第九章
9.2
import numpy as np
from scipy.stats import kstest
data = np.array([15.0, 15.8, 15.2, 15.1, 15.9, 14.7, 14.8, 15.5,
15.6, 15.3, 15.1, 15.3, 15.0, 15.6, 15.7, 14.8,
14.5, 14.2, 14.9, 14.9, 15.2, 15.0, 15.3, 15.6,
15.1, 14.9, 14.2, 14.6, 15.8, 15.2, 15.9, 15.2,
15.0, 14.9, 14.8, 14.5, 15.1, 15.5, 15.5, 15.1,
15.1, 15.0, 15.3, 14.7, 14.5, 15.5, 15.0, 14.7,
14.6, 14.2])
sample_mean = 15.1
sample_variance = 0.4325 ** 2
ks_statistic, p_value = kstest(data, 'norm', args=(sample_mean, np.sqrt(sample_variance)))
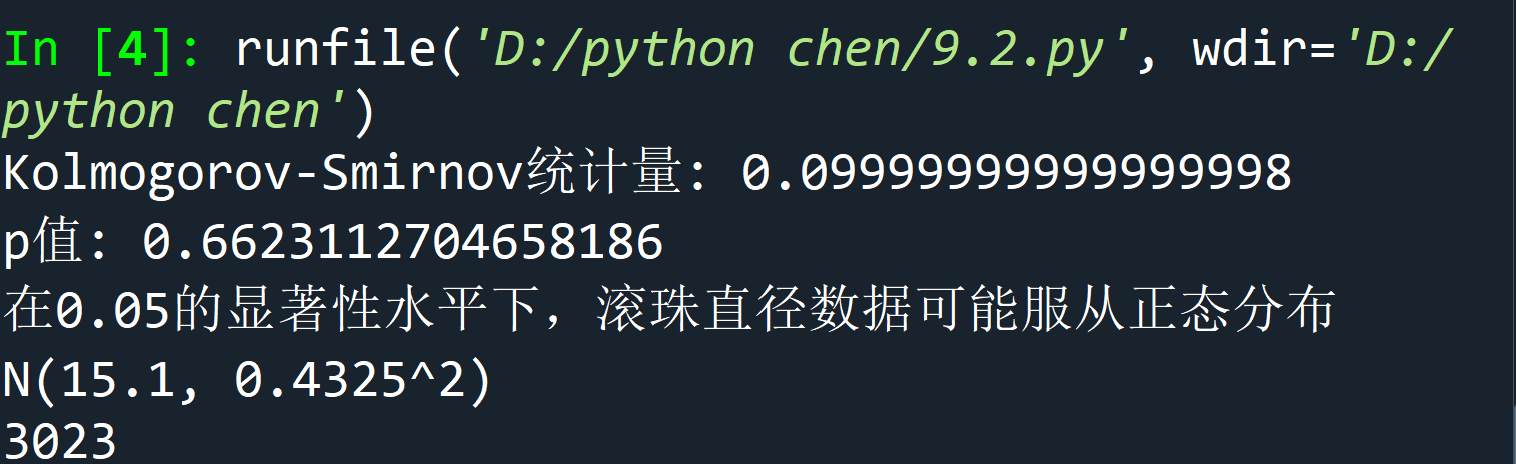
print("Kolmogorov-Smirnov统计量:", ks_statistic)
print("p值:", p_value)
if p_value > 0.05:
print("在0.05的显著性水平下,滚珠直径数据可能服从正态分布N(15.1, 0.4325^2)")
else:
print("在0.05的显著性水平下,滚珠直径数据不太可能服从正态分布N(15.1, 0.4325^2)")
print("3023")
结果
9.3(1)
import matplotlib.pyplot as plt
import numpy as np
lst = [4.13, 3.86, 4.00, 3.88, 4.02, 4.02, 4.00,
4.07, 3.85, 4.02, 3.88, 3.95, 3.86, 4.02,
4.04, 4.08, 4.01, 3.91, 4.02, 3.96, 4.03,
4.07, 4.11, 4.01, 3.95, 3.89, 3.97, 4.04,
4.05, 4.08, 4.04, 3.92, 3.91, 4.00, 4.10,
4.04, 4.01, 3.99, 3.97, 4.01, 3.82, 3.81,
4.02, 4.02, 4.03, 3.92, 3.89, 3.98, 3.91,
4.06, 4.04, 3.97, 3.90, 3.89, 3.99, 3.96,
4.10, 3.97, 3.98, 3.97, 3.99, 4.02, 4.05,
4.04, 3.95, 3.98, 3.90, 4.0, 3.93, 4.06]
data = []
for i in range(7):
data.append([lst[j * 7 + i] for j in range(len(lst) // 7)])
labs = ["lab1", "lab2", "lab3", "lab4", "lab5", "lab6", "lab7"]
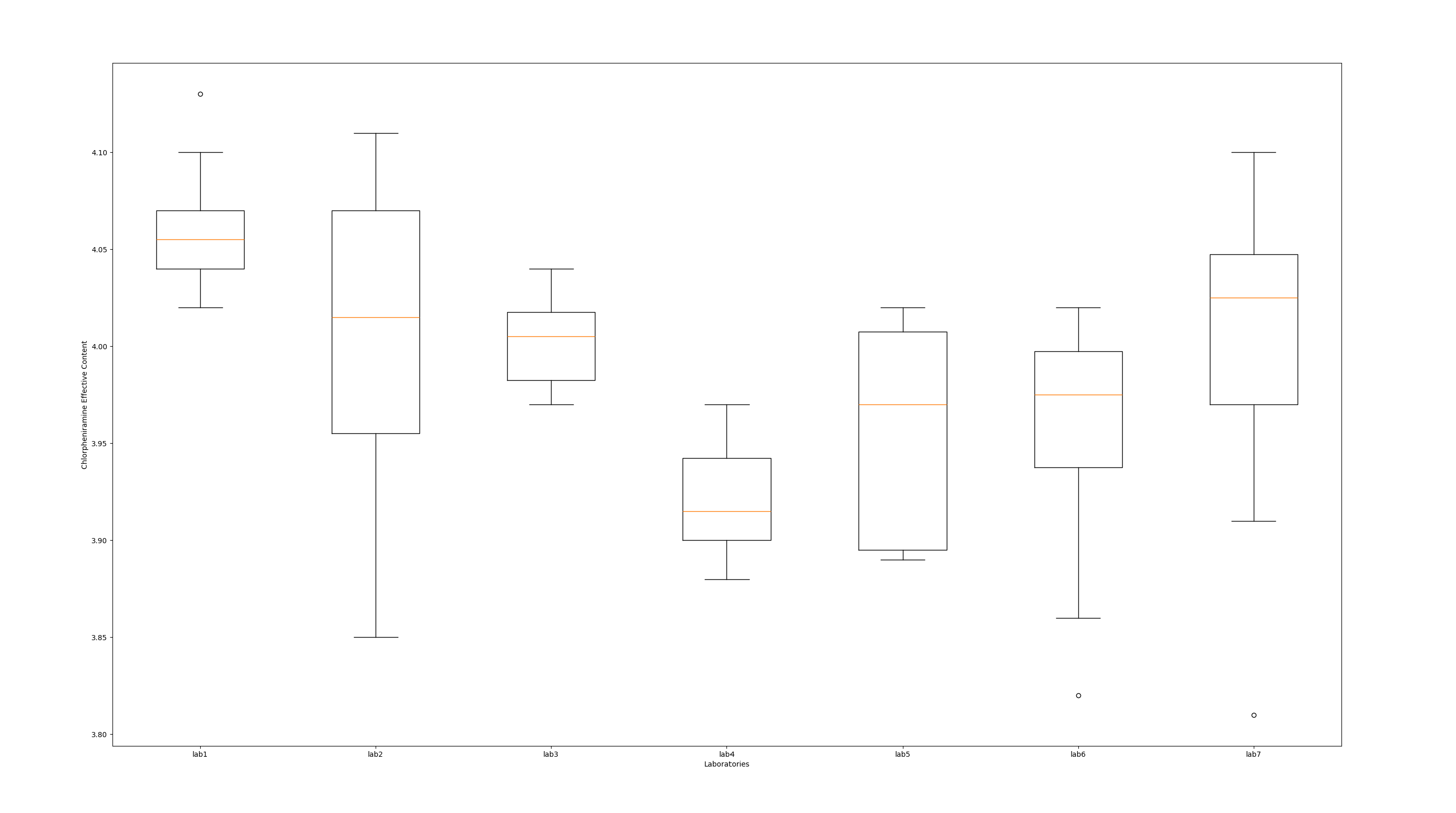
plt.figure(figsize=(10, 6))
plt.boxplot(data, labels=labs)
plt.xlabel("Laboratories")
plt.ylabel("Chlorpheniramine Effective Content")
plt.show()
print("3023")
结果
9.3(2)
import numpy as np
from scipy.stats import f
data = []
lst = [4.13, 3.86, 4.00, 3.88, 4.02, 4.02, 4.00,
4.07, 3.85, 4.02, 3.88, 3.95, 3.86, 4.02,
4.04, 4.08, 4.01, 3.91, 4.02, 3.96, 4.03,
