
numpy 读书笔记
import numpy as np print(np.__version__)#打印版本 a = np.zeros([3,2]) b = list(range(0,27)) b = np.array(b) b = b.reshape([3,3,3]) print("轴:",b.ndim)#轴的数量或维度的数量 print("形状",b.shape) print("大小",b.size) print("格式",b.dtype) #ndarray 初始值0,终止值100,最终包含最终值 a5 = np.linspace(1,20,num = 20,endpoint=True,retstep=True,dtype=np.float32)#等差:1为起始值,20为终止值。 #num默认样本数量为50,endpoint为ture时,数列中包含stop值, #restep为True时,生成的数组会显示间距 a6 = np.logspace(1,20,num=20) #等比 print(a6) a7 = np.random.random([3,3]) #[0,1) a8 = np.random.randn(3,3) #随机值是按照标准正态分布创建,算法数据模拟环境中 #print(help(np.random.randn())) print(a8) #切片[起始值:终止值:步长] b1 = np.array(range(0,15)).reshape([3,5]) print(b1)[] print(b1[1][1]) #b[行][列] print(b1[1,1]) #b[行,列] print(b1[:,-2:])#前两行前两列[] print(b1[:2, :]) b2 = np.ones([1,5]) print(b2) print(b1+b2)#广播机制 b3 = np.ones([3,4]) b4 = b3.reshape([2,-1])#-1表示配对前面的数 print(b4.ravel(),b4.ravel().shape)#展开数组,一维数据 print(b4.reshape(1,-1),b4.reshape(1,-1).shape)#一行10列 print(b4) c = np.arange(1,7).reshape([3,2]) print(c.transpose()) pritn(c.T)#转置 d = np.arange(10).reshape([-1,10]) print(d,d.shape) print(d.squeeze(),d.squeeze().shape) #压缩维度,将维度值为1的进行消除 e = d.reshape([5,-1,2]) print(e) print(e.squeeze()) f = np.ones([3,2]) g = np.zeros([3,2]) print(np.concatenate([f,g],axis=0))#按行拼接 print(np.hstack([f,g])) #行 print(np.concatenate([f,g],axis=1))#按列拼接 print(np.vstack([f,g]))#列 h = np.arange(0,9).reshape([3,3]) print(h) print(np.hsplit(h,3))#3代表将数组平分成几个 print(np.hsplit(h,[0]))#[1]按索引切分 #np.add()加法 #np.subtract()减法 #np.multiply()乘法 #np.divide()除法 #np.power()幂 #np.log2() #np.pi j = np.array([[1,5,6], [5,7,9], [9,0,1] ]) print(np.argmax(j))#最大值位置9 print(np.argmax(j,axis=1))#最大值行位置,横向比较。查找每行最大索引 print(np.argmax(j,axis=0))#最大值列位置,纵向比较。查找每列最大索引 print(np.argmin(j)) print(np.mean(j))#均值 print(np.mean(j,axis=0))#对列求均值 print(np.mean(j,axis=1))#对行求均值 print(np.sort(j))#排序 #np.dot() 两个数组的点积,即元素对应相乘 #np.inner()两个数组的内积 #np.matmul()矩阵乘法 #np.linalg.eig()特征值分解 m = np.zeros([3,3]) n = np.ones([3,3]) print(np.dot(m,n)) print(m.dot(n)) t = [1,2,3] y = [1,1,1] print(np.inner(t,y)) z = np.arange(1,10).reshape(3,3) print(z) vals,vecs = np.linalg.eig(z)#特征值和特征向量 print(vals) print(vecs)
Scipy依赖于Numpy
Scipy提供了真正的矩阵
Scipy包含的功能:最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解器等
Scipy是高端科学计算工具包
Scipy由一些特定功能的子模块组成
#模块用来计算快速傅里叶变换 import scipy.fftpack as fftpack import matplotlib.pyplot as plt %matplotlib inline #读取图片 data = plt.imread('moonlanding.png') # data2 = fftpack.fft2(data) data3 = np.where(np.abs(data2)>8e2,0,data2) data4 = fftpack.ifft2(data3) data5 = np.real(data4) plt.figure(figsize=(12,9)) plt.imshow(data5,cmap = 'gray')
