
102302116_田自豪_作业3
- 作业1:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
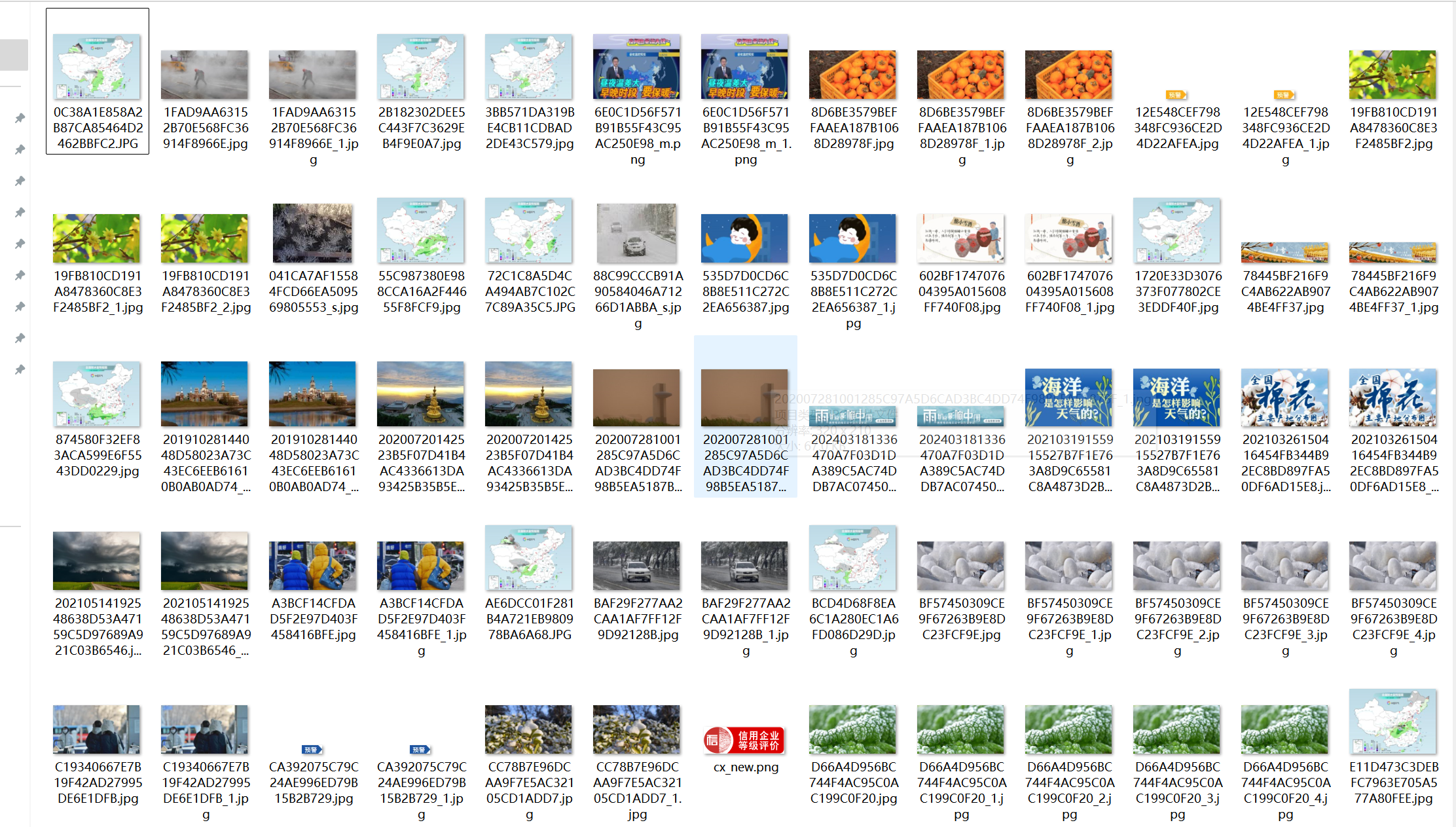
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
单线程代码如下:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
from urllib.parse import urljoin, urlparse
class ImageScraperSingleThread:
def __init__(self, target_url, page_limit=24, image_limit=124):
self.target_url = target_url
self.page_limit = page_limit
self.image_limit = image_limit
self.saved_count = 0
self.crawled_pages = set()
self.http_session = requests.Session()
self.http_session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
self.save_folder = 'images_single'
if not os.path.isdir(self.save_folder):
os.makedirs(self.save_folder)
def validate_url(self, url):
"""验证URL格式有效性(原is_valid_url)"""
parsed_url = urlparse(url)
return bool(parsed_url.netloc) and bool(parsed_url.scheme)
def save_image(self, image_url, source_page):
"""下载并保存单张图片(原download_image)"""
try:
if not image_url.startswith(('http://', 'https://')):
image_url = urljoin(source_page, image_url)
if not self.validate_url(image_url):
return False
allowed_formats = ('.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp')
if not image_url.lower().endswith(allowed_formats):
return False
print(f"正在获取图片: {image_url}")
img_response = self.http_session.get(image_url, timeout=10)
img_response.raise_for_status()
file_name = os.path.basename(urlparse(image_url).path)
if not file_name:
file_name = f"pic_{self.saved_count + 1}.jpg"
file_path = os.path.join(self.save_folder, file_name)
duplicate_counter = 1
while os.path.exists(file_path):
name_without_ext, ext = os.path.splitext(file_name)
file_path = os.path.join(self.save_folder, f"{name_without_ext}_{duplicate_counter}{ext}")
duplicate_counter += 1
with open(file_path, 'wb') as img_file:
img_file.write(img_response.content)
self.saved_count += 1
print(f"保存成功: {file_name} (累计: {self.saved_count}/{self.image_limit})")
return True
except Exception as err:
print(f"图片获取失败 {image_url}: {err}")
return False
def scrape_page(self, page_url):
"""爬取单个页面的图片和链接(原crawl_page)"""
if page_url in self.crawled_pages or len(self.crawled_pages) >= self.page_limit:
return
print(f"正在解析页面: {page_url}")
self.crawled_pages.add(page_url)
try:
page_response = self.http_session.get(page_url, timeout=10)
page_response.raise_for_status()
page_response.encoding = 'utf-8'
# 解析页面内容
html_parser = BeautifulSoup(page_response.text, 'html.parser')
# 提取所有图片标签并下载
all_img_tags = html_parser.find_all('img')
for img_tag in all_img_tags:
# 达到图片限制则停止
if self.saved_count >= self.image_limit:
return
# 获取图片真实地址(支持src和data-src)
img_src = img_tag.get('src')
if not img_src:
img_src = img_tag.get('data-src')
if img_src:
self.save_image(img_src, page_url)
# 提取后续页面链接(未达页面限制时)
if len(self.crawled_pages) < self.page_limit:
all_links = html_parser.find_all('a', href=True)
for link in all_links[:10]:
if self.saved_count >= self.image_limit:
return
next_page_url = link['href']
# 处理相对路径链接
if not next_page_url.startswith('http'):
next_page_url = urljoin(page_url, next_page_url)
# 只爬取目标域名下的未爬取链接
if self.target_url in next_page_url and next_page_url not in self.crawled_pages:
self.scrape_page(next_page_url)
except Exception as err:
print(f"页面解析失败 {page_url}: {err}")
def start_scraping(self):
"""启动爬取任务(原start_crawl)"""
print("启动单线程图片爬取...")
print(f"目标站点: {self.target_url}")
print(f"最大爬取页数: {self.page_limit}")
print(f"最大保存图片数: {self.image_limit}")
print("-" * 50)
start_timestamp = time.time()
self.scrape_page(self.target_url)
end_timestamp = time.time()
print("-" * 50)
print("爬取任务完成!")