4.07, 4.11, 4.01, 3.95, 3.89, 3.97, 4.04,
4.05, 4.08, 4.04, 3.92, 3.91, 4.00, 4.10,
4.04, 4.01, 3.99, 3.97, 4.01, 3.82, 3.81,
4.02, 4.02, 4.03, 3.92, 3.89, 3.98, 3.91,
4.06, 4.04, 3.97, 3.90, 3.89, 3.99, 3.96,
4.10, 3.97, 3.98, 3.97, 3.99, 4.02, 4.05,
4.04, 3.95, 3.98, 3.90, 4.0, 3.93, 4.06]
for i in range(7):
data.append([lst[j * 7 + i] for j in range(len(lst) // 7)])
n = len(data[0])
N = 7 * n
x_bar_i = [np.mean(data[i]) for i in range(7)]
x_bar = np.mean([x for sublist in data for x in sublist])
SST = 0
SSA = 0
for i in range(7):
for x in data[i]:
SST += (x - x_bar) ** 2
SSA += n * (x_bar_i[i] - x_bar) ** 2
SSE = SST - SSA
df_T = N - 1
df_A = 7 - 1
df_E = df_T - df_A
MSA = SSA / df_A
MSE = SSE / df_E
F = MSA / MSE
alpha = 0.05
f_critical = f.ppf(1 - alpha, df_A, df_E)
if F > f_critical:
print("在0.05的显著性水平下,各实验室测量的扑尔敏有效含量的均值有显著差异")
else:
print("在0.05的显著性水平下,各实验室测量的扑尔敏有效含量的均值没有显著差异")
print("3023")
结果

9.4
import numpy as np
from scipy.stats import f
data = np.array([[[173, 172, 173],
[174, 176, 178],
[177, 179, 176],
[172, 173, 174]],
[[175, 173, 176],
[178, 177, 179],
[174, 175, 173],
[170, 171, 172]],
[[177, 175, 176],
[174, 174, 175],
[174, 173, 174],
[169, 169, 170]]])
r, s, t = data.shape
n = r * s * t
y_bar_ij = np.mean(data, axis=2)
y_bar_i_dot = np.mean(y_bar_ij, axis=1)
y_bar_dot_j = np.mean(y_bar_ij, axis=0)
y_bar_dot_dot = np.mean(data)
SST = 0
SSA = 0
SSB = 0
SSAB = 0
for i in range(r):
for j in range(s):
for k in range(t):
SST += (data[i, j, k] - y_bar_dot_dot) ** 2
SSAB += t * ((y_bar_ij[i, j] - y_bar_i_dot[i] - y_bar_dot_j[j] + y_bar_dot_dot) ** 2)
for i in range(r):
SSA += s * t * ((y_bar_i_dot[i] - y_bar_dot_dot) ** 2)
for j in range(s):
SSB += r * t * ((y_bar_dot_j[j] - y_bar_dot_dot) ** 2)
SSE = SST - SSA - SSB - SSAB
df_T = n - 1
df_A = r - 1
df_B = s - 1
df_AB = df_A * df_B
