
hadoop-eclipse配置
1、设备: Ubuntu镜像:ubuntu-18.04.2-desktop-amd64.iso
hadoop: hadoop-2.6.5.tar.gz
jdk: jdk-linux-x64.tar.gz
Eclipse: eclipse-java-2020-03-R-linux-gtk-x86_64.tar.gz
jar:hadoop-eclipse-plugin-2.6.5.jar
2、安装SSH,设置SSH无密码登陆
1)更新软件资源列表
$sudo apt-get install update
(如果不行的话,可以用 $sudo apt install update)

2)安装SSH server
$ sudo apt-get install openssh-server

3)登陆SSH
$ ssh localhost

4)退出登录的ssh localhost
$ exit

5)查看在用户下是否存在.ssh文件夹(注意ssh前面有“.”,这是一个隐藏文件夹),输入命令
$ ls -a /home/wangyuyang
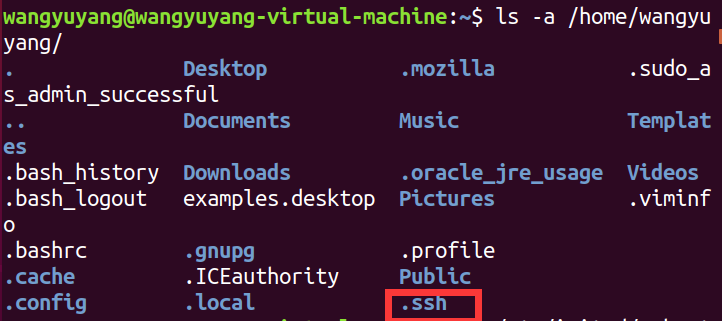
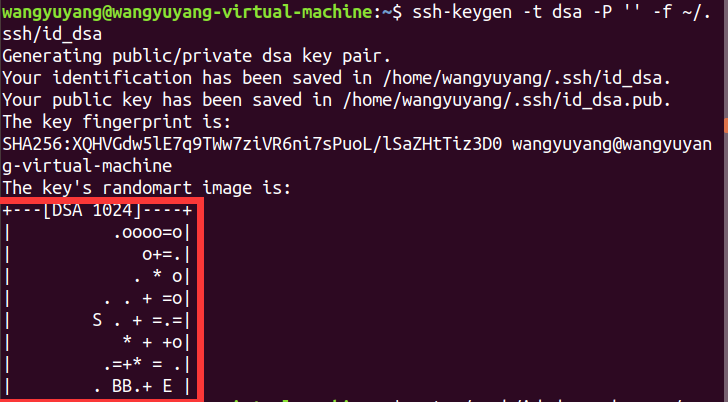
6)在.ssh文件夹下创建两个文件id_dsa及id_dsa.pub,这是ssh的一对私钥和公钥,类似于钥匙及锁,把id_da.pub(公钥)追加到授权的key里面去
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
7)把公钥加入到用于认证的公钥文件中,这里authorized_keys是用于认证的公钥文件
$cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

8)验证ssh已安装成功及无密码登陆本机
$ ssh localhost

9)退出
$ exit

3、jdk 配置
1)在/usr/lib目录下创建jvm目录
$ sudo mkdir /usr/lib/jvm

2)把 jdk-linux-x64.tar.gz 解压到/usr/lib/jvm
$ sudo tar zxvf jdk-linux-x64.tar.gz -C /usr/lib/jvm

3)在/etc/profile进行配置
$ sudo vim /etc/profile
加入如下内容
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_131 export CLASSPATH=.:${JAVA_HOME}/lib/tools.jar:${JAVA_HOME}/lib/dt.jar export PATH=$JAVA_HOME/bin:$PATH
4)执行source /etc/profile使设置生效
$ source /etc/profile

5)查看是否安装成功
$ java -version

$ javac -version

4、hadoop配置
1)把hadoop-2.6.5.tar.gz 解压到/usr/local
$ sudo tar -zxvf hadoop-2.6.5.tar.gz -C /usr/local

