第一 第四次 第九次作业补交
1.为什么产生大数据技术?
(1)数据产生方式的改变(2)人类的活动越来越依赖数据(3)各行各业也越来越依赖大数据手段来开展工作
2.为什么要学习大数据技术?
近年来,科学技术快速发展,数据分析有着很重要的地位。随着大数据在生活中的实际应用,学习大数据有着广阔的就业和发展前景。
3.简述大数据、云计算、物联网、区块链和人工智能的概念和相互关系。
数字经济建设在数字新技术体系上,数字新技术主要包括物联网、云计算、大数据、人工智能、区块链等五大技术。根据数字化生产的要求,物联网技术为数字传输,云计算技术为数字设备,大数据技术为数字资源,人工智能技术为数字智能,区块链技术为数字信息,五大数字技术是一个整体,相互融合呈指数级增长,才能推动数字新经济的高速度高质量发展。
4.用图表和简单的文字简要描述大数据的发展前景和就业趋势,并谈谈你的看法。
大数据在我们日常生活中尤为重要,有着广阔的前景
趋势一:数据的资源化
趋势二:与云计算的深度结合
趋势三:科学理论的突破
趋势四:数据科学和数据联盟的成立
趋势五:数据泄露泛滥
趋势六:数据管理成为核心竞争力
趋势七:数据质量是BI(商业智能)成功的关键
趋势八:数据生态系统复合化程度加强
所以我觉得大数据对我们以后的就业和发展有很大的作用
5.大数据可能带来什么样的问题?如何应对这些隐患?
数据量大,对数据保护相对简单,容易造成数据泄露。
应对:一是加强大数据安全立法,明确数据安全主体责任。
二是抓住数据利用和共享合作等关键环节,加强数据安全监管执法。
三是强化技术手段建设,构建大数据安全保障技术体系。
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop起源于开源网络搜索引擎Apache Nutch
发展阶段:3篇论文
