
102302116_田自豪_作业4
- 作业1
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
核心代码如下:
点击查看代码
import time
import csv
import os
import requests
import json
# 板块配置
SECTORS = {
'hs_a': {'name': '沪深A股', 'url': 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'},
'sh_a': {'name': '上证A股', 'url': 'http://quote.eastmoney.com/center/gridlist.html#sh_a_board'},
'sz_a': {'name': '深证A股', 'url': 'http://quote.eastmoney.com/center/gridlist.html#sz_a_board'}
}
class StockCrawlerCSV:
def __init__(self):
# 创建输出目录
self.output_dir = 'stock_data_csv'
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
# 设置请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36',
'Referer': 'https://quote.eastmoney.com/',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
def crawl_stock_data(self, sector_key):
sector = SECTORS[sector_key]
print(f"开始爬取{sector['name']}数据...")
try:
# 使用东方财富网的API获取数据
# 根据板块设置不同的筛选参数
fs_params = {
'hs_a': 'fs=m:0+t:6,m:1+t:80,m:0+t:81,s:2048', # 沪深A股
'sh_a': 'fs=m:1+t:80', # 上证A股
'sz_a': 'fs=m:0+t:6,m:0+t:81' # 深证A股
}
fs = fs_params[sector_key]
url = f"http://74.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405150756357253318_1625091600000&pn=1&pz=50&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&{fs}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
print(f"正在调用API: {url}")
# 禁用gzip压缩以避免乱码问题
headers_no_gzip = self.headers.copy()
