
CUDA ---- Stream and Event
Stream
一般来说,cuda c并行性表现在下面两个层面上:
- Kernel level
- Grid level
到目前为止,我们讨论的一直是kernel level的,也就是一个kernel或者一个task由许多thread并行的执行在GPU上。Stream的概念是相对于后者来说的,Grid level是指多个kernel在一个device上同时执行。
Stream和event简介
Cuda stream是指一堆异步的cuda操作,他们按照host代码调用的顺序执行在device上。Stream维护了这些操作的顺序,并在所有预处理完成后允许这些操作进入工作队列,同时也可以对这些操作进行一些查询操作。这些操作包括host到device的数据传输,launch kernel以及其他的host发起由device执行的动作。这些操作的执行总是异步的,cuda runtime会决定这些操作合适的执行时机。我们则可以使用相应的cuda api来保证所取得结果是在所有操作完成后获得的。同一个stream里的操作有严格的执行顺序,不同的stream则没有此限制。
由于不同stream的操作是异步执行的,就可以利用相互之间的协调来充分发挥资源的利用率。典型的cuda编程模式我们已经熟知了:
- 将输入数据从host转移到device
- 在device上执行kernel
- 将结果从device上转移回host
在许多情况下,花费在执行kernel上的时间要比传输数据多得多,所以很容易想到将cpu和gpu之间传输数据时间隐藏在其他kernel执行过程中,我们可以将数据传输和kernel执行放在不同的stream中来实现此功能。Stream可以用来实现pipeline和双buffer(front-back)渲染。
Cuda API可分为同步和异步两类,同步函数会阻塞host端的线程执行,异步函数会立刻将控制权返还给host从而继续执行之后的动作。异步函数和stream是grid level并行的两个基石。
从软件角度来看,不同stream中的不同操作可以并行执行,但是硬件角度却不一定如此。这依赖于PCIe链接或者每个SM可获得的资源,不同的stream仍然需要等待别的stream来完成执行。下面会简单介绍在不同CC版本下,stream在device上的行为。
Cuda Streams
所有的cuda操作(包括kernel执行和数据传输)都显式或隐式的运行在stream中,stream也就两种类型,分别是:
- 隐式声明stream(NULL stream)
- 显示声明stream(non-NULL stream)
默认情况下是NULL stream,在之前未涉及到stream的博文中,都是该类型。如果显式的声明一个stream就是non-NULL stream了。
异步且基于stream的kernel执行和数据传输能够实现以下几种类型的并行:
- Host运算操作和device运算操作并行
- Host运算操作和host到device的数据传输并行
- Host到device的数据传输和device运算操作并行
- Device内的运算并行
下面代码是之前常见的使用形式,默认使用NULL stream:
cudaMemcpy(..., cudaMemcpyHostToDevice); kernel<<<grid, block>>>(...); cudaMemcpy(..., cudaMemcpyDeviceToHost);
从device角度看,所有者三个操作都是使用的默认stream,并且按照代码从上到下的顺序依次执行,device本身是不知道其他的host操作怎样执行的。从host角度来看,数据传输都是同步的并且会一直等待,直到操作完成。不过不同于数据传输,Kernel的launch是异步的,host差不多立刻就能重新得到控制权,不用管kernel是否执行完毕,从而进行下一步动作。很明显,这种异步行为有助于重叠device和host之间的运算时间。
上文内容在之前博文都有涉及,这里特别说明的是数据传输,它也是可以异步执行的,这就用到了本次讲的stream,我们必须显示的声明一个stream来分派它的执行。下面版本是异步版本的cudaMemcpy:
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = 0);
注意新增加的最后一个参数。这样,在host issue了这个函数给device执行后,控制权可以立刻返还给host。上面代码使用了默认stream,如果要声明一个新的stream则使用下面的API定义一个:
cudaError_t cudaStreamCreate(cudaStream_t* pStream);
这样就定义了一个可以使用在cuda异步API函数中stream。使用该函数的一个比较常见的错误,或者说容易引起混乱的地方是,这个函数返回的error code可能是上一次调用异步函数产生的。也就是说,函数返回error并不是调用该函数产生error的必要条件。
当执行一次异步数据传输时,我们必须使用pinned(或者non-pageable)memory。Pinned memory的分配如下,具体请参见前面博文:
cudaError_t cudaMallocHost(void **ptr, size_t size); cudaError_t cudaHostAlloc(void **pHost, size_t size, unsigned int flags);