- GFS:Google File System 分布式处理系统 ------》解决存储问题
- Mapreduce:分布式计算模型 ------》对数据进行计算处理
- BigTable:解决查询分布式存储文件慢的问题,把所有的数据存入一张表中,通过牺牲空间换取时间
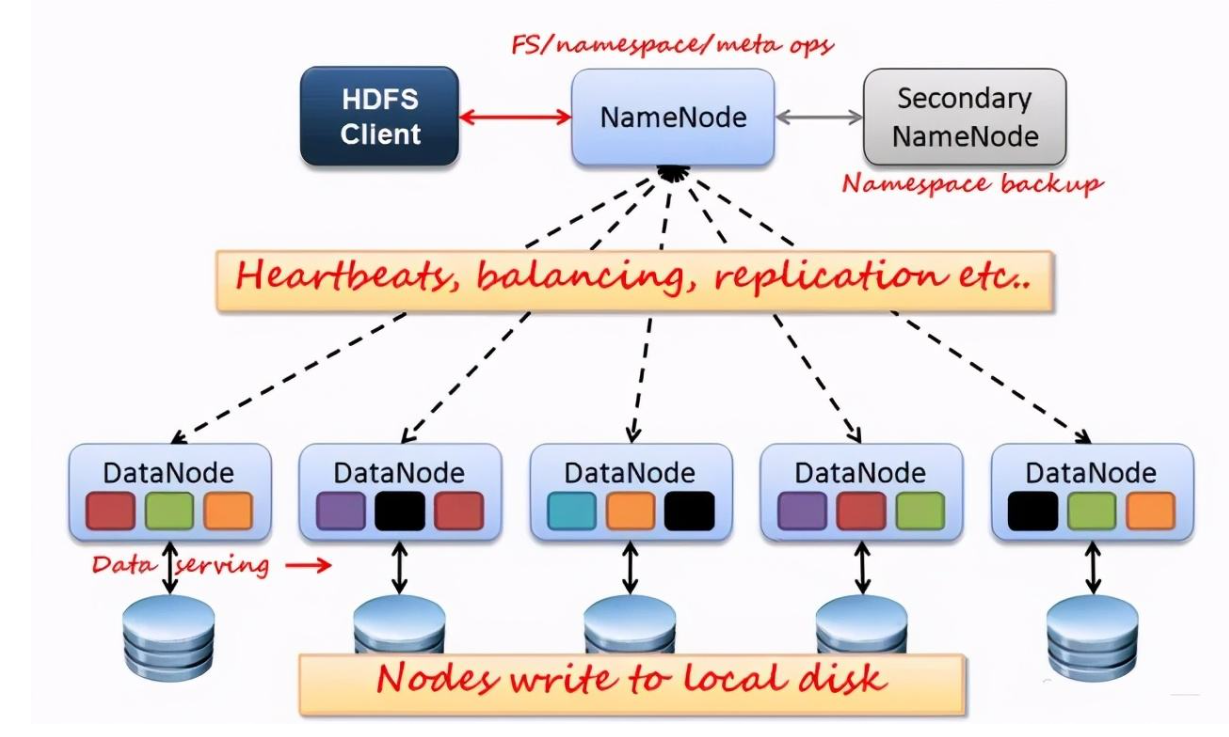
2.用图与自己的话,简要描述 名称节点、第二名称节点、数据节点 的主要功能及相互关系。
名称节点 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。
第二名称节点 为了有效解决EditLog逐渐变大带来的问题
数据节点 也是一个通常在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。
数据节点 响应来自 HDFS 客户机的读写请求。它们还响应来自 名称节点 的创建、删除和复制块的命令。名称节点 依赖来自每个 数据节点 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,名称节点 可以根据这个报告验证块映射和其他文件系统元数据。如果 数据节点 不能发送心跳消息,名称节点 将采取修复措施,重新复制在该节点上丢失的块
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
![]()
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
![]()
- 数据冗余
![]()
- 下载解压重命名权限
![]()
2.配置环境变量 $HIVE_HOME
![]()
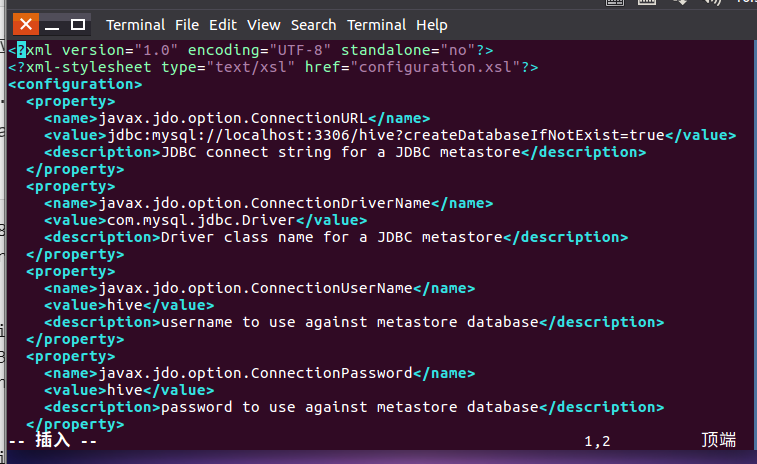
3.修改Hive配置文件 gedit
