数据库--索引
1 为什么要建索引
图书馆存了1000W本图书,要从中找到《架构师之路》,一本本查,要查到什么时候去?
于是,图书管理员设计了一套规则:
(1)一楼放历史类,二楼放文学类,三楼放IT类…
(2)IT类,又分软件类,硬件类…
(3)软件类,又按照书名音序排序…
以便快速找到一本书。
与之类比,数据库存储了1000W条数据,要从中找到name=”Lisi”的记录,一条条查,要查到什么时候去?
于是,要有索引,用于提升数据库的查找速度。
索引是为了提高查询速度的一种数据结构(比如BTREE)
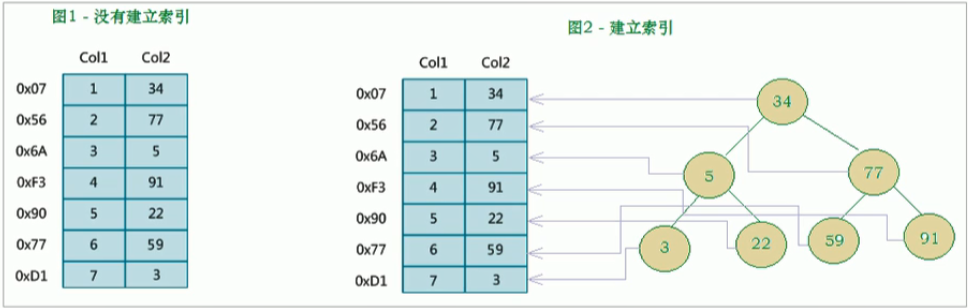
没有建立索引时查找数据只能从上向下顺序查找,时间复杂度是n/2,建立二叉树的索引结构后二叉树的查找效率是log2n,二叉树的节点指向表中的数据行,这样就提高了查找效率.BTREE的m叉树原理一样
索引的缺点:
1 占用空间
2 增删改表时要维护索引(重新平衡二叉树),会降低增删改的速度.
有一个线上的记录日志的表,定期会删除早期的数据,经过一段时间的维护,这个表中存放的记录空间稳定在10G,但是索引占用空间有30G,一共40G空间。
原因:InnoDB存储引擎表就是索引组织表,记录数据存放在主键索引叶子结点上,这张表会被不断插入日志记录,且定期删除日志记录,会导致维护索引的B+树频繁发生页的分裂,导致页空间中出现浪费的空间,提高了索引的占用空间。
解决:可以通过重建索引的方式,删除之前的旧索引,并重新创建这个索引,因为数据已经在表中,因此重建索引的过程会将表中的数据按顺序插入,使得页面结构重新恢复紧凑
2 哈希(hash)比树(tree)更快,索引结构为什么还要设计成树型?
加速查找的数据结构,常见的有两类:
(1)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1);
(2)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(lg(n));
可以看到,不管是读请求,还是写请求,哈希类型的索引,都要比树型的索引更快一些,但这些好处都是where条件能唯一确定一个值的时候,如果不能唯一确定一条记录或者有in ,< ,>, <>,排序,分组这种情况,哈希索引的效率会降为O(n),因为哈希索引存储的是经过哈希算法
处理过的哈希值,哈希值的大小不能反应原值的大小,而且复合索引是一起计算哈希值的,更不能对单个索引列使用.