根据线型绘制图片
numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值。
numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中。
numpy.random.standard_normal(size=None):随机一个浮点数或N维浮点数组,标准正态分布随机样本
cumsum :计算轴向元素累加和,返回由中间结果组成的数组 , 重点就是返回值是“由中间结果组成的数组”
plt.plot(np.random.randn(1000).cumsum(), linestyle = ':',marker = '.', label='one') plt.plot(np.random.randn(1000).cumsum(), 'r--', label='two') plt.plot(np.random.randn(1000).cumsum(), 'b.', label='three') plt.legend(loc='best') # loc='best' plt.show()
scipy积分求圆周率
f = lambda x : (1 - x**2)**0.5 import numpy as np import matplotlib.pyplot as plt x = np.linspace(-1,1,1000) plt.figure(figsize = (4,4)) plt.plot(x,f(x),'-',x,-f(x),'-',color = 'r')
使用Scipy.integrate.quad()来进行计算
#integrate.quad(函数,区间端点) ,返回值为面积与精度 from scipy import integrate def g(x): return (1- x**2)**0.5 area,err = integrate.quad(g,-1,1) print(area,err)
scipy文件的输入与输出
保存二进制文件
from scipy import io as spio import numpy as np a = np.ones((3,3)) #mat文件是标准的二进制文件 spio.savemat('./data/file.mat',mdict={'a':a})
读取图片
from scipy import misc data = misc.imread('./data/moon.png')
读取保存的文件
data = spio.loadmat('./data/file.mat') data['a']
保存图片
#模糊,轮廓,细节,edge_enhance,edge_enhance_more, 浮雕,find_edges,光滑,smooth_more,锐化 misc.imsave('./data/save.png',arr=data)
一、pandas常用功能及函数简介
导入相关的包
一般我们需要做如下导入,numpy和pandas一般需要联合使用:
import pandas as pd
import numpy as np
本文采用如下缩写:
df:Pandas DataFrame对象
s: Pandas Series对象
数据导入
- pd.read_csv(filename):从CSV文件导入数据
- pd.read_table(filename):从限定分隔符的文本文件导入数据
- pd.read_excel(filename):从Excel文件导入数据
- pd.read_sql(query, connection_object):从SQL表/库导入数据
- pd.read_json(json_string):从JSON格式的字符串导入数据
- pd.read_html(url):解析URL、字符串或者HTML文件
- pd.read_clipboard():从粘贴板获取内容
- pd.DataFrame(dict):从字典对象导入数据
数据导出
l df.to_csv(filename):导出数据到CSV文件
l df.to_excel(filename):导出数据到Excel文件
l df.to_sql(table_name, connection_object):导出数据到SQL表
l df.to_json(filename):以Json格式导出数据到文本文件
创建对象
pd.DataFrame(np.random.rand(20,5)):创建20行5列的随机数组成的DataFrame对象
pd.Series(my_list):从可迭代对象my_list创建一个Series对象
df.index = pd.date_range('1900/1/30', periods=df.shape[0]):增加一个日期索引
index和reindex联合使用很有用处,index可作为索引并且元素乱排序之后,所以跟着元素保持不变,因此,当重拍元素时,只需要对index进行才重排即可:reindex。
另外, reindex时,还可以增加新的标为NaN的元素。
数据查看
df.head(n):查看DataFrame对象的前n行
df.tail(n):查看DataFrame对象的最后n行
df.shape():查看行数和列数
df.describe():查看数值型列的汇总统计
s.value_counts(dropna=False):查看Series对象的唯一值和计数
df.apply(pd.Series.value_counts):查看DataFrame对象中每一列的唯一值和计数