df_E = df_T - df_A - df_B - df_AB
MSA = SSA / df_A
MSB = SSB / df_B
MSAB = SSAB / df_AB
MSE = SSE / df_E
F_A = MSA / MSE
F_B = MSB / MSE
F_AB = MSAB / MSE
alpha = 0.05
f_critical_A = f.ppf(1 - alpha, df_A, df_E)
f_critical_B = f.ppf(1 - alpha, df_B, df_E)
f_critical_AB = f.ppf(1 - alpha, df_AB, df_E)
print("品种对应的F分布表临界值:", f_critical_A)
print("品种对应的F分布表临界值:", f_critical_B)
print("品种对应的F分布表临界值:", f_critical_AB)
if F_A > f_critical_A:
print("品种对小麦产量有显著影响")
else:
print("品种对小麦产量无显著影响")
if F_B > f_critical_B:
print("化肥对小麦产量有显著影响")
else:
print("化肥对小麦产量无显著影响")
if F_AB > f_critical_AB:
print("品种和化肥的交互作用对小麦产量有显著影响")
else:
print("品种和化肥的交互作用对小麦产量无显著影响")
print("3023")
结果

9.5
import pandas as pd
import numpy as np
from pingouin import anova
data = np.array([[955, 967, 960, 980],
[927, 949, 950, 930],
[905, 930, 910, 920],
[855, 860, 880, 875],
[880, 890, 895, 900],
[860, 840, 850, 830],
[870, 865, 850, 860],
[830, 850, 840, 830],
[875, 888, 900, 892],
[870, 850, 847, 965],
[870, 863, 845, 855],
[821, 842, 832, 848]])
df = pd.DataFrame(data)
df.columns = ['组合 1', '组合 2', '组合 3', '组合 4']
locations = np.repeat(['市中心黄金地段', '非中心地段', '城乡结合部'], 4)
advertisements = np.tile(np.repeat(['广告形式 1', '广告形式 2'], 2), 3)
decorations = np.tile(['装潢档次 1', '装潢档次 2'] * 3, 2)
df['地理位置'] = locations
df['广告形式'] = advertisements
df['装潢档次'] = decorations
df_melted = df.melt(id_vars=['地理位置', '广告形式', '装潢档次'], var_name='城市号', value_name='销售量')
anova_result = anova(dv='销售量', between=['地理位置', '广告形式', '装潢档次'], data=df_melted)
significant_factors = anova_result[anova_result['p-unc'] < 0.05]['Source'].tolist()
if len(significant_factors) > 0:
print(f"在显著水平 0.05 下,{', '.join(significant_factors)} 对销售量有显著差异。")
else:
print("在显著水平 0.05 下,各因素及交互作用对销售量均无显著差异。")
print("3023")
结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号