
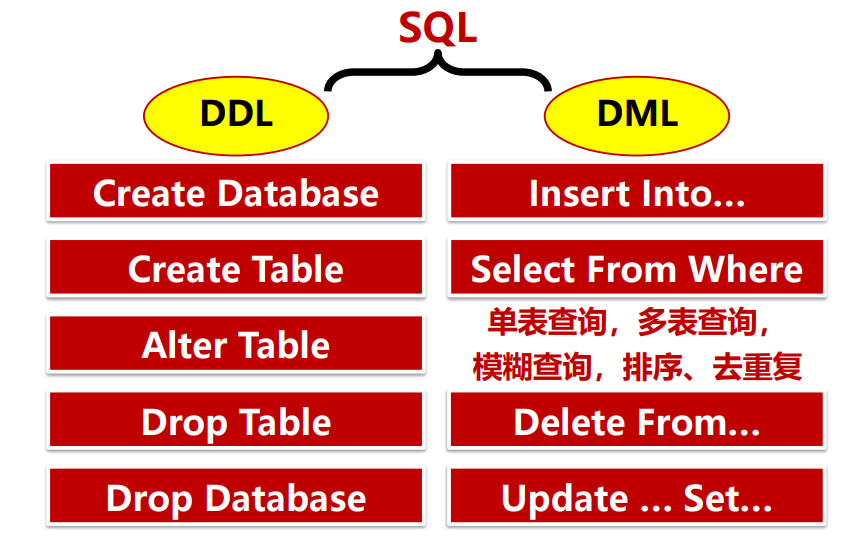
SQL
SQL语言概述
- 定义数据库:
SDL DDL - 操纵数据库:
SQL DML
数据定义语言(DDL)
- 定义关系模式,删除关系,创建索引,修改关系模式,定 义视图
数据操纵语言(DML) - 查询语言基于关系代数和关系演算
- 在数据库中插入、删除、和修改元组
完整性 - 说明完整性约束的命令
- 存储在数据库中的数据必须满足完整性约束
- 禁止违反完整性约束的更新操作
事务控制 - 说明事务的开始和结束
- 封锁数据实现并发控制
嵌入式SQL和动态SQL - 通过ODBC/ADO/JDBC等数据库访问接口,如将SQL嵌入 到C++、C#、JAVA等通用编程语言
授权 - 说明对关系和视图访问权限的命令
SQL动词
- 数据查询:
SELECT - 数据定义:
CREATE,DROP,ALTER - 数据操纵:
INSERT,UPDATE,DELETE - 数据控制:
GRANT,REVOKE
SQL语句
定义数据库
建立数据库
创建表
常用数据类型

eg: 定义学生表
Create Table Student ( S# char(8) , Sname char(10), Ssex char(2), Sage integer, D# char(2), Sclass char(6) );
常用完整性约束
- 主码约束:PRIMARY KEY
- 唯一性约束:UNIQUE
- 非空值约束:NOT NULL
- 参照完整性约束
eg
CREATE TABLE Student
(S# char(8) PRIMARY KEY,
Sname char(10) NOT NULL,
Ssex char(2),
Sage integer,
D# char(2),
Sclass char(6),
FOREIGN KEY (D#)
REFERENCES Dept (D#));
CREATE TABLE SC
(S# char(8),
C# char(3),
Score float(1) ,
Primary key (S#, C#),
FOREIGN KEY (S#) REFERENCES Student(S#),
FOREIGN KEY (C#) REFERENCES Course(C#));
修正表的定义
Alter Table 表名
[Add {列名 数据类型, …}] 增加新列
[Drop {完整性约束名}] 删除完整性约束
[Modify {列名 数据类型, …}] 修改列定义
例如:
Alter Table Student Add Saddr char[40], PID char[18] ;
Alter Table Student Modify Sname char(12) ;
Alter Table Student Drop Unique( Sname );
删除属性列
- 直接删除
ALTER TABLE Student DROP COLUMN Sname;
- 间接删除
- 把表中要保留的列及其内容复制到一个新表中
- 删除原表
- 再将新表重命名为原表名
删除基本表
Drop Table 表名
• 基本表删除
• 数据、表上的索引都删除
• 表上的视图往往仍然保留,但无法引用
注意是否存在外码引用
操纵数据库
插入数据
Insert Into 表名[ (列名 [, 列名 ]… ]
Values (值 [, 值] , …) ;
例如
Insert Into Student ( S#, Sname, Ssex, Sage, D#, Sclass)
Values (‘201804002’ , ‘李四’ , ‘女’, 18, ‘02’ , ‘2018’ );
简单查询
Select 列名 [[, 列名] … ]
From 表名
[ Where 检索条件 ] ;
例如
Select S#, Sname, Ssex, Sage, Sclass, D# From Student ;
Select * From Student ; //如投影所有列,则可以用*来简写
Select Sage, Sname //列可以重排顺序
From Student
Where Sage <= 19;
条件的书写
运算符
= 、>、<、>=、<=、!= 或 <>、!>、!<
逻辑运算符NOT and or
注意运算优先级,必要时使用()
检索字符串加单引号
BETWEEN ... AND ...
