使用BeautifulSoup库进行爬虫
环境安装
pip install beautifulsoup4
爬取中国天气网数据
要求:
爬取该页面的7天天气数据
http://www.weather.com.cn/weather/101010100.shtml
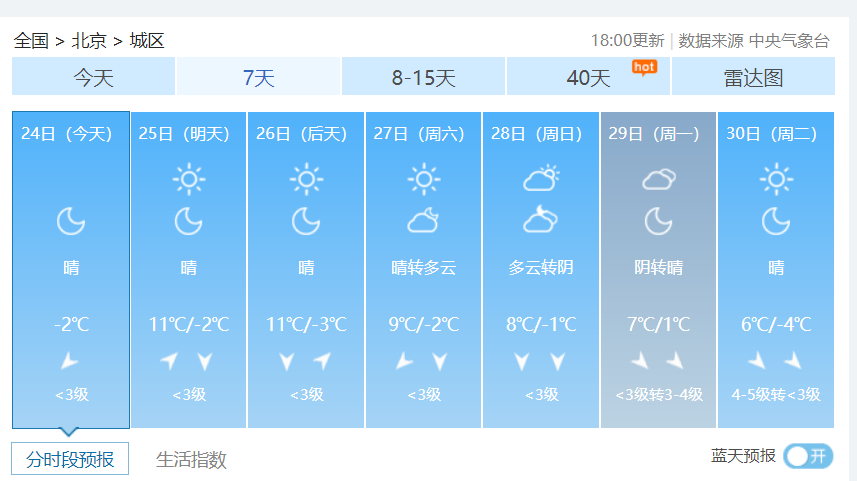
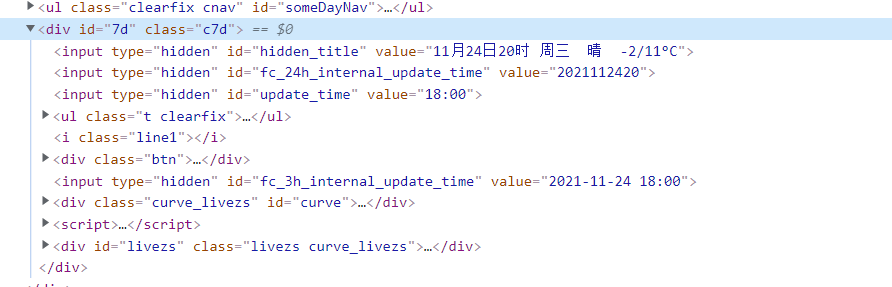
通过审查元素我们可以肯定我们需要的信息都包含在div id="7d"里
代码编写:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
url = 'http://www.weather.com.cn/weather/101010100.shtml'
#使用request爬取网页信息
def getHTMLText(url,timeout=30):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() #如果状态码不是200则返回异常
r.encoding=r.apparent_encoding #设置编码
return r.text
except:
return '出现异常'
def get_data(html):
final_list = []
soup = BeautifulSoup(html,'html.parser')
body = soup.body
data = body.find('div',{'id':'7d'}) #查找div中id为7d的标签
ul = data.find('ul')
lis = ul.find_all('li')
for day in lis:
temp_list = []
date = day.find('h1').string #找到日期
temp_list.append(date)
#找到所有p标签
info = day.find_all('p')
#第一个p标签没有i标签
temp_list.append(info[0].string)
#最高温度 有可能没有
if info[1].find('span'):
weather_high = info[1].find('span').string
temp_list.append(weather_high)
#最低温度
if info[1].find('i'):
weather_low = info[1].find('i').string
temp_list.append(weather_low)
#风级
wind_scale = info[2].find('i').string
temp_list.append(wind_scale)
final_list.append(temp_list)
return final_list
def main():
list = get_data(getHTMLText(url))
print(list)
if __name__ == '__main__':
main()
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号