Redis持久化、主从与哨兵架构详解
参考
图灵课堂
https://zhuanlan.zhihu.com/p/443951927
https://blog.csdn.net/weixin_37548768/article/details/124538778?spm=1001.2014.3001.5502
https://www.runoob.com/redis/redis-transactions.html
redis支持持久化到磁盘,这样可用进一步保证数据的完整性。
redis持久化分为两种,一个是RDB,一个是AOF。
RDB快照(snapshot)
RDB是Redis的一种数据持久化到磁盘的策略,是一种以内存快照形式保存Redis数据的方式。所谓快照,就是把某一时刻的状态以文件的形式进行全量备份到磁盘,这个快照文件就称为RDB文件,其中RDB是Redis DataBase的缩写。
bgsave的写时复制(COW)机制
save和bgsave的对比
| 命令 | save | bgsave |
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 |
否(在生成子进程执行调用fork函
数时会有短暂阻塞)
|
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 |
需要fork子进程,消耗内存
|
AOF(append-only file)
3
$3
set
$6
tuling
$3
888
*3
$9
PEXPIREAT
$6
tuling
$13
1604249786301
- 1 appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
- 2 appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
- 3 appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
aof重写
生产环境可以都启用,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof一般来说数据更全一点。
混合持久化
Redis数据备份策略:
- 1. 写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48小时的备份
- 2. 每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份
- 3. 每次copy备份的时候,都把太旧的备份给删了
- 4. 每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
Redis主从架构
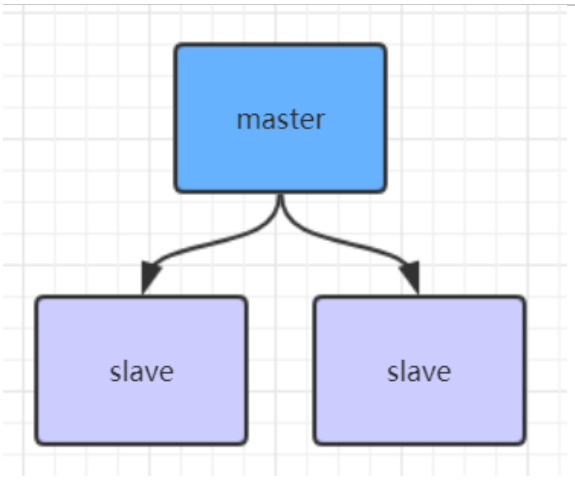
1、复制一份redis.conf文件 2、将相关配置修改为如下值: port 6380 pidfile /var/run/redis_6380.pid # 把pid进程号写入pidfile配置的文件 logfile "6380.log" dir /usr/local/redis-5.0.3/data/6380 # 指定数据存放目录
# 需要注释掉bind # bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可) 3、配置主从复制 replicaof 本机的IP 6379 # 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof replica-read-only yes # 配置从节点只读 4、启动从节点 redis-server redis.conf # redis.conf文件务必用你复制并修改了之后的redis.conf文件 5、连接从节点 redis-cli -p 6380 6、测试在6379实例上写数据,6380实例是否能及时同步新修改数据 7、可以自己再配置一个6381的从节点
Redis主从工作原理

