

| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 1、通过系统化流程完成软件开发 2、学会使用性能测试工具和单元测试以优化程序 |
Github链接
- (建议使用该项目的v1.0.1版本)
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 60 | 45 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 150 | 190 |
| Design Spec | 生成设计文档 | 60 | 75 |
| Design Review | 设计复审 | 45 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| Design | 具体设计 | 45 | 60 |
| Coding | 具体编码 | 220 | 260 |
| Code Review | 代码复审 | 60 | 45 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 160 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 60 | 150 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 45 |
| 合计 | 960 | 1180 |
模块接口的设计与实现过程
- 该论文查重系统只使用了一个FileProcessor类来存储读取的文件路径、对应的文件内容,以及标准化后的文本和生成的n-gram集合,以便于数据的重复调用,其余功能均使用独立函数实现;
该系统的核心功能为文本标准化与n-gram集合生成,对不同长度的文本采用不同的n-gram生成策略,在考虑精确度的同时提升效率,同时也能避免处理短文本时的性能浪费。
文件目录结构
homework2/作业文件夹根目录
│
├── answer.txt 记录输出结果的文件
│
├── file_input.py 从命令行读取的方法
│
├── file_processing.py 文件处理的方法
│
├── main.py 主代码
│
├── org.txt 以下都是测试文本文件
├── org_add.txt
├── org_add_del.txt
├── org_add_dir_1.txt
├── org_add_dir_10.txt
├── org_add_dir_15.txt
│
├── requirement.txt 代码依赖文件
│
└── test.txt 单元测试脚本
使用方法
从命令行参数给出:python main.py [原文文件绝对路径] [抄袭版论文的文件绝对路径] [答案文件绝对路径]
模块结构
- 文件输入模块 (file_input.py)
- 使用
argparse解析命令行参数
- 使用