![]()
4.配置mysql驱动
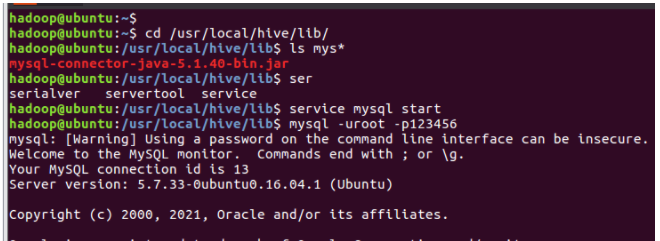
1.下载合适版本的mysql jar包,拷贝到/usr/local/hive/lib目录下 ls
![]()
2.在mysql新建hive数据库 show databases;
![]()
3.配置mysql允许hive接入 show grants for 'hive'@'localhost';
![]()
5.启停
启动Hadoop--启动Hive--退出Hive--停止Hadoop
![]()
二、Hive操作
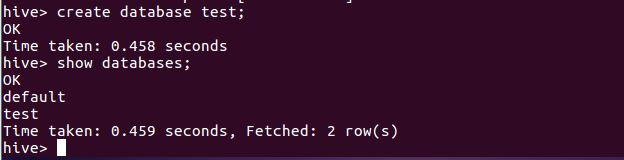
1.hive创建与查看数据库
![]()
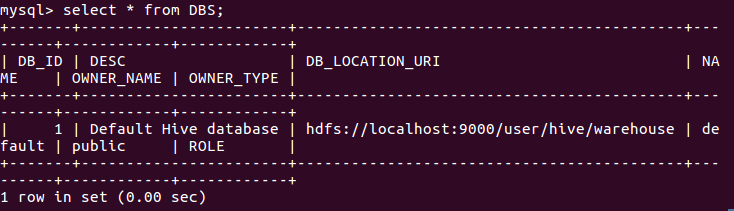
2.mysql查看hive元数据表DBS
![]()
3.hive创建与查看表
![]()
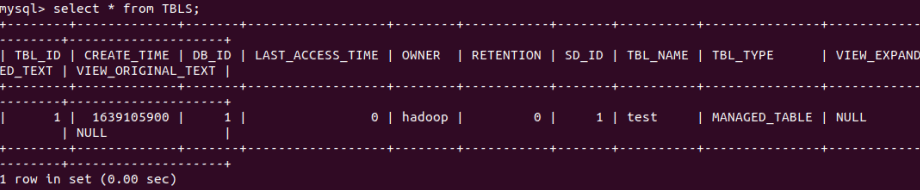
4.mysql查看hive元数据表TBLS
![]()
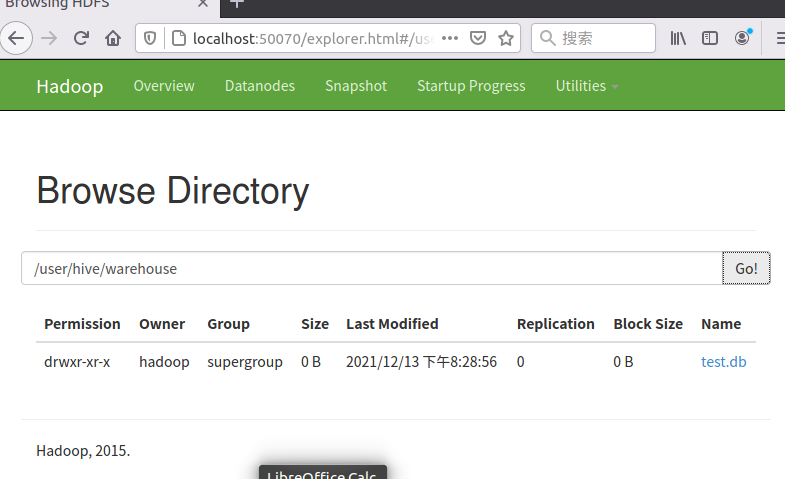
5.hdfs查看表文件位置
![]()
6.hive删除表
![]()
7.mysql查看hive元数据表TBLS
![]()
8.hive删除数据库
![]()
9.mysql查看hive元数据表DBS
![]()
三、hive进行词频统计
1.准备txt文件
![]()
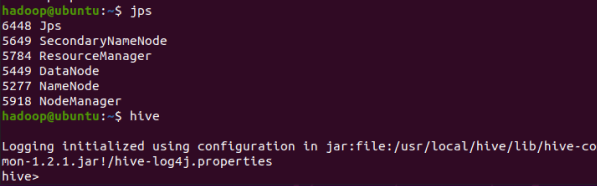
2.启动hadoop,启动hive
![]()
3.创建并查看文本表 create table
![]()
4.导入文件的数据到文本表中 load data local inpath