headers_no_gzip['Accept-Encoding'] = 'identity'
response = requests.get(url, headers=headers_no_gzip, timeout=30)
response.encoding = 'utf-8'
print(f"API响应状态码: {response.status_code}")
print(f"响应内容长度: {len(response.text)}字符")
try:
# 处理JSONP响应
jsonp_data = response.text
print(f"响应前100字符: {jsonp_data[:100]}...")
print(f"响应后100字符: {jsonp_data[-100:]}...")
# 去除JSONP的包装
if '(' in jsonp_data and ')' in jsonp_data:
json_data = jsonp_data[jsonp_data.index('(') + 1: jsonp_data.rindex(')')]
else:
print("响应不是有效的JSONP格式,尝试直接解析为JSON")
json_data = jsonp_data
# 解析JSON数据
data = json.loads(json_data)
print(f"API返回状态: {data.get('rc')}, 消息: {data.get('rt')}")
print(f"是否有数据: {'data' in data and data['data'] is not None}")
if 'data' in data and data['data']:
# 提取数据
items = data['data']['diff']
print(f"成功获取{len(items)}条{sector['name']}数据")
# 准备CSV文件
csv_file_path = os.path.join(self.output_dir, f'{sector_key}_stocks.csv')
fieldnames = ['序号', '股票代码', '股票名称', '最新报价', '涨跌幅', '涨跌额', '成交量', '成交额', '振幅', '最高', '最低', '今开', '昨收']
with open(csv_file_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 解析并存储每行数据
for i, item in enumerate(items):
try:
# 提取数据
stock_data = {
'序号': i + 1,
'股票代码': item['f12'],
'股票名称': item['f14'],
'最新报价': item['f2'],
'涨跌幅': f"{item['f3']}%",
'涨跌额': item['f4'],
'成交量': item['f5'],
'成交额': item['f6'],
'振幅': f"{item['f7']}%",
'最高': item['f15'],
