
笔记
2019-10-05 11:38 小明来喽 阅读(122) 评论(0) 收藏 举报改大小写,直接改或用upper,lower
元组:俗称不可变的列表,又被成为只读列表,元祖也是python的基本数据类型之一,用小括号括起来,里面可以放任何数据类型的数据,查询可以,循环也可以,切片也可以.但就是不能改.
2.5.1 元组的索引切片
tu1 = ('a', 'b', '太白', 3, 666) print(tu1[0]) # 'a' print(tu1[-1]) # 666 print(tu1[1:3]) # ('b', '太白') print(tu1[:-1]) # ('a', 'b', '太白', 3) print(tu1[::2]) # ('a', '太白', 666) print(tu1[::-1]) # (666, 3, '太白', 'b', 'a')
2 元组其他操作方法
因为元组的特性,直接从属于元组的元素不能更改,所以元组只能查看。
# 可以利用for循环查询
tu1 = ('a', 'b', '太白', 3, 666)
for i in tu1:
print(i)
index:通过元素找索引(可切片),找到第一个元素就返回,找不到该元素即报错。
tu = ('太白', [1, 2, 3, ], 'WuSir', '女神') print(tu.index('太白')) # 0
count: 获取某元素在列表中出现的次数
tu = ('太白', '太白', 'WuSir', '吴超') print(tu.count('太白')) # 2
len
tu1 = (1,2,3,4,84,5,2,8,2,11,88,2) print(len(tu1)) 结果: 12
字典dict:
不可变(可哈希)的数据类型:int,str,bool,tuple。
可变(不可哈希)的数据类型:list,dict,set。
字典是Python语言中的映射类型,他是以{}括起来,里面的内容是以键值对的形式储存的:
Key: 不可变(可哈希)的数据类型.并且键是唯一的,不重复的。
Value:任意数据(int,str,bool,tuple,list,dict,set),包括后面要学的实例对象等。
增:
# 通过键值对直接增加 dic = {'name': '太白', 'age': 18} dic['weight'] = 75 # 没有weight这个键,就增加键值对 print(dic) # {'name': '太白', 'age': 18, 'weight': 75} dic['name'] = 'barry' # 有name这个键,就成了字典的改值 print(dic) # {'name': 'barry', 'age': 18, 'weight': 75}

 删
删
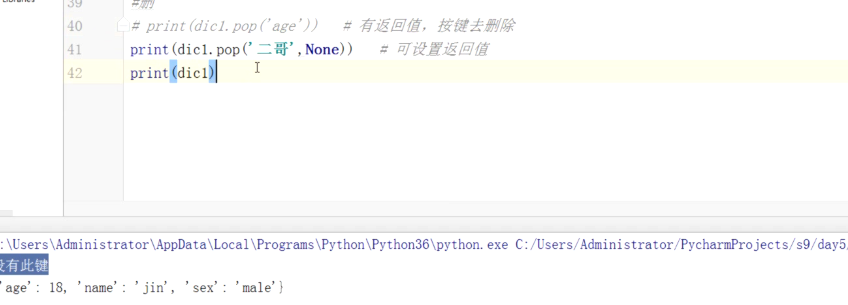
删:
# pop 通过key删除字典的键值对,有返回值,可设置返回值。 dic = {'name': '太白', 'age': 18} # ret = dic.pop('name') # print(ret,dic) # 太白 {'age': 18} ret1 = dic.pop('n',None) print(ret1,dic) # None {'name': '太白', 'age': 18} #popitem 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值 dic = {'name': '太白', 'age': 18} ret = dic.popitem() print(ret,dic) # ('age', 18) {'name': '太白'} #clear 清空字典 dic = {'name': '太白', 'age': 18} dic.clear() print(dic) # {} # del # 通过键删除键值对 dic = {'name': '太白', 'age': 18} del dic['name'] print(dic) # {'age': 18} #删除整个字典 del dic
 什么都不写,默认打印的是键
什么都不写,默认打印的是键
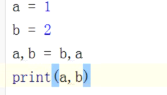 a,b值互换
a,b值互换
# 通过键查询 # 直接dic[key](没有此键会报错) dic = {'name': '太白', 'age': 18} print(dic['name']) # 太白 # get dic = {'name': '太白', 'age': 18} v = dic.get('name') print(v) # '太白' v = dic.get('name1') print(v) # None v = dic.get('name2','没有此键') print(v) # 没有此键 keys() dic = {'name': '太白', 'age': 18} print(dic.keys()) # dict_keys(['name', 'age']) values() dic = {'name': '太白', 'age': 18} print(dic.values()) # dict_values(['太白', 18]) items() dic = {'name': '太白', 'age': 18} print(dic.items()) # dict_items([('name', '太白'), ('age', 18)])
小数据池: 在一定范围内节省内存空间,共用一个数据
在一定范围内节省内存空间,共用一个数据
ascii
A : 00000010 8位 一个字节
unicode A : 00000000 00000001 00000010 00000100 32位 四个字节
中:00000000 00000001 00000010 00000110 32位 四个字节
utf-8 A : 00100000 8位 一个字节
中 : 00000001 00000010 00000110 24位 三个字节 去表示一个字符
gbk A : 00000110 8位 一个字节
中 : 00000010 00000110 16位 两个字节
1,各个编码之间的二进制,是不能互相识别的,会产生乱码。
2,文件的储存,传输,不能是unicode(只能是utf-8 utf-16 gbk,gb2312,asciid等)
py3:
str 在内存中是用unicode编码。
bytes类型
对于英文:
str :表现形式:s = 'alex'
编码方式: 010101010 unicode
bytes :表现形式:s = b'alex'
编码方式: 000101010 utf-8 gbk。。。。
对于中文:
str :表现形式:s = '中国'
编码方式: 010101010 unicode
bytes :表现形式:s = b'x\e91\e91\e01\e21\e31\e32'
编码方式: 000101010 utf-8 gbk。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号