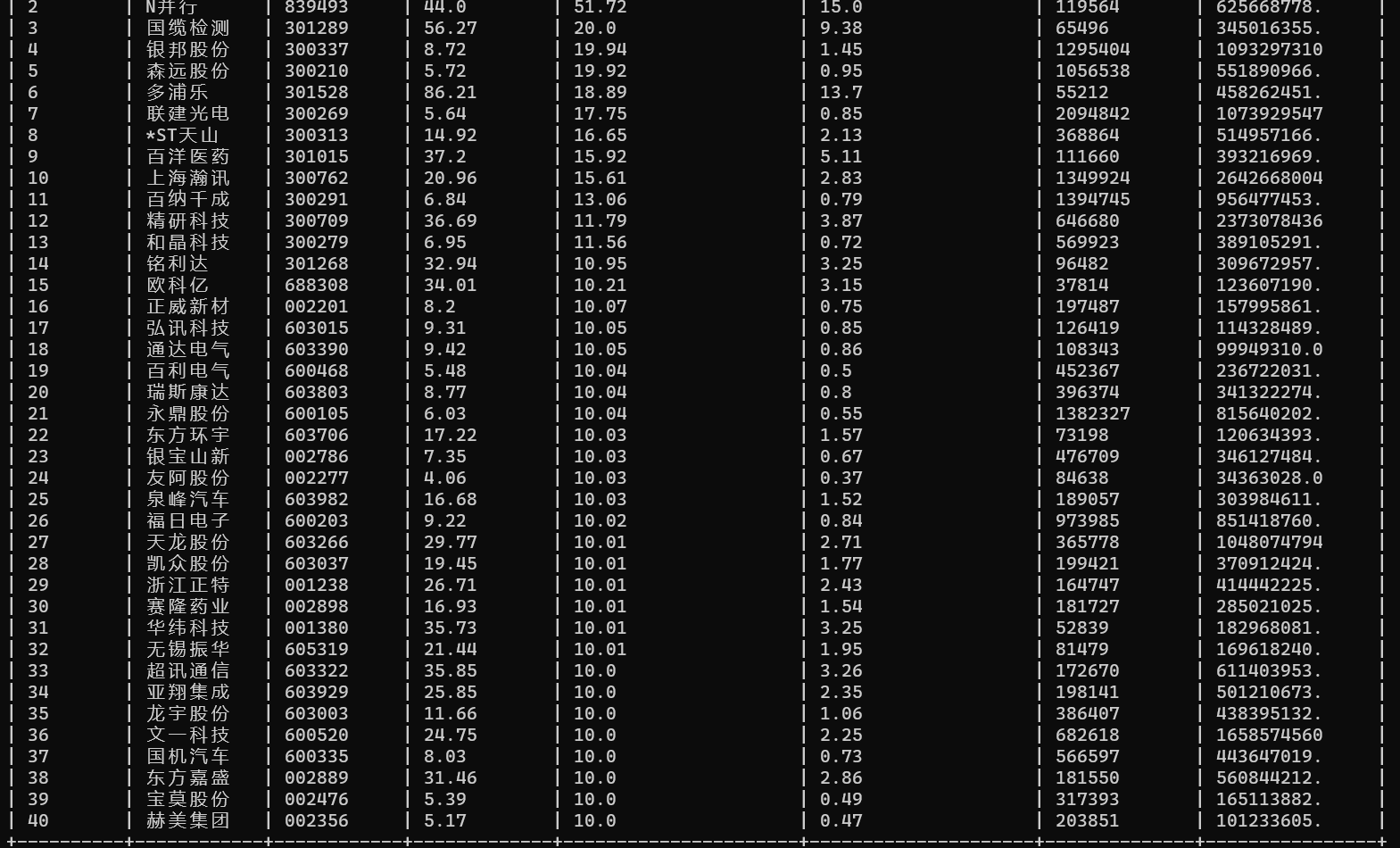
心得体会
没有太大难度,基本是把上一次实验的代码搬运过来,唯一卡壳的点在于一开始没有注意url过长超过了scrapy接收url的默认长度,后续在setting内修改即可(具体设置 'URLLENGTH_LIMIT = 5000, ROBOTSTXT_OBEY = False'),在交之前运行了一遍发现即使是获取的接口数据也时实时更新的,并且是以涨幅降序排序,相信要是设置不同的base_url也能轻松完成简单的不同类排序(如按成交额排序什么之类的)
作业③
爬取外汇网站数据
- 实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码展示
import scrapy
from bs4 import BeautifulSoup
from scrapy.selector import Selector
from ..items import RateItem
class FirstSpider(scrapy.Spider):
name = "first"
start_urls = ["https://www.boc.cn/sourcedb/whpj"]
page = input("请输入页数:")
count = 1
def parse(self, response):
data = response.text
s = Selector(text=data)