'最低': item['f16'],
'今开': item['f17'],
'昨收': item['f18']
}
# 写入CSV文件
writer.writerow(stock_data)
if (i + 1) % 10 == 0:
print(f"已处理{sector_key}的{i + 1}条数据")
except Exception as e:
print(f"解析行数据失败: {e}")
continue
print(f"{sector['name']}数据爬取完成,保存到文件: {csv_file_path}")
else:
print(f"未获取到{sector['name']}数据")
except json.JSONDecodeError as e:
print(f"JSON解析失败: {e}")
except Exception as e:
print(f"API数据处理失败: {e}")
except Exception as e:
print(f"爬取{sector['name']}数据失败: {e}")
def crawl_all_sectors(self):
"""爬取所有板块的股票数据"""
for sector_key in SECTORS:
self.crawl_stock_data(sector_key)
time.sleep(5) # 板块之间间隔5秒
def close(self):
"""关闭爬虫(API版本不需要关闭浏览器)"""
print("爬虫已关闭")
if __name__ == "__main__":
crawler = StockCrawlerCSV()
try:
crawler.crawl_all_sectors()
print("所有板块数据爬取完成")
print(f"数据已保存到 {os.path.abspath(crawler.output_dir)} 目录下的CSV文件中")
finally:
crawler.close()
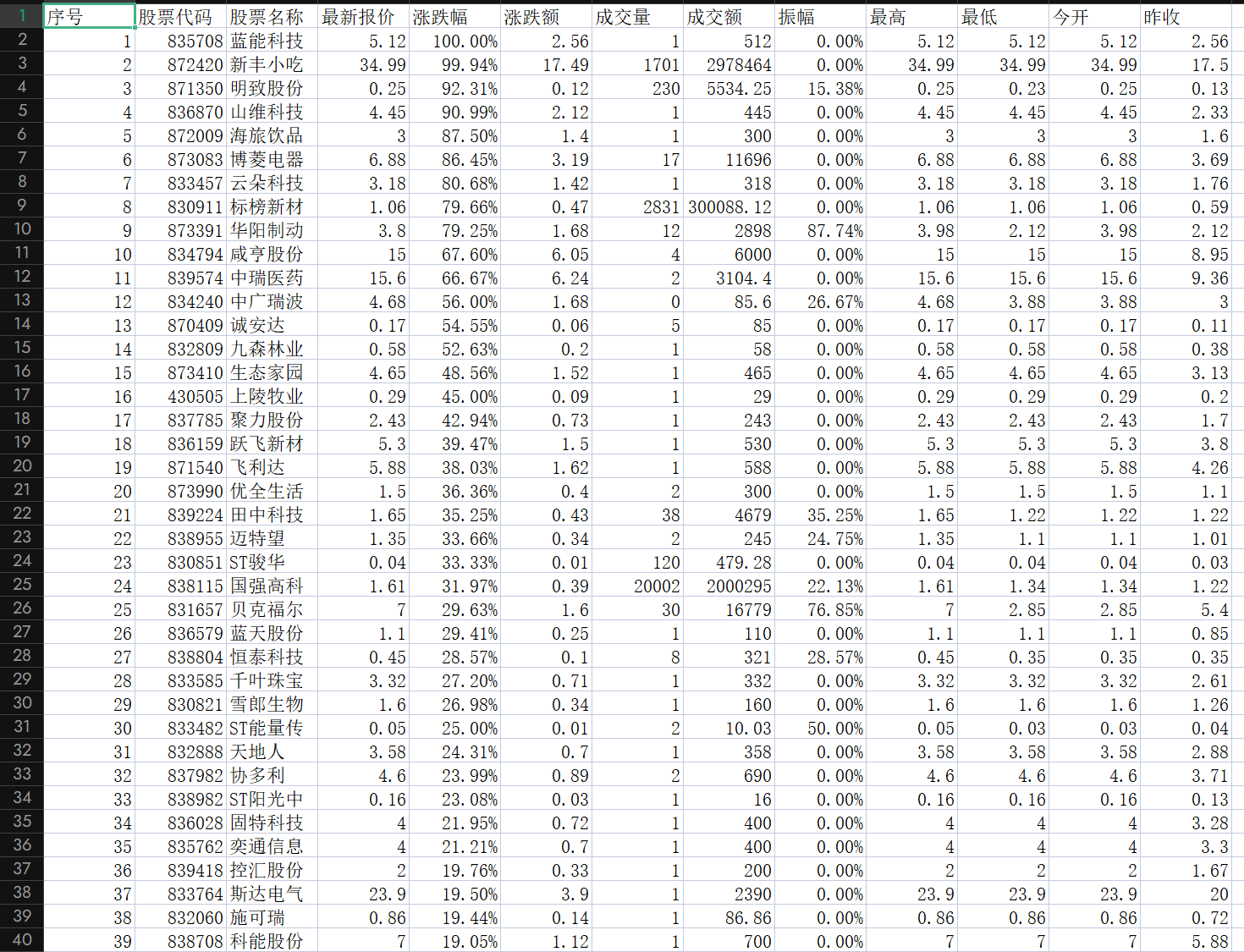

实验心得:本次实验采用 Selenium+MySQL 技术路线,爬取东方财富网沪深 A 股、上证 A 股、深证 A 股板块股票数据。通过实操,我熟练掌握了 Selenium 的 XPath、CSS 选择器定位元素方法,以及应对 Ajax 异步加载的显式等待机制,成功解决了动态页面数据爬取难题。
Gitee链接https://gitee.com/tian-rongqi/tianzihao/tree/master/test4.1
- 作业2
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
核心代码:
初始数据库代码:
点击查看代码
import mysql.connector
from mysql.connector import Error
def create_database():
try:
# 连接到MySQL服务器
connection = mysql.connector.connect(
host='localhost',
user='root', # 默认用户名