NOT BETWEEN ... AND ...
可用于数字,日期等
IS NULL, IS NOT NULL 空值
IN 值表 NOT IN 值表
例如
SELECT Sname, Ssex
FROM Student
WHERE Sdept
IN (‘01', ‘02', ‘03');
在检索结果中要求无重复元组, 使用DISTINCT 加在检索属性前
例如
Select DISTINCT S# From SC
Where Score > 80;
检索结果排序
Order By 列名 [ Asc | Desc ] //ASC或省略为升序
例如
Select S#, Sname From Student
Order By S# ASC ;
Select S# From SC Where C# = ‘002’ and Score > 80
Order By Score DESC ;
模糊查询(字符串)
列名 [Not ] Like ‘字符串’ [ESCAPE ‘转义字符’]
字符串匹配符
- “%” 匹配零个或多个字符
- “_” 匹配任意单个字符
- “ \ ” 转义字符,使%,_等特殊字符被作为普通字符看待, 比如需要匹配字符%,就用“\%”
例如 检索姓张学生
Select S#, Sname From Student
Where Sname Like ‘张%’ ;
SELECT C#, Credit
FROM Course
WHERE Cname LIKE 'DB\_Design' ESCAPE ‘\’;
多表联合查询(连接)
Select 列名 [[, 列名] … ]
From 表名1, 表名2, …
[ Where 检索条件 ] ;
例如
Select Sname From Student, SC
Where Student.S# = SC.S# and SC.C# = ‘001’
Order By Score DESC;
多表连接时,如两个表的属性名相同,则需采用表名. 属性名 方式来限定该属性是属于哪一个表
重命名处理
连接运算涉及到重名的问题,如两个表中的属性重名,连接 的两个表重名(同表的连接)等,需要使用别名以便区分
Select 列名 As 列别名 [ [, 列名 As 列别名] … ]
From 表名1 As 表别名1, 表名2 As 表别名2, …
Where 检索条件 ;
上述定义中的As 可以省略
定义了别名后,在检索条件中可以使用别名来限定属性
例如
Select S1.S# From SC S1, SC S2
Where S1.S# = S2.S# and S1.C#=‘001’ and S2.C#=‘002’ ;
表的更新
批数据新增
Insert Into St (S#, Sname)
Select S#, Sname From Student Where Sname like ‘%明’ ;
删除满足条件的元组
Delete From SC Where S# = ‘98030101’ ;
修改元组
Update 表名
Set 列名 = 表达式 | (子查询)
[ [ , 列名 = 表达式 | (子查询) ] … ]
[ Where 条件表达式] ;
如果Where条件省略,则更新所有的元组。
例如
Update Teacher
Set Salary = ( Select Salary From Teacher Where Tname = ‘李明’) Where Dname = ‘信息工程’;
子查询
概念
- 一个SELECT-FROM-WHERE语句称为一个查询块
- 将一个查询块嵌套在另一个查询块的FROM子句、WHERE子句等的条件中的查询称为子查询 (嵌套查询)
子查询类型
(Not) In子查询
语义:判断某一表达式的值是否在子查询的结果中。
例如
查询与“刘晨”在同一个系学习的学生
Select Sno, Sname, Sdept
From Student
Where Sdept In
(Select Sdept From Student Where Sname=‘刘晨’);
- 不相关子查询:内层查询独立进行,由内向外逐层处理。
- 相关子查询:内层查询需要外层查询的某些参量作为限定条件才能进行的子查询,外层向内层传递参量需要使用外层的表名或表别名来限定
不相关子查询例子:求学过001号课程的同学的姓名
Select Sname
From Student Stud
Where S# in ( Select S# From SC
Where S# = Stud.S# and C# = ‘001’ ) ;
查询过程:
- 从外层查询取Student一个元组x,将元组S#值(201803001)传给内层查询
Select S# From SC Where
S# = ‘201803001’ and C# = ‘001’
- 执行内层查询得到值201803001,用该值执行外层查询,再重复1
