数据采集与融合技术_实验一
-
作业①:
1)大学软工排名信息的爬取
– 要求:用urllib和re库方法定向爬取给定网址https://www.shanghairanking.cn/rankings/bcsr/2020/0812的数据。
– 输出信息:
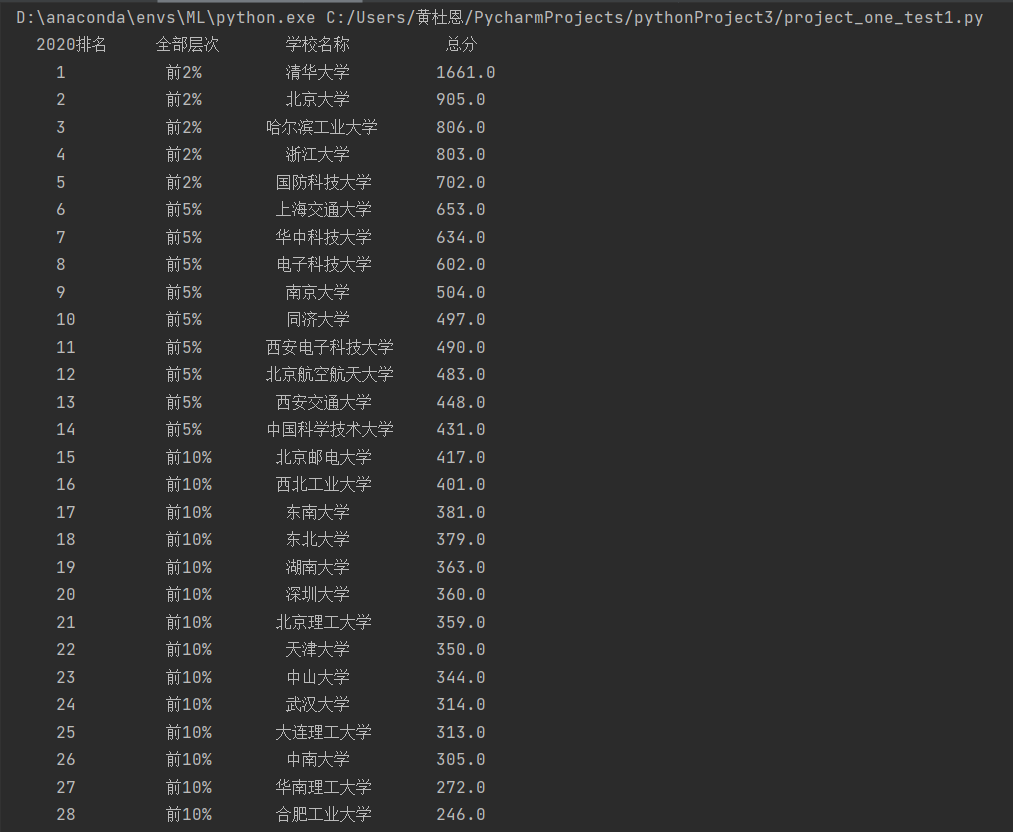
| 2020排名 | 全部层次 | 学校名称 | 总分 |
|---|---|---|---|
| 1 | 前2% | 清华大学 | 1661.0 |
完成过程:
1.向页面发送请求,获取源代码:
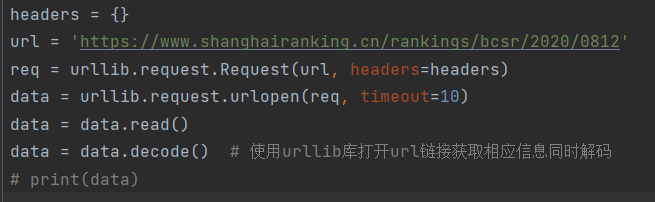
2.利用正则表达式匹配数据并存入相应列表:
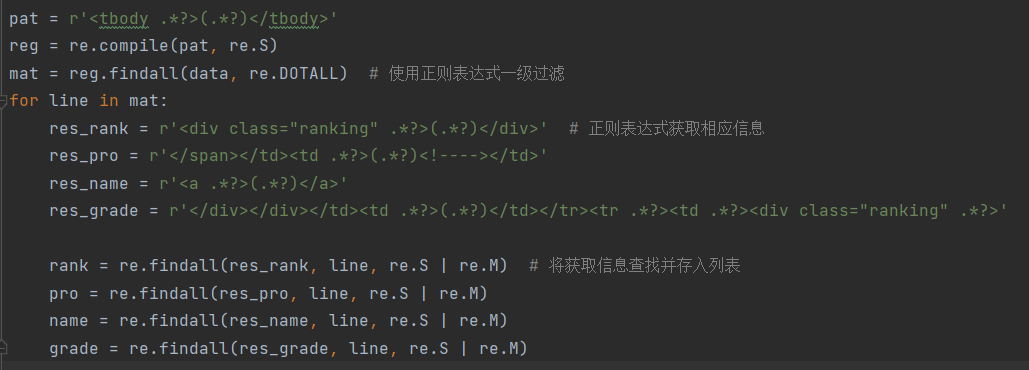
3.处理列表元素并打印:
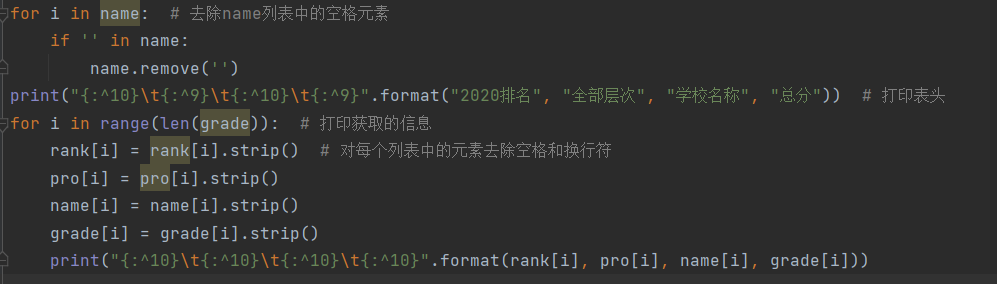
4.结果展示:
2)心得体会:此次作业老师只允许使用urllib和re库定向爬取网址,这对我们的正则表达式的使用熟练度有一定的要求。
所以通过这次实验我对正则表达式的理解更加的清晰,使用也更加的熟练。
-
作业②
1)城市实时空气质量信息的爬取
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/AQI实时报。
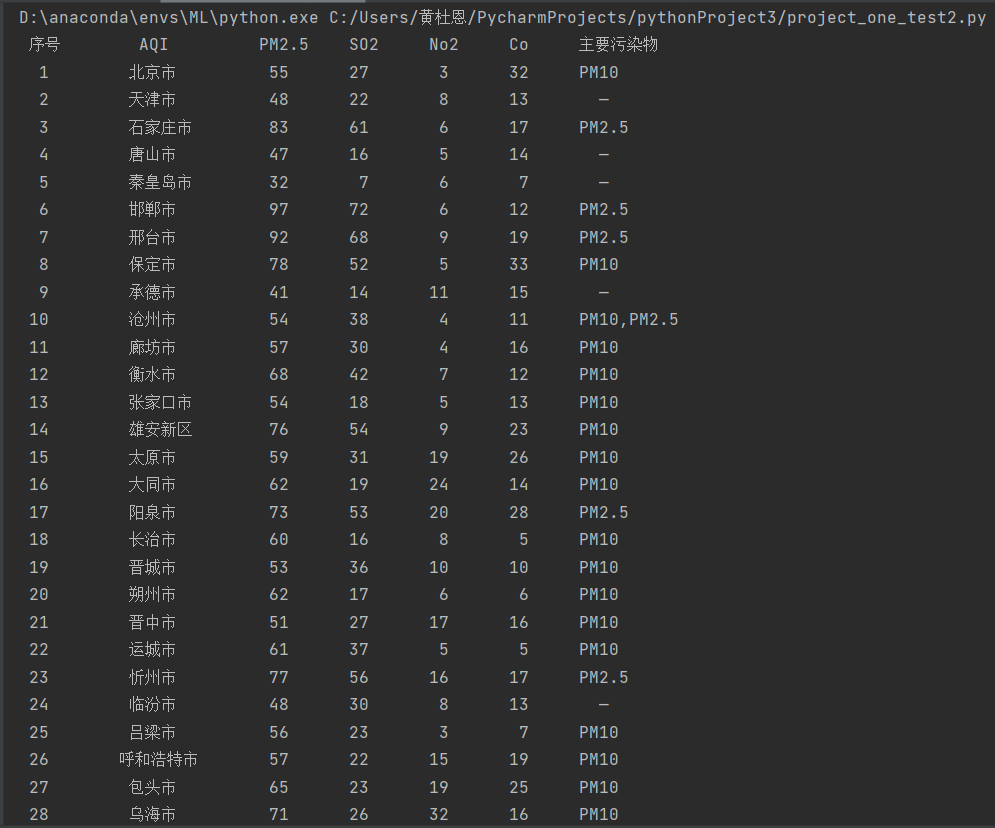
– 输出信息:序号 城市 AQI PM2.5 SO2 NO2 CO 首要污染物 1 北京市 55 6 5 1.0 225 —— 完成过程:
1.向页面发送请求,获取源代码:
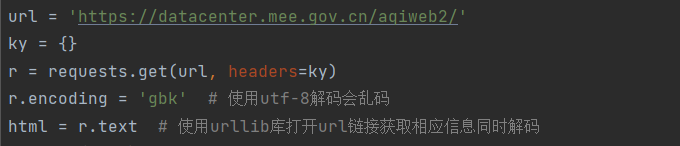
2.创建soup对象,匹配相应td节点