print(f"总耗时: {end_timestamp - start_timestamp:.2f}秒")
print(f"已爬页面数: {len(self.crawled_pages)}")
print(f"成功保存图片数: {self.saved_count}")
if __name__ == "__main__":
image_scraper = ImageScraperSingleThread(
target_url="http://www.weather.com.cn",
page_limit=24,
image_limit=124
)
image_scraper.start_scraping()
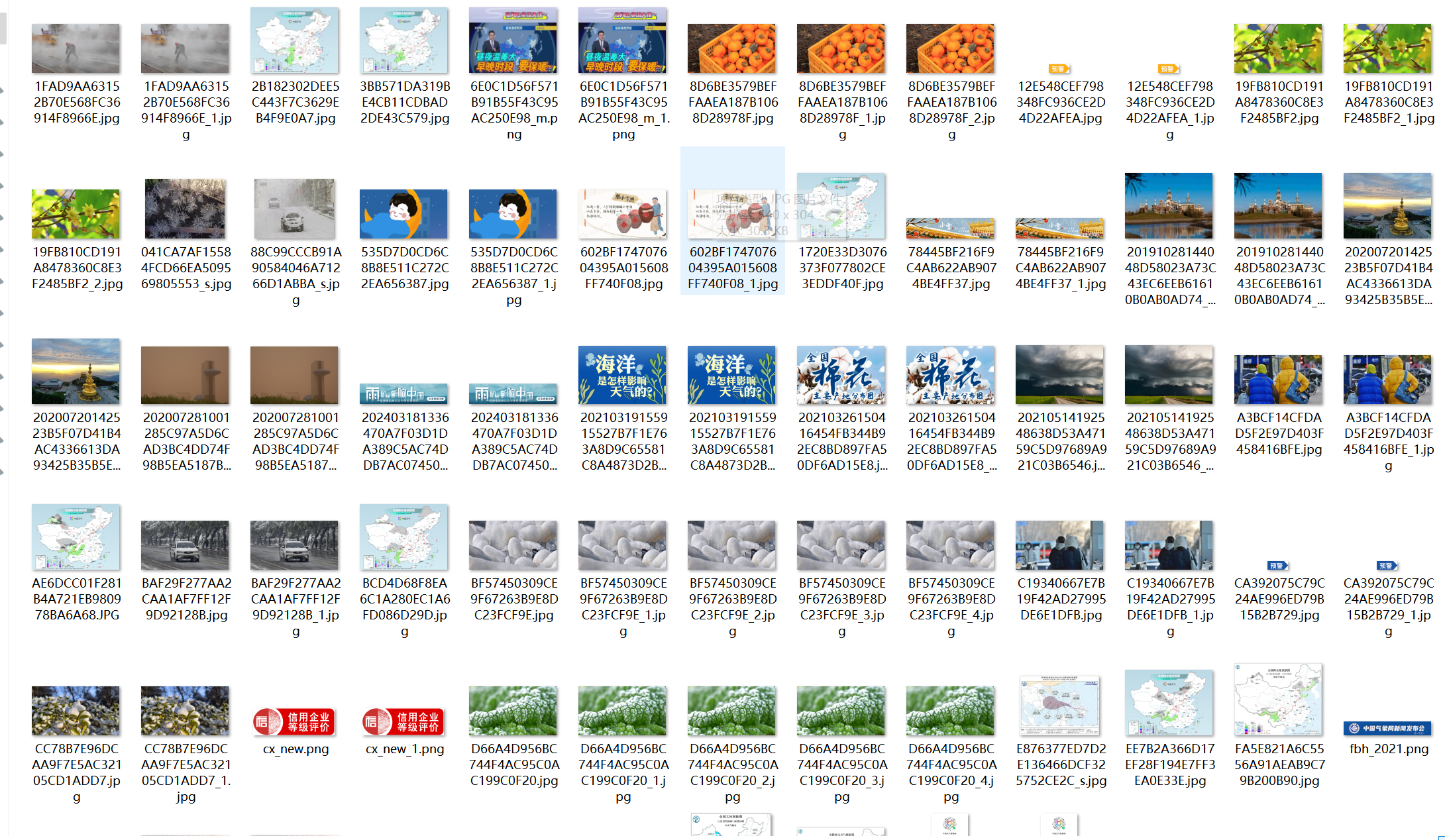
Gitee链接https://gitee.com/tian-rongqi/tianzihao/blob/master/test3/1.py
多线程代码如下:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
import threading
from urllib.parse import urljoin, urlparse
from queue import Queue
class MultiThreadImageScraper:
def __init__(self, target_url, page_cap=24, image_cap=124, thread_num=5):
self.target_url = target_url
self.page_cap = page_cap
self.image_cap = image_cap
self.thread_num = thread_num
self.saved_img_count = 0
self.crawled_pages = set()
self.page_task_queue = Queue()
self.thread_lock = threading.Lock()
self.http_client = requests.Session()
self.http_client.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
self.img_save_dir = 'images_multi'
if not os.path.isdir(self.img_save_dir):
os.makedirs(self.img_save_dir)
self.page_task_queue.put(target_url)
self.crawled_pages.add(target_url)
def check_url_validity(self, url):
"""验证URL是否合法(原is_valid_url)"""
parsed_url = urlparse(url)
return bool(parsed_url.netloc) and bool(parsed_url.scheme)
def fetch_and_save_image(self, img_src, source_page_url):
"""获取并保存单张图片(原download_image)"""
with self.thread_lock:
if self.saved_img_count >= self.image_cap:
return False
try:
# 处理相对路径URL
if not img_src.startswith(('http://', 'https://')):
img_src = urljoin(source_page_url, img_src)
# 跳过无效URL
if not self.check_url_validity(img_src):
return False
# 仅支持指定图片格式(保持原格式集合)
supported_formats = ('.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp')
if not img_src.lower().endswith(supported_formats):
return False
current_thread = threading.current_thread().name
print(f"{current_thread} 正在获取图片: {img_src}")
# 发起图片请求,保持10秒超时设置
img_resp = self.http_client.get(img_src, timeout=10)
img_resp.raise_for_status() # 抛出HTTP错误
# 提取文件名,处理无文件名的情况
img_filename = os.path.basename(urlparse(img_src).path)
if not img_filename:
img_filename = f"pic_{self.saved_img_count + 1}.jpg"
img_save_path = os.path.join(self.img_save_dir, img_filename)
dup_counter = 1
while os.path.exists(img_save_path):
name_core, file_ext = os.path.splitext(img_filename)