![]()
5.分割文本 split
![]()
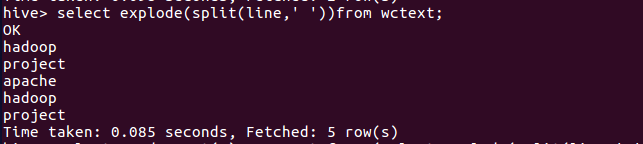
6.行转列explode
![]()
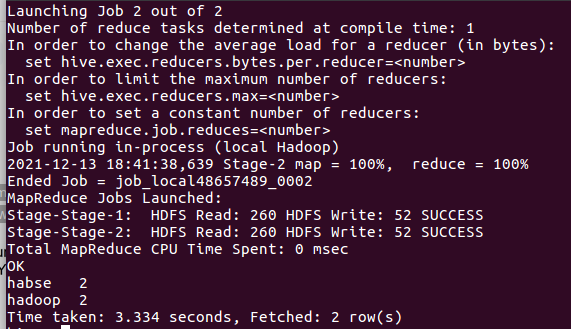
7.统计词频group by
![]()
-
- 数据存取策略
![]()
- 数据错误与恢复
![]()


















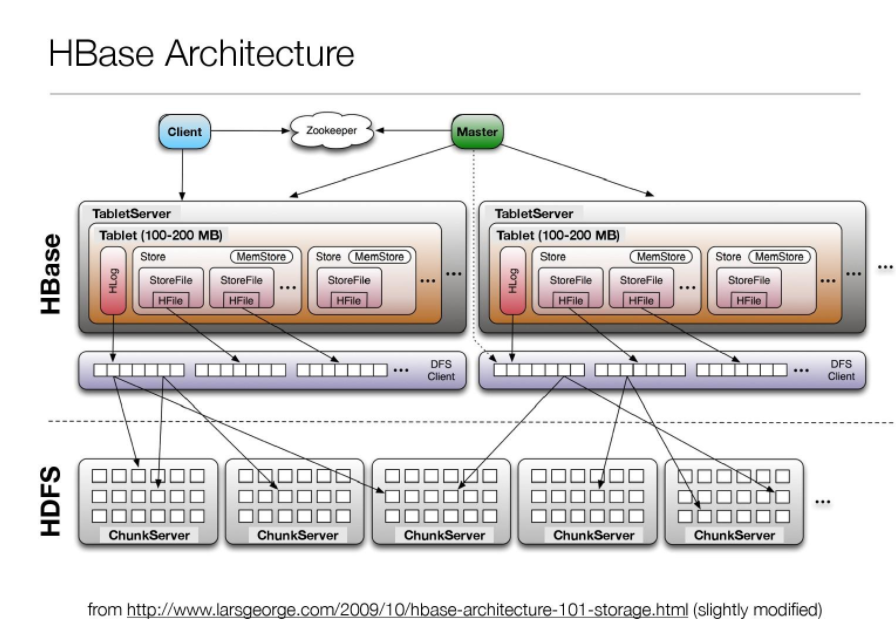
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联
![]()
5.理解并描述Hbase表与Region的关系。
一个HBase表最初只有一个region,当数据存满时,它会进行分裂
6.理解并描述Hbase的三级寻址。
HBase查询数据过程
第一层 zookeeper文件:记录了root表的位置
第二层 root表(根数据表): 记录了META表(元数据表)的Region的位置信息,root表只能有一个region
第三层 META表:记录了用户数据表的region的位置信息,META表可以有多个region,保存了Hbase所有用户数据表的region的位置信息
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
三层结构可以保存的region数目为:
(2GB/1KB) * (2GB/1KB) = = 2^40个region
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。

9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号