soup = BeautifulSoup(data, 'html.parser')
trs = soup.find_all('table')[1].find_all('tr')
for tr in trs[1:]:
tds = tr.find_all('td')
item = {}
item['currency'] = tds[0].text
item['TBP'] = tds[1].text
item['CBR'] = tds[2].text
item['TSP'] = tds[3].text
item['CSP'] = tds[4].text
item['BCS'] = tds[5].text
item['time'] = tds[6].text
yield item
for self.count in range(1, int(self.page)):
self.count += 1
url = "https://www.boc.cn/sourcedb/whpj/index_" + str(self.count) + ".html"
yield scrapy.Request(url=url, callback=self.parse)
运行结果
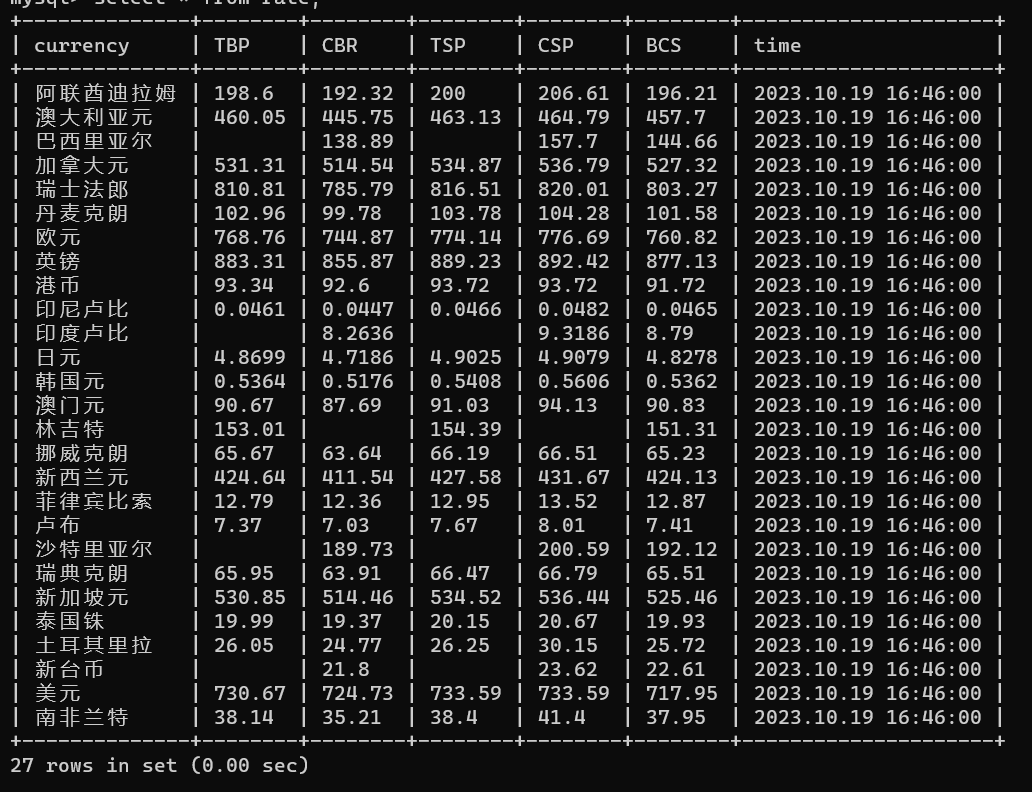
心得体会
相对简单,html结构很清爽,信息提取的很舒适。数据库未做空值处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号