img_save_path = os.path.join(self.img_save_dir, f"{name_core}_{dup_counter}{file_ext}")
dup_counter += 1
# 保存图片文件
with open(img_save_path, 'wb') as img_file:
img_file.write(img_resp.content)
# 原子操作更新计数
with self.thread_lock:
self.saved_img_count += 1
current_total = self.saved_img_count
print(f"{current_thread} 保存成功: {img_filename} (累计: {current_total}/{self.image_cap})")
return True
except Exception as err:
print(f"{threading.current_thread().name} 图片获取失败 {img_src}: {err}")
return False
def parse_page_content(self, page_url):
"""解析单个页面的图片和链接(原process_page)"""
current_thread = threading.current_thread().name
print(f"{current_thread} 正在解析页面: {page_url}")
try:
# 发起页面请求,保持编码和超时设置
page_resp = self.http_client.get(page_url, timeout=10)
page_resp.raise_for_status()
page_resp.encoding = 'utf-8'
# 解析HTML内容
html_soup = BeautifulSoup(page_resp.text, 'html.parser')
# 提取并下载所有图片
all_img_tags = html_soup.find_all('img')
for img_tag in all_img_tags:
# 检查是否已达图片上限
with self.thread_lock:
if self.saved_img_count >= self.image_cap:
return
# 获取图片地址(支持src和data-src属性)
img_url = img_tag.get('src')
if not img_url:
img_url = img_tag.get('data-src')
if img_url:
self.fetch_and_save_image(img_url, page_url)
# 检查是否已达页面爬取上限
with self.thread_lock:
if len(self.crawled_pages) >= self.page_cap:
return
# 提取并添加新的页面链接
all_links = html_soup.find_all('a', href=True)
# 限制每页处理的链接数量(保持原限制8个)
for link in all_links[:8]:
with self.thread_lock:
# 双重限制检查:图片数量和页面数量
if self.saved_img_count >= self.image_cap or len(self.crawled_pages) >= self.page_cap:
return
link_url = link['href']
# 处理相对路径链接
if not link_url.startswith('http'):
link_url = urljoin(page_url, link_url)
# 验证链接合法性并添加到队列
with self.thread_lock:
if (self.target_url in link_url and
link_url not in self.crawled_pages and
len(self.crawled_pages) < self.page_cap):
self.crawled_pages.add(link_url)
self.page_task_queue.put(link_url)
except Exception as err:
print(f"{current_thread} 页面解析失败 {page_url}: {err}")
def thread_worker(self):
"""线程工作函数(原worker)"""
while True:
# 检查退出条件:图片达上限 或 队列空且页面达上限
with self.thread_lock:
exit_condition = (self.saved_img_count >= self.image_cap) or \
(self.page_task_queue.empty() and len(self.crawled_pages) >= self.page_cap)
if exit_condition:
break
try:
# 从队列获取任务,超时5秒
task_url = self.page_task_queue.get(timeout=5)
self.parse_page_content(task_url)
self.page_task_queue.task_done()
except:
break
def start_scraping(self):
"""启动多线程爬取(原start_crawl)"""
print("启动多线程图片爬取...")