2)跳转到/usr/local目录下
$ cd /usr/local

3)把hadoop-2.6.5名字换成hadoop
$ sudo mv hadoop-2.6.5 hadoop
4)执行sudo chown -R hplip hadoop ./hadoop命令
$ sudo chown -R hplip hadoop ./hadoop
5)在/etc/profile进行配置
$ sudo vim /etc/profile
加入如下内容
export HADOOP_HOME=/usr/local/hadoop export PATH=${HADOOP_HOME}/bin:$PATH export CLASSPATH=.:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.5.jar
:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.5.jar
:$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar:$CLASSPATH
6)执行source /etc/profile使设置生效
$ source /etc/profile
7)查看hadoop是否安装成功
hadoop version
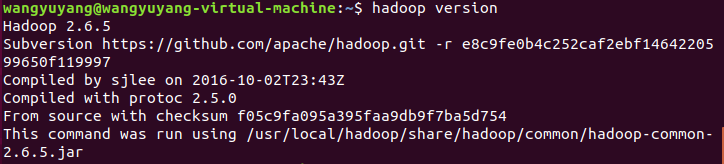
8)跳转到etc/hadoop目录下,修改相应文件
$ cd /usr/local/hadoop/etc/hadoop/

9)进入到hadoop-env.sh添加jdk路径
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_131

10)使用sudo vim core-site.xml命令,进入core-site.xml
$ sudo vim core-site.xml
在<configuration> </configuration>里添加如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
11)使用sudo vim hdfs-site.xml命令,进入hdfs-site.xml
$ sudo vim hdfs-site.xml
在<configuration> </configuration>里添加如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.checkpoint.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/snn</value>
<description>secondary namenode 的位置</description>
</property>
<property>
<name>dfs.checkpoint.edits.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/snn</value>
<description>secondary namenode 的位置</description>
</property>
</configuration>
12)在hadoop目录下使用./bin/hdfs namenode -format对NameNode 进行格式化
$ ./bin/hdfs namenode -format
13)启动namenode和datanode进程
$ ./sbin/start-dfs.sh
14)查看启动结果,正常情况下会出现 NameNode、DataNode、SecondaryNameNode、Jps
$ jps
15)在/etc/hadoop目录下复制文件mapred-site.xml.template,并命为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
使用sudo vim mapred-site.xml命令,进入mapred-site.xml
$ sudo vim mapred-site.xml
在<configuration> </configuration>里添加如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
16)使用sudo vim yarn-site.xml命令,进入yarn-site.xml
$ sudo vim yarn-site.xml
在<configuration> </configuration>里添加如下内容
<configuration> <!-- Site specific YARN configuration properties -->
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
17)在/usr/local/hadoop目录,启动资源管理器(如果权限不够,先使用 $ sudo chmod 777 sbin )
./sbin/start-yarn.sh
18)查看历史任务
./sbin/mr-jobhistory-daemon.sh start historyserver
19)查看启动结果,org.eclipse.equinox.launcher_1.5.700.v20200207-2156.jar 是我配置了eclipse后出现的,理论上现在是没有的
$ jps
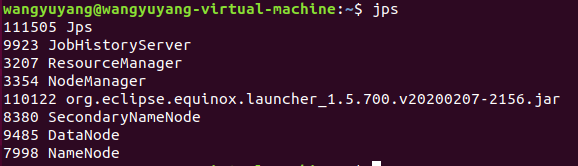
5、eclipse配置
1)解压eclipse-java-2020-03-R-linux-gtk-x86_64.tar.gz到/opt目录下
$ sudo tar zxvf eclipse-java-2020-03-R-linux-gtk-x86_64.tar.gz -C /opt

2)在eclispe的plugins导入hadoop-eclipse-plugin-2.6.5.jar(这里可能权限不够,可以在终端 使用 sudo mv hadoop-eclipse-plugin-2.6.5.jar /opt/eclipse/plugins )
3)可以在云端创建自己目录,我这里创建两个目录,分别为/user/hadoop/input和/user/hadoop/output
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -mkdir -p /user/hadoop/output
在创建这两个目录的时候,可能会出现问题,一般是系统处于安全模式,可以使用命令推出安全模式(在/hadoop目录下)
bin/hadoop dfsadmin -safemode leave
也有可能是防火墙没有关闭
4)打开eclipse

 浙公网安备 33010602011771号
浙公网安备 33010602011771号