
数据采集第四次作业
数据采集第四次作业
作业1 :
1、实验内容
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
候选网站:http://search.dangdang.com/?key=python&act=input
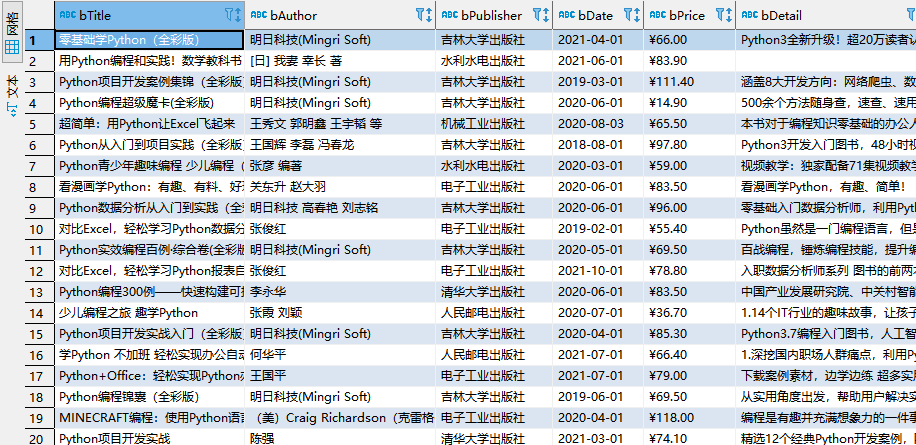
输出信息:
https://img2020.cnblogs.com/blog/1460147/202010/1460147-20201027122553458-671254945.png
运行结果
代码
https://gitee.com/x42bd82a1/fzu-data-acquisition-course/tree/master/4/1
同课件
2、心得
阅读课件10.4样例程序并复制粘贴。
“加深了 Pipeline Scrapy Xpath MySQL 的理解” 之类的套话
作业2:
1、实验内容
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
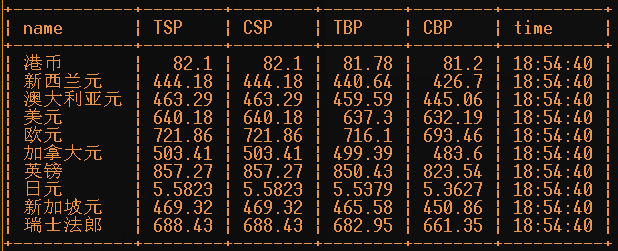
输出信息:
| Id | Currency | TSP | CSP | TBP | CBP | Time |
|---|---|---|---|---|---|---|
| 1 | 港币 | 86.60 | 86.60 | 86.26 | 85.65 | 15:36:30 |
| 2...... |
运行结果
代码
https://gitee.com/x42bd82a1/fzu-data-acquisition-course/tree/master/4/2
2、心得
与之前无异,记得去空格之类的就行
“加深了 Pipeline Scrapy Xpath MySQL 的理解” 之类的套话
作业3:
1、实验内容
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
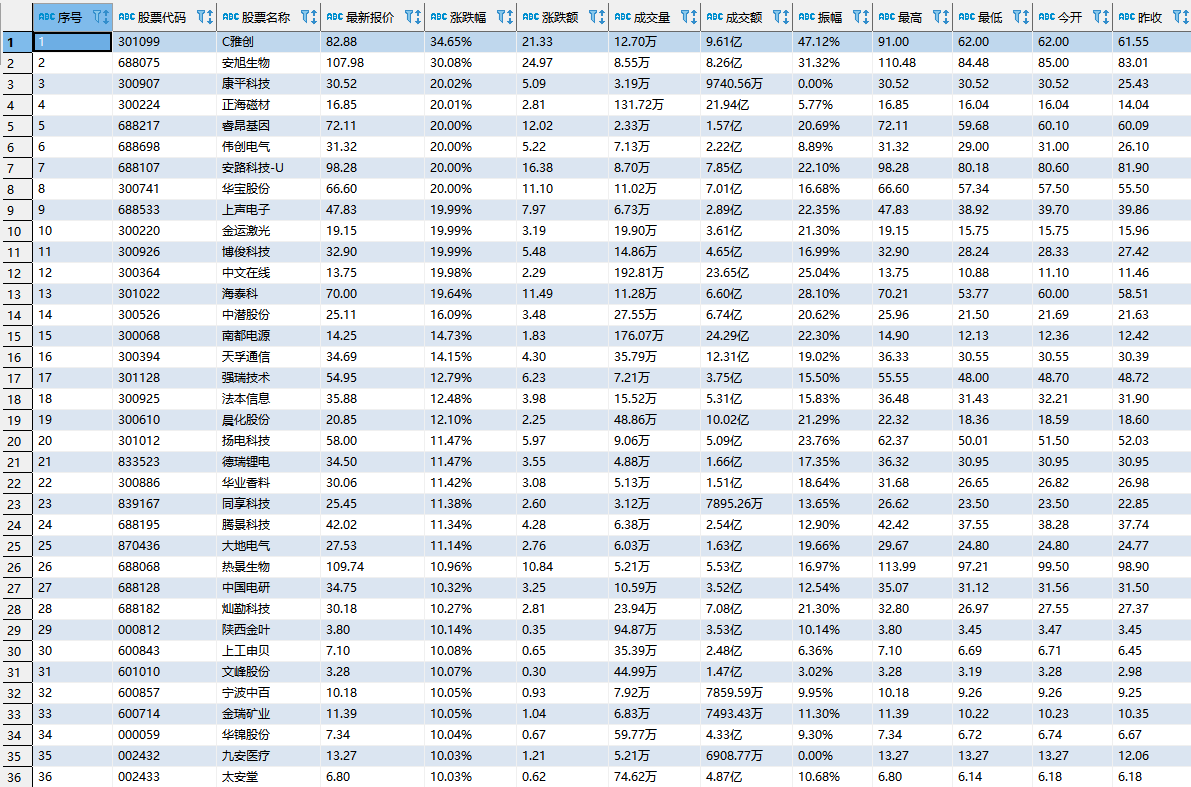
输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
运行结果
代码
https://gitee.com/x42bd82a1/fzu-data-acquisition-course/tree/master/4/3
2、心得
将数据库改为MySQL,其余与之前的实验无异
每列对应一个 /tbody/tr ,简单将其字符切分可得单元格内容,自行目测每列对应含义
“加深了 Selenium Ajax MySQL 的理解” 之类的套话

 浙公网安备 33010602011771号
浙公网安备 33010602011771号