print(f"目标站点: {self.target_url}")
print(f"最大爬取页数: {self.page_cap}")
print(f"最大保存图片数: {self.image_cap}")
print(f"线程数量: {self.thread_num}")
print("-" * 50)
start_time = time.time()
# 创建并启动工作线程
worker_threads = []
for i in range(self.thread_num):
thread = threading.Thread(target=self.thread_worker, name=f"Worker-{i + 1}")
thread.daemon = True
thread.start()
worker_threads.append(thread)
# 等待所有队列任务完成
self.page_task_queue.join()
# 等待所有线程安全退出
for thread in worker_threads:
thread.join(timeout=1)
end_time = time.time()
print("-" * 50)
print("爬取任务完成!")
print(f"总耗时: {end_time - start_time:.2f}秒")
print(f"已爬页面数: {len(self.crawled_pages)}")
print(f"成功保存图片数: {self.saved_img_count}")
if __name__ == "__main__":
image_scraper = MultiThreadImageScraper(
target_url="http://www.weather.com.cn",
page_cap=24,
image_cap=124,
thread_num=5
)
image_scraper.start_scraping()
实验心得:通过本次图片爬取实验,我深刻体会到了单线程与多线程爬虫的效率差异。在爬取中国气象网图片过程中,单线程方式虽然逻辑简单,但下载速度较慢,特别是在网络延迟较高时更为明显。而多线程爬虫通过并发请求显著提升了下载效率,但也带来了资源竞争和线程管理的新挑战。我学会了如何使用线程池合理控制并发数量,避免对目标网站造成过大压力。同时,在文件存储方面,需要处理好文件名冲突和路径管理问题。这次实验让我认识到在实际爬虫项目中,需要在效率和友好性之间找到平衡点。
