

软件工程-作业2:第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023 |
|---|---|
| 这个作业在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023/homework/13324 |
| 这个作业的目标 | 系统化流程地完成软件开发,使用性能测试工具和单元测试以优化程序 |
Github链接
https://github.com/RaoHush/3123004152
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 15 |
| Estimate | 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | ||
| Analysis | 需求分析(包括学习新技术) | 120 | 60 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 45 | 40 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 30 |
| Design | 具体设计 | 45 | 60 |
| Coding | 具体编码 | 220 | 200 |
| Code Review | 代码复审 | 60 | 45 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 60 | 120 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 45 |
| 合计 | 935 | 875 |
模块设计与实现
使用说明
从命令行参数给出:python main.py [原文文件绝对路径] [抄袭版论文的文件绝对路径] [答案文件绝对路径]
稍微修改过,抄袭版论文绝对路径可使用通配符模式,如"orig_0.8_*",可识别所有有此命名文件,并将结果统一输出。
核心函数解析
①文件读取 (read_file)
•流程:
1.使用UTF-8编码尝试读取文件
2.替换Unicode特殊空格(\u3000全角空格、\xa0不间断空格)
3.异常处理:文件不存在或权限问题时报错退出
•关键点:
1.errors='ignore':跳过非法字符,避免解码失败
2.统一空格格式:确保后续处理的文本一致性
②文本预处理 (preprocess)
•流程:
1.清洗:使用正则表达式去除非中文、字母、数字的字符
2.分词:结巴分词将文本切分为词语列表
3.过滤:移除长度≤1的词语(如标点、单字)
③ 相似度计算 (calc_similarity)
•流程:
1.初始化TF-IDF模型:token_pattern保留所有词语(默认过滤单字)
2.特征转换:将两文本合并拟合生成TF-IDF矩阵
3.相似度计算:使用余弦相似度比较两个向量
•注意点:
1.每次调用会新建TfidfVectorizer,导致重复拟合(性能瓶颈)
2.返回值限制在0.0~1.0之间(max(0.0, min(1.0, ...))在main中处理)
④主流程 (main)
•执行流程:
1.参数校验:必须传入3个参数(原文路径、抄袭文件模式、输出路径)
2.原文处理:读取原文并预处理为标准格式
3.文件匹配:
•直接路径:检查是否为有效文件
•通配符:使用glob.glob批量获取文件
4.遍历处理:
•读取抄袭文件 → 预处理 → 计算相似度 → 记录结果
5.结果写入:按文件名:评分格式输出到文件
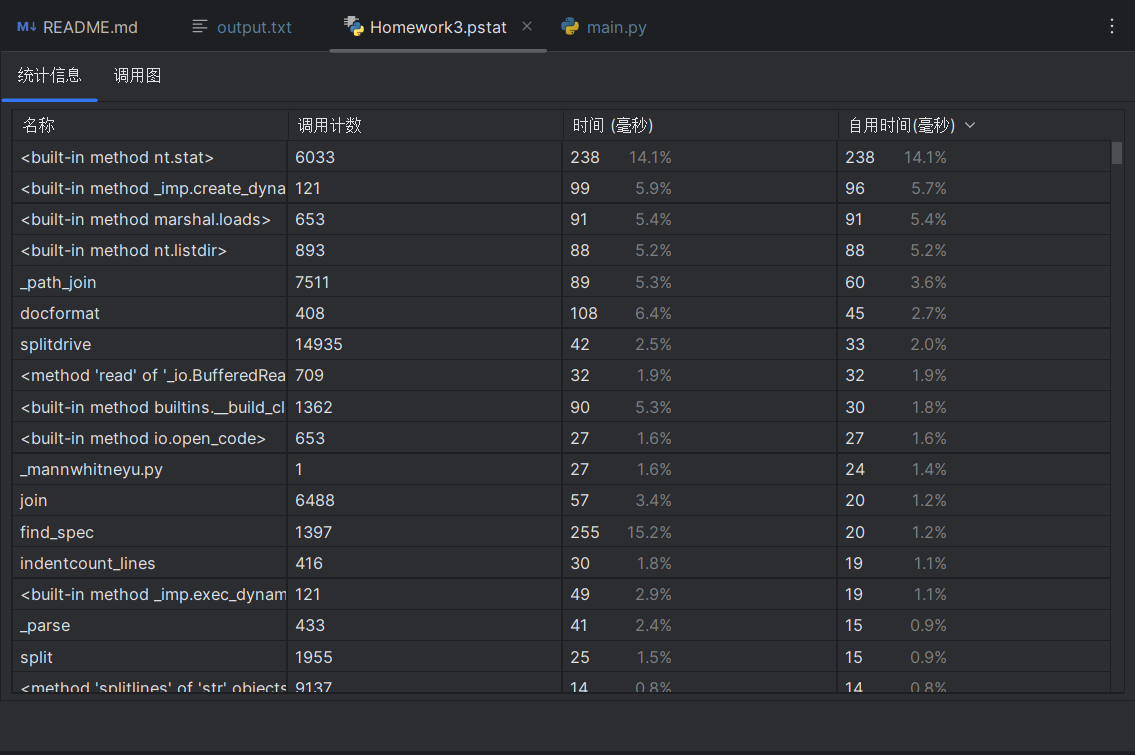
性能分析
性能消耗
每次计算相似度时都新建TfidfVectorizer,导致原文被重复处理。
逐个处理抄袭文件,无法利用多核CPU。
改进
优先实施TF-IDF模型复用
引入并行处理
性能分析图
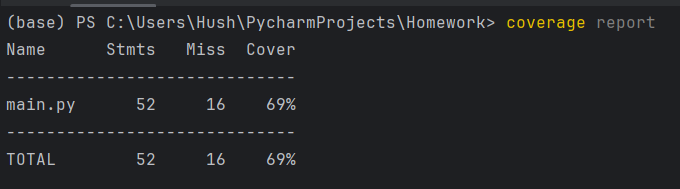
单元测试
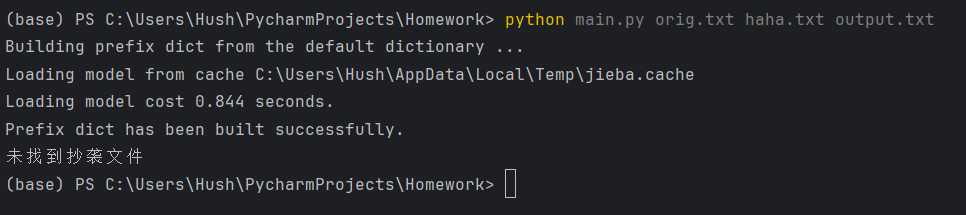
异常处理
1.传输文章不存在
2.错误编码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号