
数据采集第三次作业
数据采集第三次作业
作业1 :
1、实验内容
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位)
输出信息:
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
运行结果
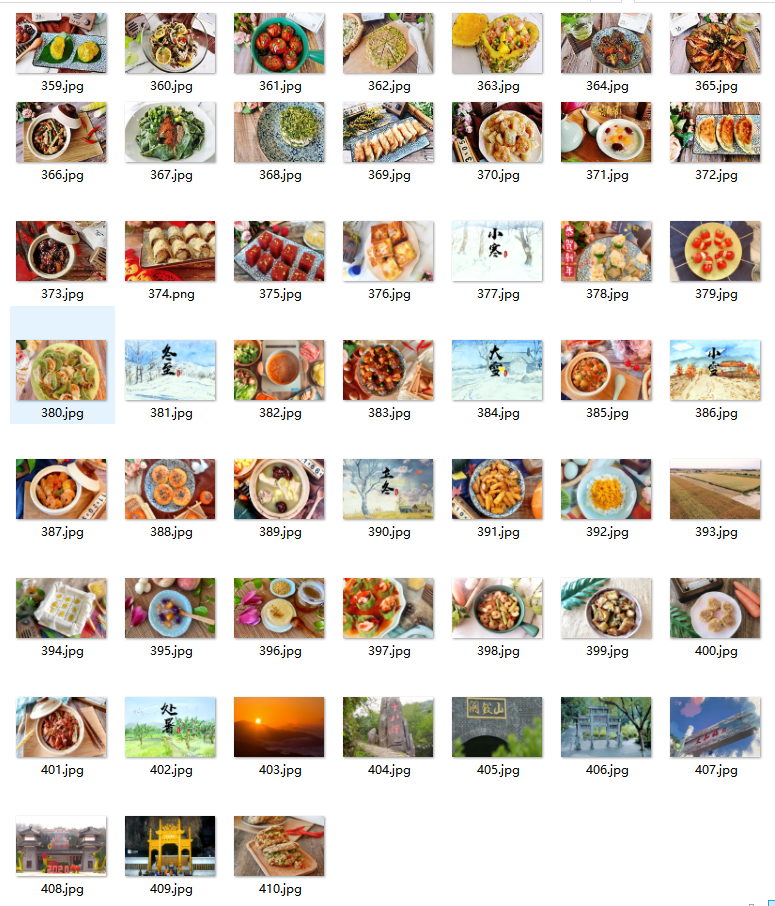
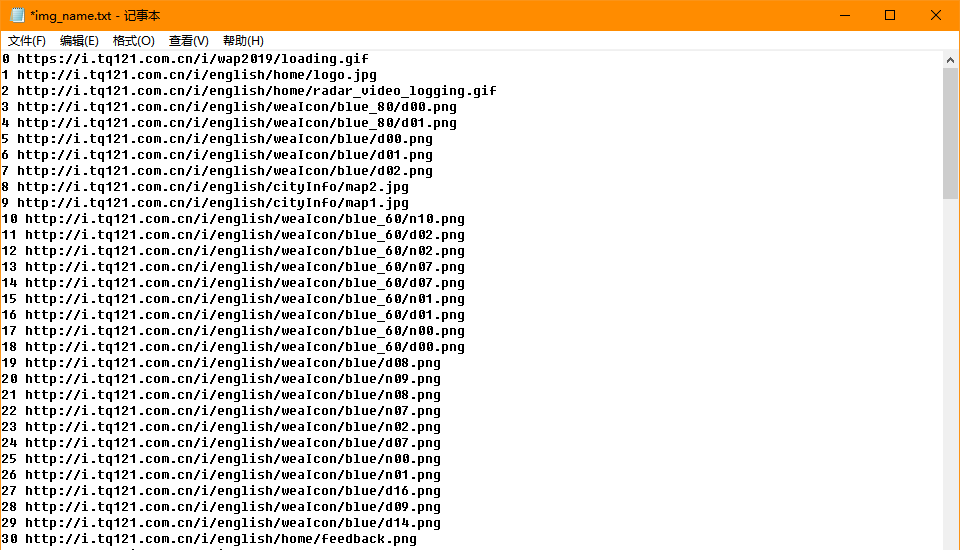
代码
https://gitee.com/x42bd82a1/fzu-data-acquisition-course/tree/master/3/1
2、心得
将之前作业的代码套上《算法与数据结构》课程中常见的递归即可完成
因为懒得处理线程的同步等问题,而性能的瓶颈大概在图片下载,页面的递归访问没有多线程实现
以及正常人能用一台机器每秒手工刷十几个页面吗 😃
作业2:
1、实验内容
要求:
使用scrapy框架复现作业1
输出信息:
同作业1
运行结果
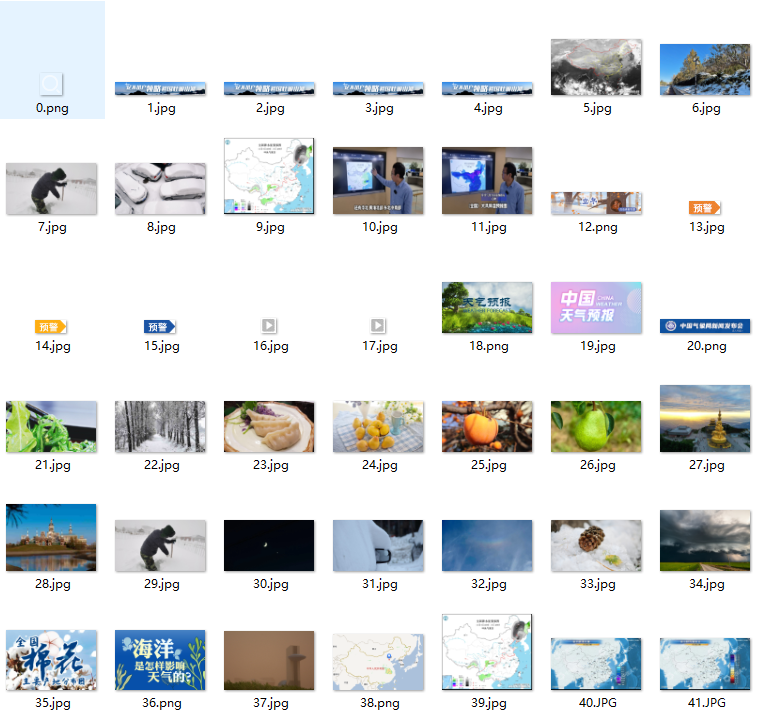
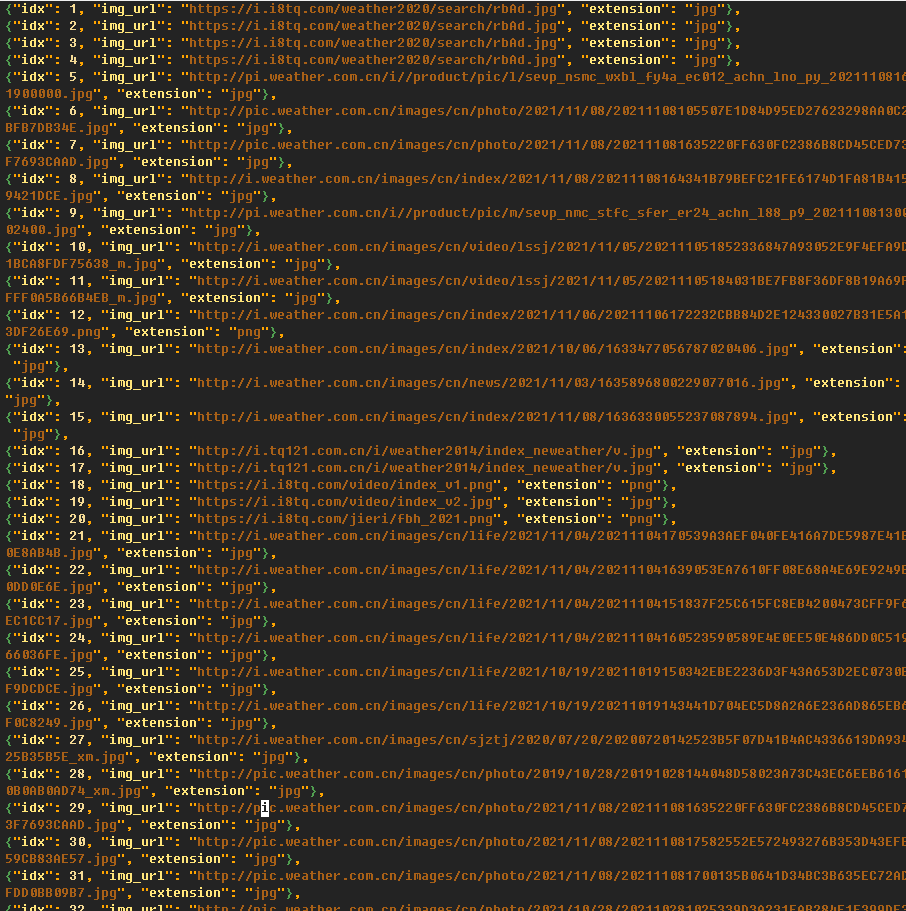
代码
https://gitee.com/x42bd82a1/fzu-data-acquisition-course/tree/master/3/2
2、心得
在parse里写上yield scrapy.Request(url=href_url, callback=self.parse)之类的代码以实现递归访问
要记得去重,否则链接有环就会出问题,这里选用bloom_filter的BloomFilter()
要记得限速,因为scrapy自带多线程
作业3:
1、实验内容
要求:
爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2 | ... |
运行结果


代码
https://gitee.com/x42bd82a1/fzu-data-acquisition-course/tree/master/3/3
2、心得
在pipelines中遍历item.fields.keys()以写入数据库,别用硬编码(课件的样例那种),麻烦且容易出错
导演和演员在同一标签中,以三个\xa0字符分隔
当然这不是正解,应访问电影对应页面获取完整信息


 浙公网安备 33010602011771号
浙公网安备 33010602011771号