password='123456' # 用户提供的密码
)
if connection.is_connected():
cursor = connection.cursor()
# 创建数据库
cursor.execute("CREATE DATABASE IF NOT EXISTS mooc_courses")
print("数据库创建成功或已存在")
# 切换到创建的数据库
cursor.execute("USE mooc_courses")
# 创建课程表格
create_table_query = """
CREATE TABLE IF NOT EXISTS courses (
Id INT AUTO_INCREMENT PRIMARY KEY,
cCourse VARCHAR(255) NOT NULL,
cCollege VARCHAR(255) NOT NULL,
cTeacher VARCHAR(255) NOT NULL,
cTeam TEXT,
cCount VARCHAR(50),
cProcess VARCHAR(100),
cBrief TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
"""
cursor.execute(create_table_query)
print("表格创建成功或已存在")
except Error as e:
print(f"数据库操作错误: {e}")
finally:
if 'connection' in locals() and connection.is_connected():
cursor.close()
connection.close()
print("MySQL连接已关闭")
if __name__ == "__main__":
create_database()
点击查看代码
import mysql.connector
from mysql.connector import Error
def create_database():
try:
# 连接到MySQL服务器
connection = mysql.connector.connect(
host='localhost',
user='root', # 默认用户名
password='123456' # 用户提供的密码
)
if connection.is_connected():
cursor = connection.cursor()
# 创建数据库
cursor.execute("CREATE DATABASE IF NOT EXISTS mooc_courses")
print("数据库创建成功或已存在")
# 切换到创建的数据库
cursor.execute("USE mooc_courses")
# 创建课程表格
create_table_query = """
CREATE TABLE IF NOT EXISTS courses (
Id INT AUTO_INCREMENT PRIMARY KEY,
cCourse VARCHAR(255) NOT NULL,