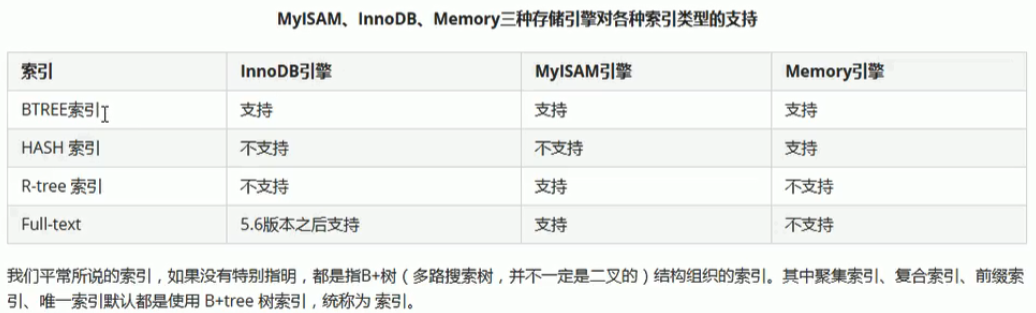
索引类型:
BTREE:最常见的索引类型
HASH:只有memory引擎支持
R-tree:空间索引,有关地理位置时使用
Full-text:全文索引
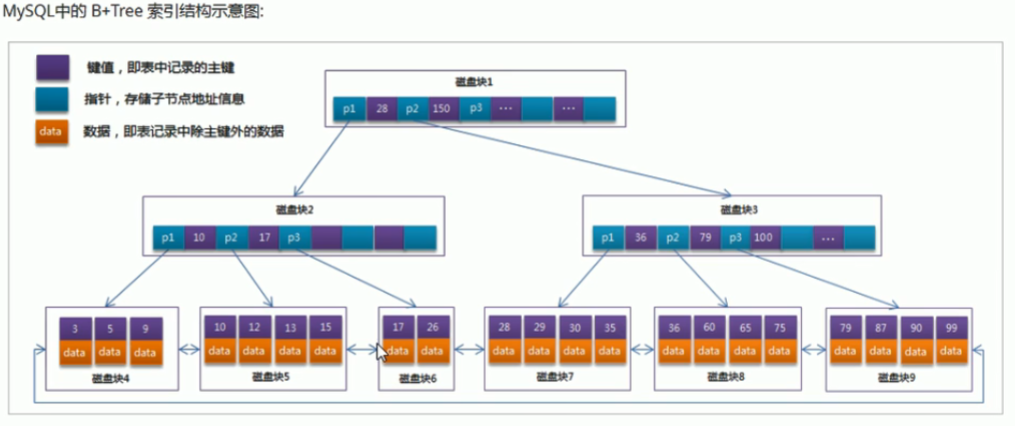
3 二叉树,B树,B+树的区别,什么是局部性原理以及为什么选B+树做索引:
二叉树:每个节点只能存一条数,只有两个分叉,数据量多时会造成树过高,导致io次数过
B树:m叉平衡树,叶子节点和非叶子节点都存储真实数据,真实数据存储到非叶子节点里会造成单个节点存的数据条数少,想要获得所有节点,需要前序/中序/后序遍历整棵树
B+树:m叉平衡树,根节点和非叶子节点只存键值和子节点地址,叶子节点存储真实数据,这样根节点和非叶子节点就能有更多空间存数键值了,且叶子节点用链表连接便于范围查找
索引分类:
聚集索引(主键索引)
聚集索引: InnoDB 会使用主键 ID 建立索引 B+ Tree,而其 B+ Tree 的叶子节点存储的是主键 ID 对应的数据,聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引树中的数据也是索引的一部分
由此可见,使用聚集索引查询会很快,因为可以直接定位到行记录
如果表设置了主键,则主键就是聚集索引(主键索引)
如果表没有主键,则会默认第一个 NOT NULL,且唯一(UNIQUE)的列作为聚集索引(主键索引)
以上都没有,则会默认创建一个隐藏的 row_id 作为聚集索引(主键索引)
普通索引(非主键索引)
普通索引:当表中创建了普通索引(非主键索引)时,InnoDB 就会建立普通索引 B+ Tree,这个普通索引 B+ Tree 的叶子节点存储的是数据记录的主键 ID.
回表:普通索引需要先查索引树找到主键ID,再去主键索引数根据ID查数据.
查看表的索引 show index from table_name
删除索引: drop index index_name on table_name
建表后添加索引:
添加主键索引,值唯一且非空 alter table table_name add primary key(column_list);
添加唯一索引,可以为空值且出现多次 alter table table_name add unique index_name(column_list);
添加普通索引,索引值可以重复 alter table table_name add index index_name(column_list);
索引设计原则:
查询频率高,数据量大
索引列选择where后的条件,on 后的表连接字段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号