3.打印节点信息

4.结果展示:
2)心得体会:这题老师要求使用requests和Beautiful Soup库方法设计爬取网址信息。
通过此题的完成,我明白了Beautiful Soup库方法使用的便利,也熟练的掌握了css语法操作,同时也更加熟练的使用requests库的方法。 -
作业③
1)福大新闻网图片的爬取
– 要求:使用urllib和requests和re爬取一个给定网页https://news.fzu.edu.cn/爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中完成过程(urllib库):
1.向页面发送请求,获取源代码:

2.利用正则表达式匹配并获取图片下载链接:

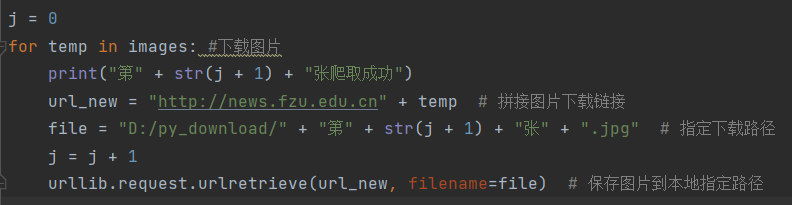
3.下载图片:
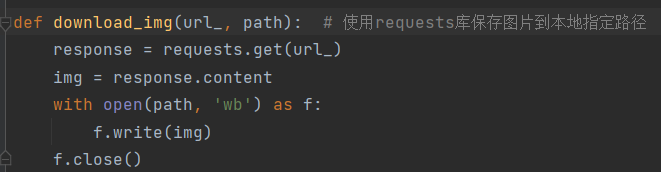
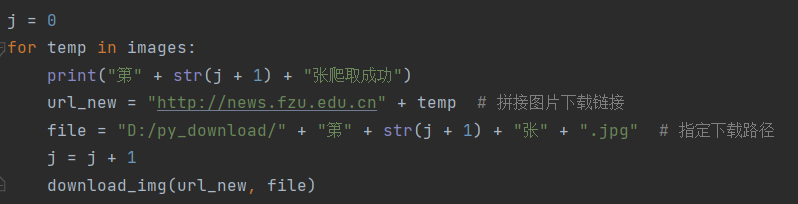
完成过程(requests库):
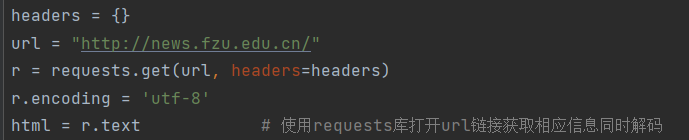
1.向页面发送请求,获取源代码:
2.利用正则表达式匹配图片下载链接:

3.下载图片:
4.结果展示:

2)心得体会:此题老师要求使用urllib和requests和re库爬取一个给定网址的图片信息。
通过此题实践,我掌握了从网页上保存图片至本地的urllib方法和requests方法,同时也对正则表达式的使用更加的熟练。 -
附录