通过在将该内存pin到host的虚拟内存上,就可以将该memory的物理位置强制分配到CPU内存中以便使之在整个程序生命周期中保持不变。否则的话,操作系统可能会在任意时刻改变该host端的虚拟内存对应的物理地址。假设异步数据传输函数没有使用pinned host memory的话,操作系统就可能将数据从一块物理空间移动到另一块物理空间(因为是异步的,CPU在执行其他的动作就可能影响这块数据),而此时cuda runtime正在执行数据的传输,这会导致不确定的行为。
在执行kernel时要想设置stream的话,也是很简单的,同样只要加一个stream参数就好:
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);
// 非默认的stream声明 cudaStream_t stream; // 初始化 cudaStreamCreate(&stream); // 资源释放 cudaError_t cudaStreamDestroy(cudaStream_t stream);
当执行资源释放的时候,如果仍然有stream的工作没干完,那么虽然该函数仍然会立刻返回,但是相关的工作做完后,这些资源才会自动的释放掉。
由于所有stram的执行都是异步的,就需要一些API在必要的时候做同步操作:
cudaError_t cudaStreamSynchronize(cudaStream_t stream);
cudaError_t cudaStreamQuery(cudaStream_t stream);
第一个会强制host阻塞等待,直至stream中所有操作完成为止;第二个会检查stream中的操作是否全部完成,即使有操作没完成也不会阻塞host。如果所有操作都完成了,则返回cudaSuccess,否则返回cudaErrorNotReady。
下面看一下一个代码片段来帮助理解:
for (int i = 0; i < nStreams; i++) { int offset = i * bytesPerStream; cudaMemcpyAsync(&d_a[offset], &a[offset], bytePerStream, streams[i]); kernel<<grid, block, 0, streams[i]>>(&d_a[offset]); cudaMemcpyAsync(&a[offset], &d_a[offset], bytesPerStream, streams[i]); } for (int i = 0; i < nStreams; i++) { cudaStreamSynchronize(streams[i]); }
该段代码使用了三个stream,数据传输和kernel运算都被分配在了这几个并发的stream中。
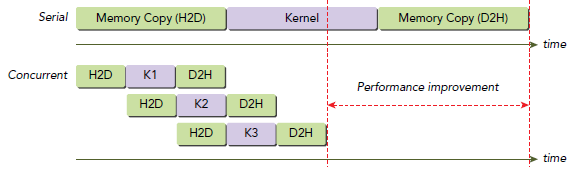
上图就跟流水线一样差不多的道理,不多说。需要注意的是,上图中数据传输的操作并不是并行执行的,即使他们是在不同的stream中。按惯例,这种情况肯定就是硬件资源的锅了,硬件资源就那么些,软件层面做的优化无非就是尽量让所有硬件资源一刻不停的被利用起来(万恶的资本主义,嗯……),而这里就是PCIe卡了瓶颈。当然从编程角度来看,这些操作依然是相互独立的,只是他们要共享硬件资源,就不得不是串行的。有两个PCIe就可以重叠这两次数据传输操作,不过也是要保证不同的stream和不同的传输方向。
最大并发kernel数目是依赖于device本身的,Fermi支持16路并行,Kepler是32。并行数是受限于shared memory,寄存器等device资源。
Stream Scheduling
概念上来说,所有stream是同时运行的。但是,事实上通常并非如此。
False Dependencies
尽管Fermi最高支持16路并行,但是在物理上,所有stream是被塞进硬件上唯一一个工作队列来调度的,当选中一个grid来执行时,runtime会查看task的依赖关系,如果当前task依赖前面的task,该task就会阻塞,由于只有一个队列,后面的都会跟着等待,即使后面的task是别的stream上的任务。就如下图所示:
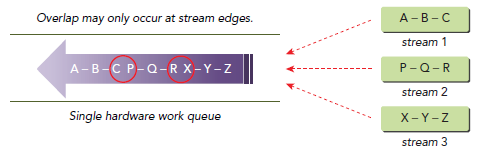
C和P以及R和X是可以并行的,因为他们在不同的stream中,但是ABC,PQR以及XYZ却不行,比如,在B没完成之前,C和P都在等待。
Hyper-Q
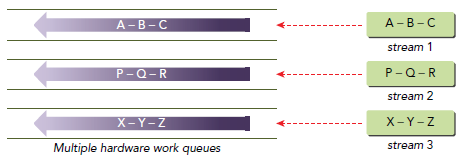
伪依赖的情况在Kepler系列里得到了解决,采用的一种叫Hyper-Q的技术,简单粗暴的理解就是,既然工作队列不够用,那就增加好了,于是Kepler上出现了32个工作队列。该技术也实现了TPC上可以同时运行compute和graphic的应用。当然,如果超过32个stream被创建了,依然会出现伪依赖的情况。
Stream Priorities
对于CC3.5及以上版本,stream可以有优先级的属性:
cudaError_t cudaStreamCreateWithPriority(cudaStream_t* pStream, unsigned int flags, int priority);
该函数创建一个stream,赋予priority的优先级,高优先级的grid可以抢占低优先级执行。不过优先级属性只对kernel有效,对数据传输无效。此外,如果设置的优先级超出了可设置范围,则会自动设置成最高或者最低。有效可设置范围可用下列函数查询:
cudaError_t cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority);
顾名思义,leastPriority是下限,gretestPriority是上限。老规矩,数值较小则拥有较高优先级。如果device不支持优先级设置,则这两个值都返回0。
Cuda Events