- 文件处理模块 (file_processing.py)
FileProcessor类管理文件路径和处理流程- 文本归一化、n-gram生成、集合运算
- 核心算法模块 (main.py)
- Jaccard相似度计算
- 结果输出控制
关键算法实现流程
- 文本标准化:
flowchart TD
A[原始数据] --> B[去除非中英数空格]
B --> C[合并连续空格]
C --> D[切分混合字符串]
D --> E[中文/英文/数字分离]
- n-gram生成
flowchart TD
A[读取标准化文本] --> B[将中文句子按字切分,英文句子按词切分]
B --> C[评估文本长度采取生成策略]
C --> D[长文本生成2-gram和3-gram]
C --> E[短文本生成2-gram]
E --> G[每次取 i->i+n 个词组成一组,录入n-gram集合]
D --> G
- 计算jccard相似度
flowchart TD
A[读取待比较文件n-gram集合] --> B[计算两个集合的交集长度与并集长度]
B --> C[按权重混合2-gram与3-gram的比较结果]
C --> D[输出最终结果]
性能分析
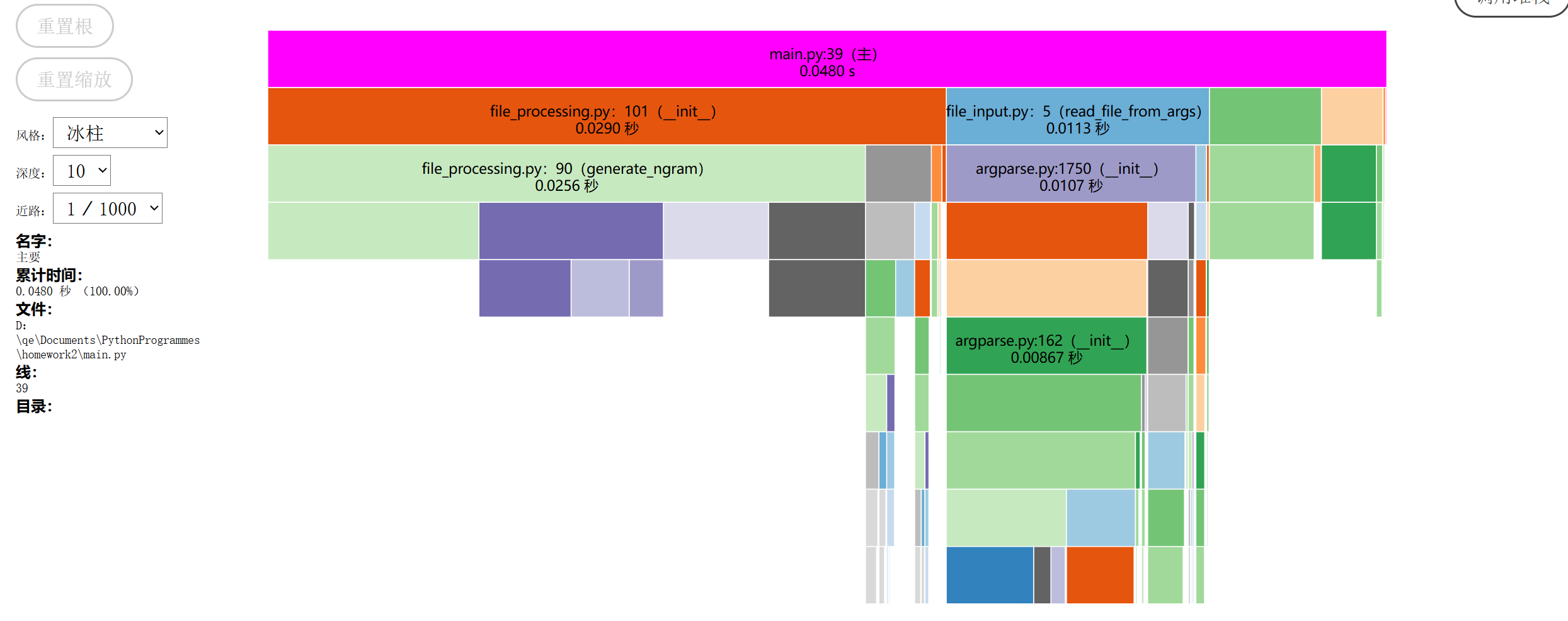
-
使用性能分析图形化插件snakeviz生成
![]()
-
性能消耗
file_processing.py中进行的文本标准化,分词,n-gram生成等操作涉及到大量循环调用与文件读写,占用CPU最多,时间开销最大- 使用混合n-gram策略,在计算jccard相似度时涉及较多的浮点计算,计算时间较长
-
改进方案
- 采用多线程模块
threading并发处理文本 - 优化n-gram生成策略,增加更多n-gram混合策略以适配长度不同的文本
- 采用第三方库进行分词,提升精确度的同时减少耗时
- 采用多线程模块
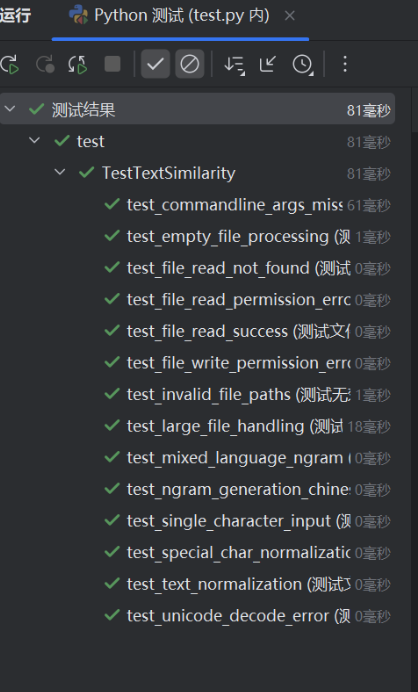
单元测试
-
主要单元测试结果
![]()
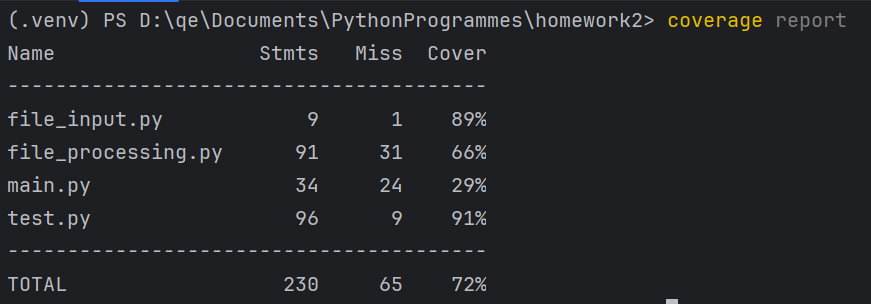
-
单元测试覆盖率
![]()
测试文件处理系统在处理大文件时的效率
- 通过代码生成1mb以上的文本文件
- 进行文本处理并记录处理时间
def test_large_file_handling(self):
large_content = 'a' * 1024 * 1024
large_path = os.path.join(self.test_dir.name, 'large.txt')
with open(large_path, 'w') as f:
f.write(large_content)
import time
start = time.time()
fp = FileProcessor([large_path])
processing_time = time.time() - start