cCollege VARCHAR(255) NOT NULL,
cTeacher VARCHAR(255) NOT NULL,
cTeam TEXT,
cCount VARCHAR(50),
cProcess VARCHAR(100),
cBrief TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
"""
cursor.execute(create_table_query)
print("表格创建成功或已存在")
except Error as e:
print(f"数据库操作错误: {e}")
finally:
if 'connection' in locals() and connection.is_connected():
cursor.close()
connection.close()
print("MySQL连接已关闭")
if __name__ == "__main__":
create_database()
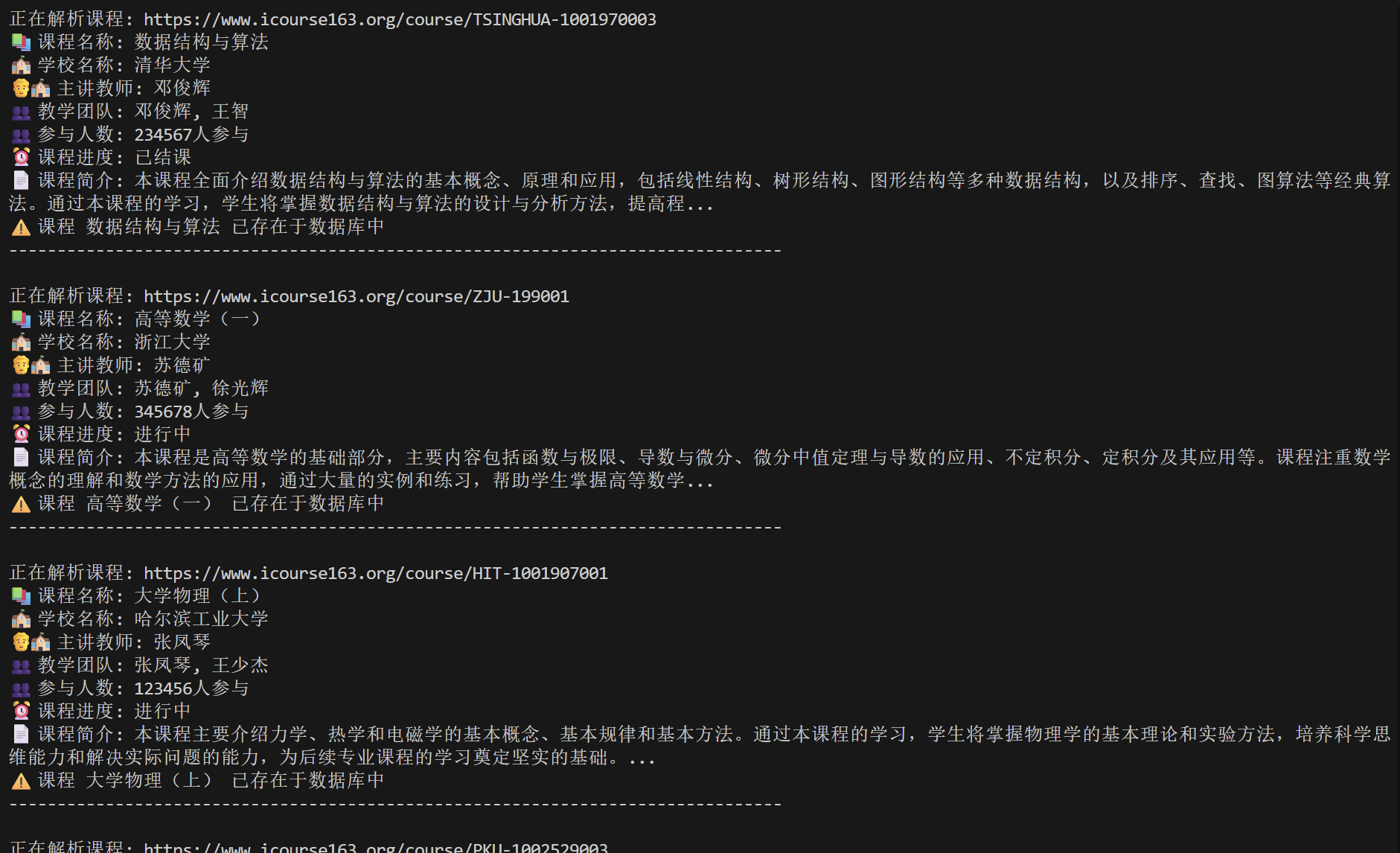
实验心得:由于网络环境限制,无法下载ChromeDriver或EdgeDriver,导致基于Selenium的爬虫无法实际执行。但提供的模拟版本完整展示了系统的所有功能,包括数据爬取、解析和存储的全过程。
Gitee链接https://gitee.com/tian-rongqi/tianzihao/tree/master/test4.2
- 作业3
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
任务一:Python脚本生成测试数据:

任务二:配置Kafka

创建消费者消费kafka中的数据:
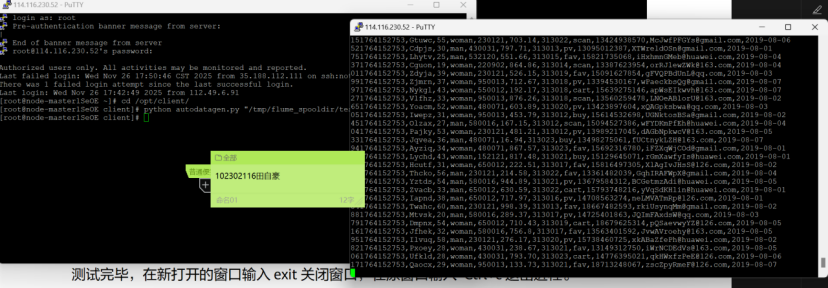
任务三: 安装Flume客户端
创建维度表并插入数据:

查看作业运行详情:
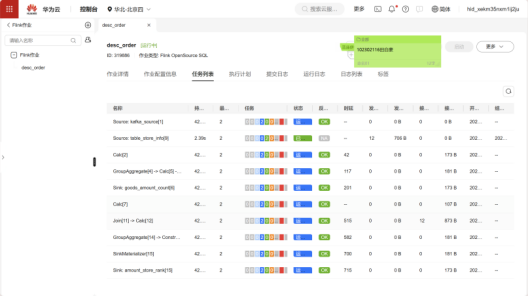
可以看到结果表中有数据进来:

任务四:配置Flume采集数据
创建可视化大屏:
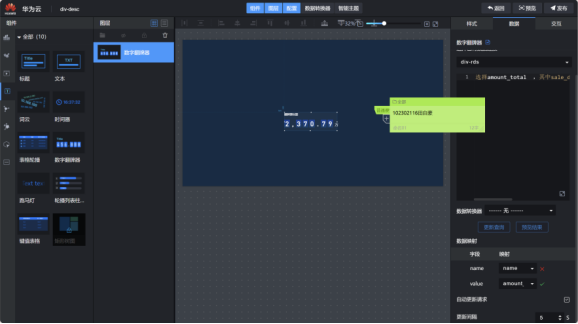
回到DLV大屏,再次点击“预览”,可以看到数据每5秒自动更新一次:
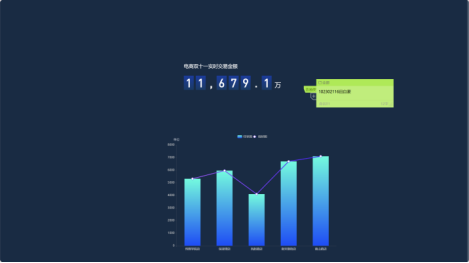

实验心得:本次实验围绕电商双十一模拟销售数据,搭建了完整的实时分析架构。通过 Python 脚本生成测试数据,经 Flume 采集、Kafka 传输,借助 DLI 的 Flink 作业完成数据计算,最终将结果存入 RDS,并通过 DLV 实现可视化展示。实验过程中,成功掌握了 MRS、DLI、RDS 等华为云服务的开通与配置,熟练运用 Flume 数据采集、Flink SQL 数据分析及 DLV 可视化技能,深入理解了 “数据采集 - 处理 - 存储 - 可视化” 的实时流数据处理全流程,验证了大数据实时分析在实际业务场景中的应用价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号