Select Sname From Student Stud
Where S# in (‘201803001’ )
Some / All 子查询
- F <comp> Some r = 存在 t 属于 r (F <comp> t)
- F <comp> All r = 所有的 t 属于r (F <comp> t)
<comp> 可以是:<, ≤, >, ≥, =, <>, !=
示例:找出001号课成绩不是最高的所有学生的学号
Select S# From SC
Where C# = “001” and
Score < Some ( Select Score From SC Where C# = “001” );
等价子查询
表达式 = Some (子查询) = 表达式 In (子查询)
Not In等价于 <>All
(Not) Exists 子查询
语义:子查询结果中有无元组存在
示例:检索选修了赵明老师主讲课程的所有同学的姓名
Select DISTINCT Sname From Student
Where Exists ( Select * From SC, Course, Teacher
Where SC.C# = Course.C# and SC. S# = Student.S#
and Course.T# = Teacher.T# and Tname = ‘赵明’ ) ;
不加Not的Exists谓词可以省略
Not Exists R 等价于 R = ø
SQL结果计算
Select-From-Where语句中,Select子句后面不仅可是列名,而且可是一些计算表达式或聚集函数,表明在投影的同时直接进行一些运算
Select 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名) ] … ]
From 表名1 [, 表名2 … ]
[ Where 检索条件 ]
聚集函数
-
计数(number of values)
- Count ([Distinct | All ] {* | <列名>})
-
计算总和(sum of values)
• Sum ([Distinct | All ] <列名>)- 计算平均值(average value)
• Avg ([Distinct | All ] <列名>)利
- 计算平均值(average value)
-
求最大值(maximum value)
- Max ([Distinct | All ] <列名>)
-
求最小值(minimum value)
- Min ([Distinct | All ] <列名>)
-
Dinstinct:计算时取消列中重复值
-
All:不取消重复值
-
All为缺省值
分组查询与分组过滤
分组查询
将元组按照某一条件分类,具有相同值的元组划到一个组或一个集合中,并处理多个组或集合的聚集运算。
Select 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名) ] … ]
From 表名1 [, 表名2 … ]
[ Where 检索条件 ]
[ Group by 分组条件 ] ;
示例: 求每一个学生的平均成绩
Select S#, AVG(Score) From SC Group by S#;
分组过滤
要对集合(即分组)进行条件过滤,即满足条件的集合/分组留下,不满足条件的集合/分组剔除。
Select 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名) ] … ]
From 表名1 [, 表名2 … ]
[ Where 检索条件 ]
[ Group by 分组条件 [ Having 分组过滤条件] ]
Having子句,又称分组过滤子句。需要有Group•by子句支持,即:没有Group•by子句,便不能有Having子句
示例:
Select S# From SC
Where Score < 60
Group by S# Having Count(*)>2;
与Where子句表达条件的区别
- Where每一行都要检查条件
- Having只检查每一分组的条件
注意 分组查询的语义问题
集合运算
并运算 Union, 交运算Intersect, 差运算Except
基本语法形式:
子查询 { Union [All] | Intersect [All] | Except [All] 子查询 }
不带All自动删除重复元组。若要保留重复元组,则加All。
Union运算示例:求学过002号课或学过003号课的同学学号
Select S# From SC Where C# = ‘002’
UNION
Select S# From SC Where C# = ‘003’;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号