Gitee链接https://gitee.com/tian-rongqi/tianzihao/blob/master/test3/2.py
- 作业2:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
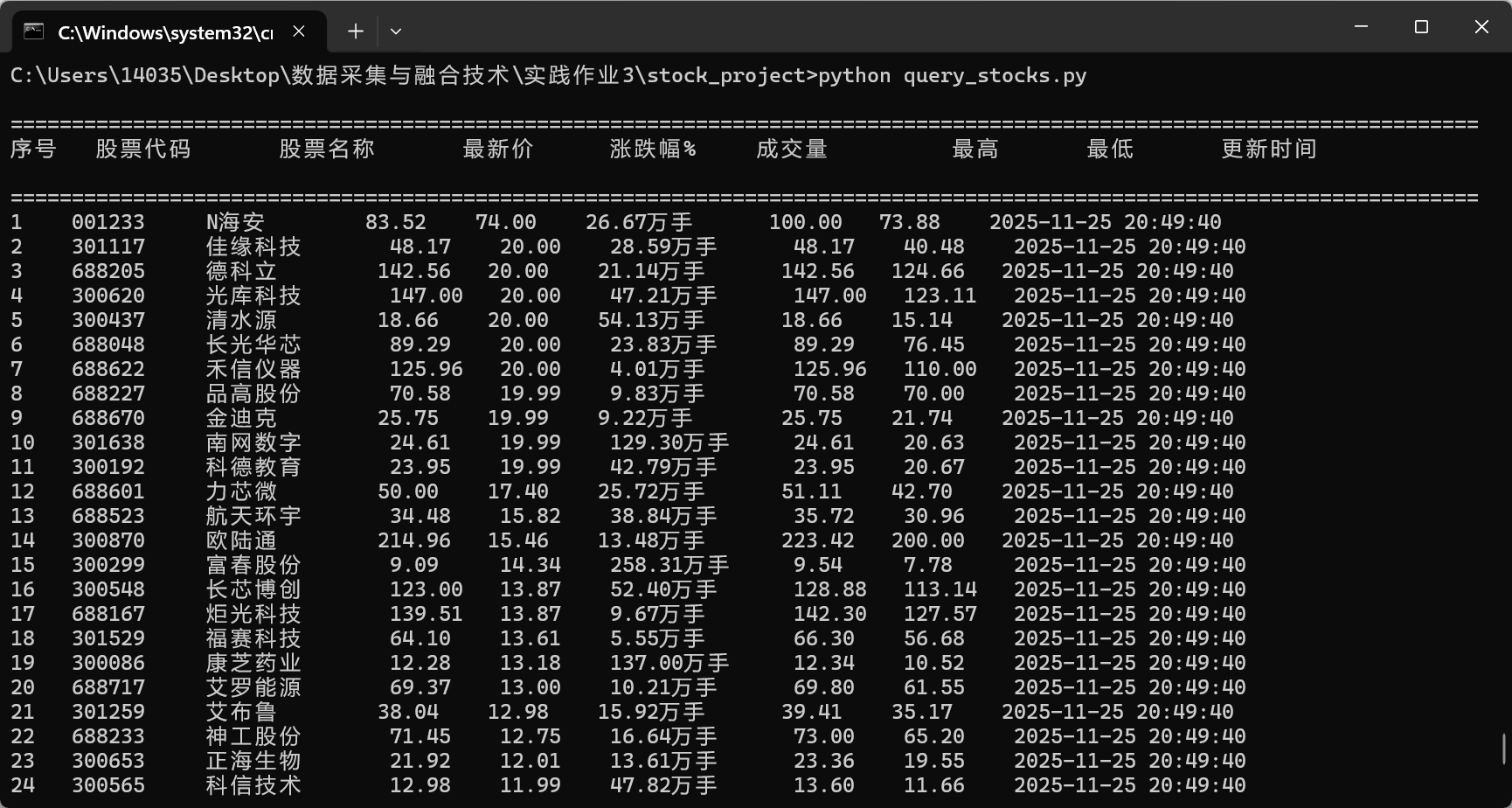
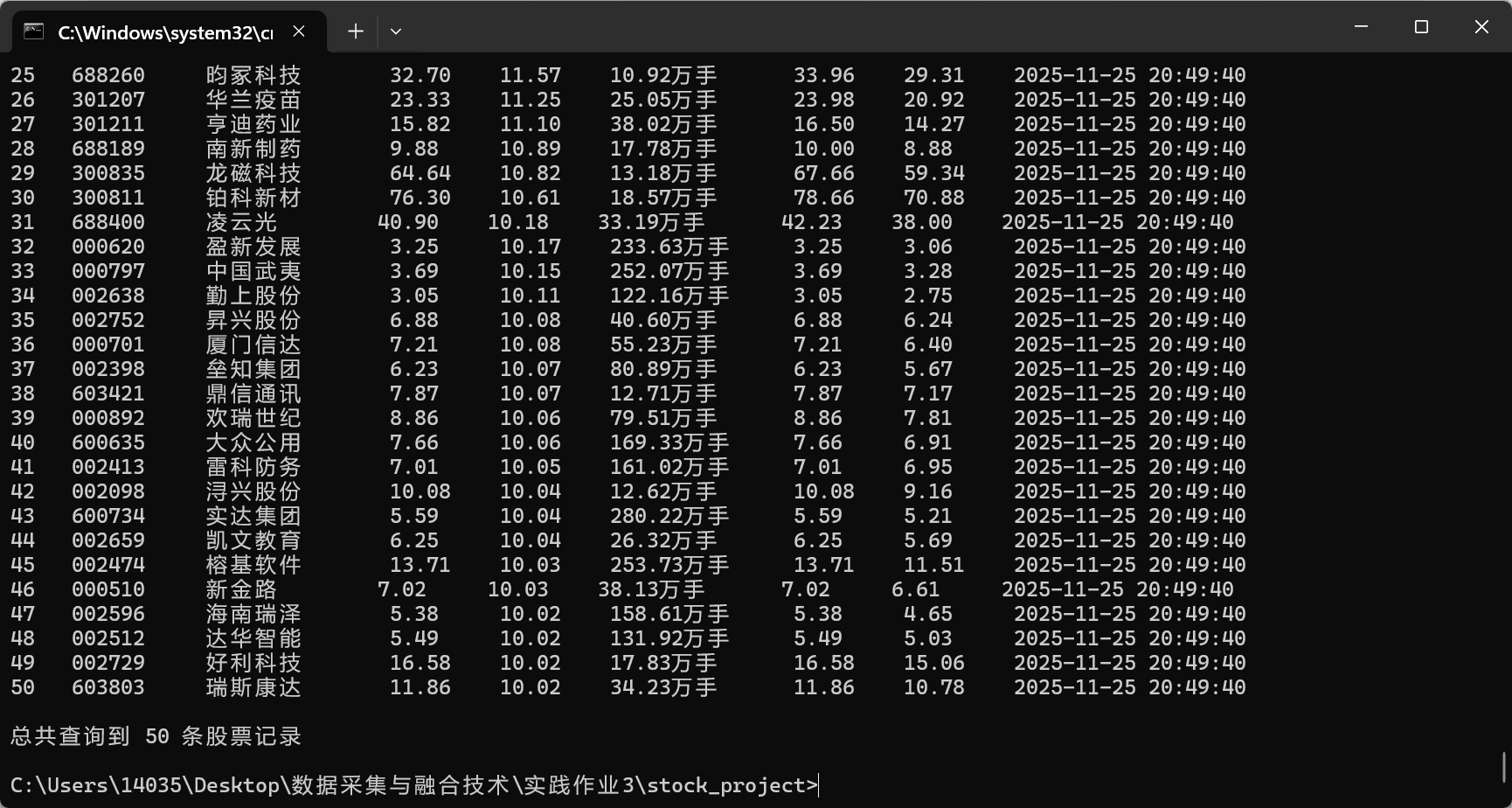
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
核心代码如下:
点击查看代码
import pymysql
from sqlalchemy import create_engine
# 在这里设置你的MySQL密码
MYSQL_PASSWORD = "123456" # 将这里替换为实际密码
def create_database():
"""创建数据库"""
try:
# 连接MySQL(使用你的密码)
conn = pymysql.connect(
host='localhost',
user='root',
password=MYSQL_PASSWORD,
charset='utf8mb4'
)
# 创建数据库
with conn.cursor() as cursor:
cursor.execute("CREATE DATABASE IF NOT EXISTS stock_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci")
print("✅ 数据库创建成功!")
conn.commit()
conn.close()
# 创建表结构
create_tables()
except Exception as e:
print(f"❌ 创建数据库时出错: {e}")
def create_tables():
"""创建数据表"""
try:
# 连接具体的数据库创建表
engine = create_engine(f'mysql+pymysql://root:{MYSQL_PASSWORD}@localhost:3306/stock_db?charset=utf8mb4')
from stock_spider.pipelines import Base
Base.metadata.create_all(engine)
print("✅ 数据表创建成功!")
except Exception as e:
print(f"❌ 创建表时出错: {e}")
if __name__ == '__main__':
create_database()
实验心得:本次股票数据爬取实验让我全面掌握了Scrapy框架的核心组件使用。通过Item类的定义,我学会了如何结构化地组织爬取数据;Pipeline的使用则让我理解了数据清洗、验证和存储的完整流程。在爬取东方财富网股票信息时,XPath选择器的灵活运用帮助我精准定位所需数据。最大的收获是学会了将爬取数据持久化存储到MySQL数据库,包括数据库设计、连接管理和异常处理。这次实验不仅提升了我的爬虫技能,还加深了我对数据管道处理思想的理解,为后续复杂的数据采集项目打下了坚实基础。
Gitee链接https://gitee.com/tian-rongqi/tianzihao/tree/master/test3/stock_project
- 作业3:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
核心代码如下:
点击查看代码
"""
外汇数据库创建脚本
自动创建SQLite数据库和表结构
"""
from sqlalchemy import create_engine
from forex_spider.pipelines import Base
import os
def create_forex_database():
"""创建外汇数据库"""
try:
# 使用SQLite数据库
engine = create_engine('sqlite:///forex_data.db')
# 创建表
Base.metadata.create_all(engine)
print("✅ 外汇数据库创建成功!")