self.assertLess(processing_time, 2)
测试特殊字符的处理
- 输入各种特殊字符测试文本的标准化效果
def test_special_char_normalization(self):
"""测试特殊字符处理"""
fp = FileProcessor([os.path.join(self.test_dir.name, 'special_chars.txt')])
normalized = list(fp.paths_normalized_pairs.values())[0]
self.assertEqual(normalized, [])
异常处理
- 由于用户在输入文件时存在较多不确定性,因此主要的异常处理面向文件读写的异常而设计
测试文件不存在异常
def test_file_read_not_found(self):
with self.assertRaises(FileNotFoundError):
file_read('non_existent_file.txt')
错误场景:用户传入错误的文件地址或该文件不存在
测试文件权限异常
def test_file_read_permission_error(self):
if os.name == 'posix':
path = os.path.join(self.test_dir.name, 'no_permission.txt')
with open(path, 'w') as f:
f.write('test')
os.chmod(path, 0o222)
with self.assertRaises(PermissionError):
file_read(path)
错误场景:因程序运行的平台不同而导致的文件权限不足
测试写入权限异常
def test_file_write_permission_error(self):
if os.name == 'posix':
path = '/root/protected_file.txt'
with self.assertRaises(PermissionError):
file_write(path, "test data")
错误场景:因用户的意外设置而导致的文件写入权限异常
测试编码异常处理
def test_unicode_decode_error(self):
# 创建GBK编码文件
path = os.path.join(self.test_dir.name, 'gbk.txt')
with open(path, 'w', encoding='gbk') as f:
f.write('你好')
# 尝试用默认utf-8读取
content = file_read(path)
self.assertIsNone(content)
错误场景:文本编码格式错误
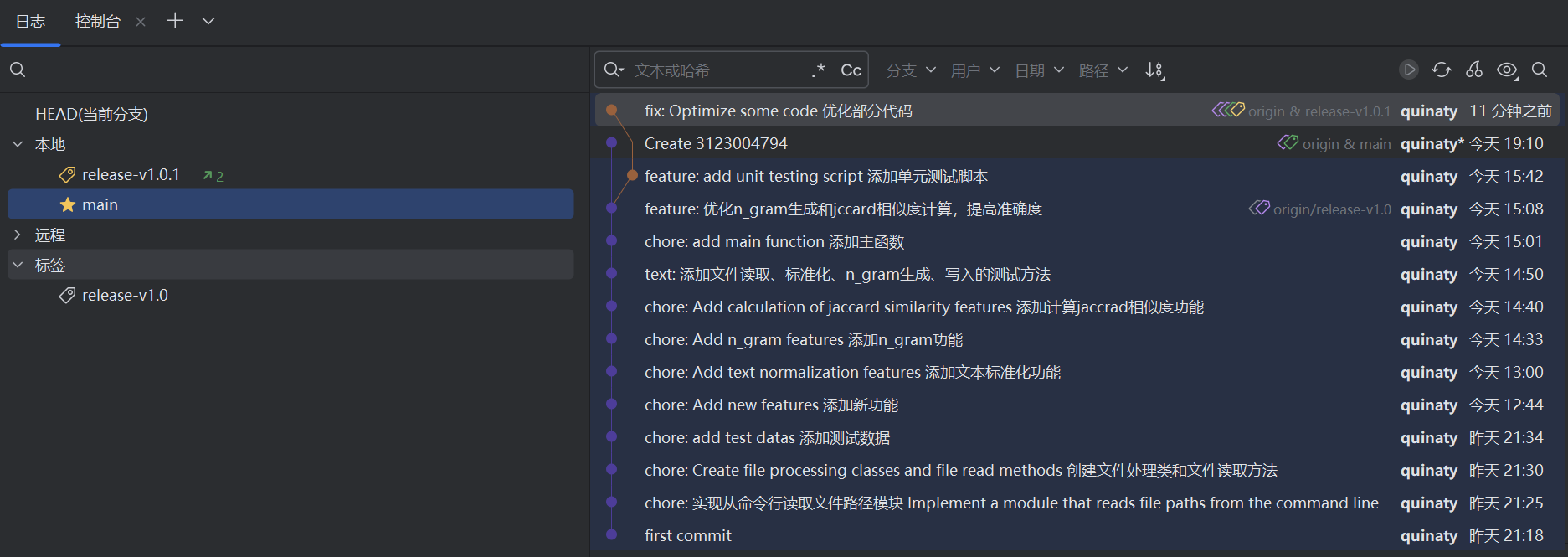
Git日志

 浙公网安备 33010602011771号
浙公网安备 33010602011771号