apply的用处很多,比如可以通过跟lambda函数联合,完成很多功能:将包含某个部分的元素挑出来等等。
pandas
①导入模块
import pandas as pd # 这里用到的是pandas和numpy两个模块
import numpy as np
②创建数据集
我构造了一个超市购物的数据集,该数据集属性包括:订单ID号(id)、订单日期(date)、消费金额(money)、订单商品(product)、商品类别(department)、商品产地(origin)。
# 列表和字典均可传入DataFrame,我这里用的是字典传入: data=pd.DataFrame({ "id":np.arange(101,111), # np.arange会自动输出范围内的数据,这里会输出101~110的id号。 "date":pd.date_range(start="20200310",periods=10), # 输出日期数据,设置周期为10,注意这里的周期数应该与数据条数相等。 "money":[5,4,65,-10,15,20,35,16,6,20], # 设置一个-10的坑,下面会填(好惨,自己给自己挖坑,幸亏不准备跳~) "product":['苏打水','可乐','牛肉干','老干妈','菠萝','冰激凌','洗面奶','洋葱','牙膏','薯片'], "department":['饮料','饮料','零食','调味品','水果',np.nan,'日用品','蔬菜','日用品','零食'], # 再设置一个空值的坑 "origin":['China',' China','America','China','Thailand','China','america','China','China','Japan'] # 再再设置一个america的坑 }) data # 输出查看数据集
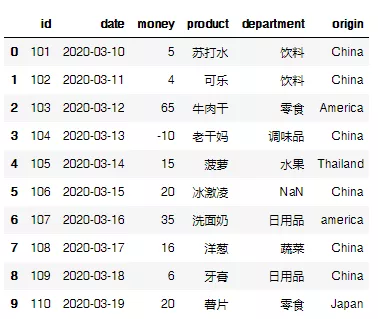
③空格处理
for i in data: # 遍历数据集中的每一列 if pd.api.types.is_object_dtype(data[i]): # 如果是object类型的数据,则执行下方代码 data[i]=data[i].str.strip() # 去除空格 data['origin'].unique() # 验证一下
输出结果:array([‘China’, ‘America’, ‘Thailand’, ‘america’, ‘Japan’], dtype=object)
matplotlib学习笔记
画图:常用参数
kind='line/bar……',
ax=None,
figsize=None,
title=None,
grid=None, # 网格 True/False
legend=False, # 图例
style=None, # 包括linestyle, marker, color,例:style='k--.'
xticks=None, # x轴刻度
yticks=None, # y轴刻度
xlim=None, # x坐标的范围
ylim=None, # y坐标的范围
rot=None, # label旋转角度,推荐rot=0
use_index=True, # 是否用Series/DataFrame的索引,默认True, 不然就[0, 1, 2....]
alpha=None,
fontsize=None,
colormap=None,
label=None,
table=None,
yerr=None,
xerr=None,
secondary_y=False,
**kwds
plt.plot() # plot
x , y, color, marker, linestyle, linewidth, markersizex,y为数据的位置,x,y分别为数组,len(x)=len(y)
marker为点的图形,下面有官方marker style链接
linestyle为线的样式:
'-' 要么 'solid' 实线
'--' 要么 'dashed' 虚线
'-.' 要么 'dashdot' 点划线
':' 要么 'dotted' 虚线markersize为marker的尺寸大小
color:
b blue
g green
r red
c cyan
m magenta
y yellow
k black
w white
plt.scatter() # 散点图
x, y, color/c, marker, alpha, linewidthsx,y为数据的位置,x,y分别为数组,len(x)=len(y)
marker为点的图形,下面有官方marker style链接
alpha为透明度
linewidths为marker边缘的线宽
plt.pie() # 饼图
x, explode, labels, color, autopct, pctdistance, labeldistance, shadow, startangle, radius, framex为一串数组,是饼图的值
explode为某个(些)块炸出中心的大小,也是一串数组
labels为字符串数组s.index
colors为字符串或者数组['r', 'g', 'b']
autopct为百分比'%.2f%%'
pctdistanct为前者离中距离0.6
labeldistance为label离边框距离
frame为图框
x, y, height, left, align(默认center,edge可选)x为一串数组,数组长度为条形的数量
y为一串数组,是对应x的值
height为bar的高
left为条的左侧的x坐标,默认是0
plt.barh() # 水平条形图
x, y, height, left, align(默认center,edge可选)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号