print("📊 数据库文件: forex_data.db")
# 检查文件是否创建成功
if os.path.exists('forex_data.db'):
print("✅ 数据库文件已生成")
else:
print("❌ 数据库文件未生成,请检查权限")
except Exception as e:
print(f"❌ 创建数据库时出错: {e}")
if __name__ == '__main__':
create_forex_database()
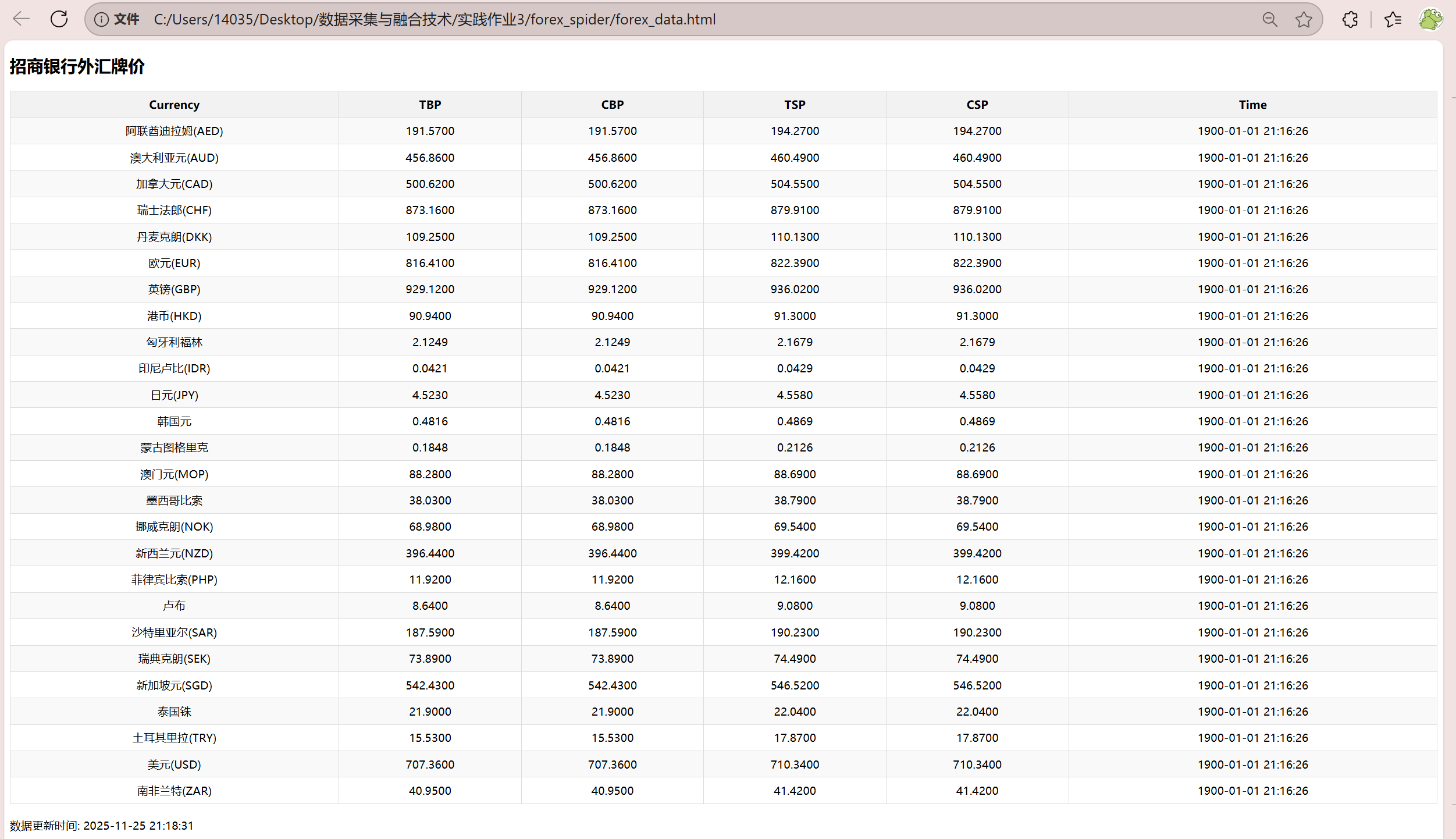
实验心得:外汇数据爬取实验让我进一步巩固了Scrapy框架的应用能力。在爬取招商银行外汇牌价过程中,我遇到了网站结构复杂、数据格式多样等挑战,通过精心设计XPath表达式和数据处理逻辑成功解决了这些问题。本次实验的亮点在于完整实现了从数据采集、清洗到数据库存储的全流程自动化。我特别注意到外汇数据具有实时性强的特点,因此在爬虫设计中加入了时间戳记录和数据更新机制。通过这次实验,我不仅掌握了外汇数据的采集技术,更重要的是培养了处理金融数据的严谨态度和对数据质量的把控能力。
Gitee链接https://gitee.com/tian-rongqi/tianzihao/tree/master/forex_spider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号