Event是stream相关的一个重要概念,其用来标记strean执行过程的某个特定的点。其主要用途是:
- 同步stream执行
- 操控device运行步调
Cuda api提供了相关函数来插入event到stream中和查询该event是否完成(或者叫满足条件?)。只有当该event标记的stream位置的所有操作都被执行完毕,该event才算完成。关联到默认stream上的event则对所有的stream有效。
Creation and Destruction
// 声明 cudaEvent_t event; // 创建 cudaError_t cudaEventCreate(cudaEvent_t* event); // 销毁 cudaError_t cudaEventDestroy(cudaEvent_t event);
同理streeam的释放,在调用该函数的时候,如果相关操作没完成,则会在操作完成后自动释放资源。
Recording Events and Mesuring Elapsed Time
Events标记了stream执行过程中的一个点,我们就可以检查正在执行的stream中的操作是否到达该点,我们可以把event当成一个操作插入到stream中的众多操作中,当执行到该操作时,所做工作就是设置CPU的一个flag来标记表示完成。下面函数将event关联到指定stream。
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);
等待event会阻塞调用host线程,同步操作调用下面的函数:
cudaError_t cudaEventSynchronize(cudaEvent_t event);
该函数类似于cudaStreamSynchronize,只不过是等待一个event而不是整个stream执行完毕。我们同时可以使用下面的API来测试event是否完成,该函数不会阻塞host:
cudaError_t cudaEventQuery(cudaEvent_t event);
该函数类似cudaStreamQuery。此外,还有专门的API可以度量两个event之间的时间间隔:
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop);
返回start和stop之间的时间间隔,单位是毫秒。Start和stop不必关联到同一个stream上,但是要注意,如果二者任意一个关联到了non-NULL stream上,时间间隔可能要比期望的大。这是因为cudaEventRecord是异步发生的,我们没办法保证度量出来的时间恰好就是两个event之间,所以只是想要gpu工作的时间间隔,则stop和strat都关联到默认stream就好了。
下面代码简单展示了如何使用event来度量时间:
// create two events cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); // record start event on the default stream cudaEventRecord(start); // execute kernel kernel<<<grid, block>>>(arguments); // record stop event on the default stream cudaEventRecord(stop); // wait until the stop event completes cudaEventSynchronize(stop); // calculate the elapsed time between two events float time; cudaEventElapsedTime(&time, start, stop); // clean up the two events cudaEventDestroy(start); cudaEventDestroy(stop);
Stream Synchronization
由于所有non-default stream的操作对于host来说都是非阻塞的,就需要相应的同步操作。
从host的角度来看,cuda操作可以被分为两类:
- Memory相关的操作
- Kernel launch
Kernel launch对于host来说都是异步的,许多memory操作则是同步的,比如cudaMemcpy,但是,cuda runtime也会提供异步函数来执行memory操作。
我们已经知道Stream可以被分为同步(NULL stream)和异步(non-NULL stream)两种,同步异步是针对host来讲的,异步stream不会阻塞host的执行,而大多数同步stream则会阻塞host,不过kernel launch例外,不会阻塞host。
此外,异步stream又可以被分为阻塞和非阻塞两种,阻塞非阻塞是异步stream针对同步stream来讲的。异步stream如果是阻塞stream,那么同步stream会阻塞该异步stream中的操作。如果异步stream是非阻塞stream,那么该stream不会阻塞同步stream中的操作(有点绕……)。
阻塞和非阻塞stream
使用cudaStreamCreate创建的是阻塞stream,也就是说,该stream中执行的操作会被早先执行的同步stream阻塞。通常来说,当issue一个NULL stream时,cuda context会等待之前所有阻塞stream完成后才执行该NULL stream,当然所有阻塞stream也会等待之前的NULL stream完成才开始执行。
例如:
kernel_1<<<1, 1, 0, stream_1>>>(); kernel_2<<<1, 1>>>(); kernel_3<<<1, 1, 0, stream_2>>>();
从device角度来说,这三个kernel是串行依次执行的,当然从host角度来说,却是并行非阻塞的。除了通过cudaStreamCreate生成的阻塞stream外,我们还可以通过下面的API配置生成非阻塞stream:
cudaError_t cudaStreamCreateWithFlags(cudaStream_t* pStream, unsigned int flags); // flag为以下两种,默认为第一种,非阻塞便是第二种。 cudaStreamDefault: default stream creation flag (blocking) cudaStreamNonBlocking: asynchronous stream creation flag (non-blocking)
如果之前的kernel_1和kernel_3的stream被定义成第二种,就不会被阻塞。
Implicit Synchronization
Cuda有两种类型的host和device之间同步:显式和隐式。我们之前已经了解到显式同步API有:
- cudaDeviceSynchronize
- cudaStreamSynchronize
- cudaEventSynchronize
这三个函数由host显式的调用,在device上执行。
隐式同步我们也了解过,比如cudaMemcpy就会隐式的同步device和host,因为该函数同步作用只是数据传输的副作用,所以称为隐式。了解这些隐式同步是很中要的,因为不经意的调用这样一个函数可能会导致性能急剧降低。
隐式同步是cuda编程中比较特殊情况,因为隐式同步行为可能会导致意外的阻塞行为,通常发生在device端。许多memory相关的操作都会影响当前device的操作,比如:
- A page-locked host memory allocation
- A device memory allocation
- A device memset
- A memory copy between two addresses on the same device
- A modification to the L1/shared memory confi guration
Explicit Synchronization
从grid level来看显式同步方式,有如下几种:
- Synchronizing the device
- Synchronizing a stream
- Synchronizing an event in a stream
- Synchronizing across streams using an event
我们可以使用之前提到过的cudaDeviceSynchronize来同步该device上的所有操作。该函数会导致host等待所有device上的运算或者数据传输操作完成。显而易见,该函数是个heavyweight的函数,我们应该尽量减少这类函数的使用。
通过使用cudaStreamSynchronize可以使host等待特定stream中的操作全部完成或者使用非阻塞版本的cudaStreamQuery来测试是否完成。
Cuda event可以用来实现更细粒度的阻塞和同步,相关函数为cudaEventSynchronize和cudaEventSynchronize,用法类似stream相关的函数。此外,cudaStreamWaitEvent提供了一种灵活的方式来引入stream之间的依赖关系:
cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event);
该函数会指定该stream等待特定的event,该event可以关联到相同或者不同的stream,对于不同stream的情况,如下图所示:

Stream2会等待stream1中的event完成后继续执行。
Configurable Events
Event的配置可用下面函数:
cudaError_t cudaEventCreateWithFlags(cudaEvent_t* event, unsigned int flags); cudaEventDefault cudaEventBlockingSync cudaEventDisableTiming cudaEventInterprocess
cudaEventBlockingSync说明该event会阻塞host。cudaEventSynchronize默认行为是使用CPU时钟来固定的查询event状态。使用cudaEventBlockingSync,调用线程会进入休眠,将控制权交给其他线程或者进程,直到event完成为止。但是这样会导致少量的CPU时钟浪费,也会增加event完成和唤醒线程的之间的时间消耗。
cudaEventDisableTiming指定event只能用来同步,并且不需要记录计时数据。这样扔掉记录时间戳的消耗可以提高cuudaStreamWaitEvent和cudaEventQuery的调用性能。
cudaEventInterprocess指定event可以被用来作为inter-process event。
NVIDIA CUDA板块:https://developer.nvidia.com/cuda-zone
CUDA在线文档:http://docs.nvidia.com/cuda/index.html#
转载原文注明:http://www.cnblogs.com/1024incn/p/5891051.html
填坑中~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号