数据部分复制:断点续传

主从复制风暴
如果主节点挂载的从节点太多,那么就可能会导致主节点复制压力太大,从而影响对外部的服务。降低redis的可用性。这就是主从复制风暴。为了避免这样的情况发生,可以将从节点挂载到从节点上,形成分层的结构。主节点直连的从节点数量降低。
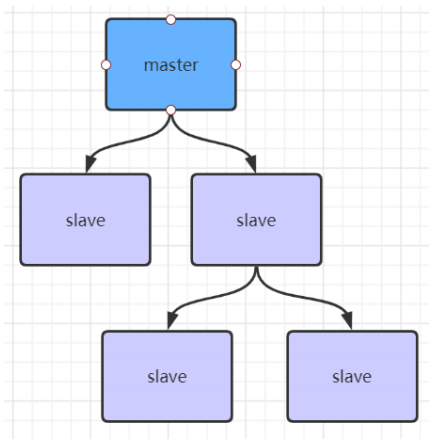
主从架构的优缺点
Redis的主从架构(Master-Slave)是一种常用的数据复制和扩展策略,其优缺点主要体现在以下几个方面:
优点:
- 数据备份和容灾:主从架构提供了数据的备份功能,从节点可以实时或异步地复制主节点的数据,确保数据的可靠性。当主节点发生故障时,从节点可以迅速切换为主节点,保证服务的连续性。
- 读写分离:主节点通常负责写操作,而从节点则负责读操作。这种读写分离的策略可以显著提高系统的性能,因为读操作通常比写操作更频繁,而多个从节点可以并行处理读请求。
- 扩展性:主从架构允许通过增加从节点的数量来扩展系统的读性能。当读请求量增加时,可以添加更多的从节点来分担读压力。
- 灵活性:主从架构支持多种同步策略,如全量同步和增量同步。全量同步适用于主从节点之间数据量差异较大的情况,而增量同步则适用于数据量差异较小的情况。
缺点:
- 可靠性问题:虽然主从架构提供了数据备份的功能,但仍然存在可靠性问题。如果主节点和从节点同时宕机,那么整个系统将无法提供服务。此外,如果主节点在宕机前有部分数据未能及时同步到从节点,那么在切换主节点后可能会导致数据不一致的问题。如果主节点异常,从节点并不能主动顶上去,还需要人工干预。
- 复杂性和管理成本:主从架构的配置和管理相对复杂,需要确保主节点和从节点之间的网络连接稳定可靠,并需要定期监控主从节点的状态和性能。此外,当需要添加或删除从节点时,也需要进行额外的配置和管理操作。
- 延迟问题:由于从节点需要复制主节点的数据,因此存在一定的延迟。这种延迟可能会影响系统的实时性和一致性。特别是当主节点的写操作非常频繁时,从节点的延迟可能会更加严重。
- 容量和性能瓶颈:虽然从节点可以扩展系统的读性能,但整个系统的容量和性能仍然受限于主节点的处理能力。如果主节点的处理能力不足,那么即使添加再多的从节点也无法提高系统的整体性能。
综上所述,Redis的主从架构具有数据备份、读写分离、扩展性和灵活性等优点,但也存在可靠性问题、复杂性和管理成本、延迟问题以及容量和性能瓶颈等缺点。因此,在选择是否使用主从架构时需要根据具体的业务需求和场景进行权衡和决策。
管道(Pipeline)
事务
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
命令:
| 1 | DISCARD 取消事务,放弃执行事务块内的所有命令。 |
| 2 | EXEC 执行所有事务块内的命令。 |
| 3 | MULTI 标记一个事务块的开始。 |
| 4 | UNWATCH 取消 WATCH 命令对所有 key 的监视。 |
| 5 | WATCH key [key ...] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。 |
注意事项:
lua脚本
哨兵架构
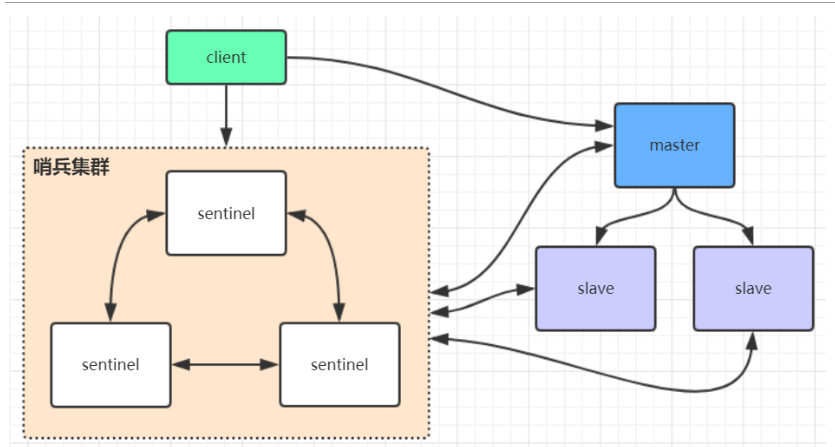
哨兵启动流程
在Redis哨兵架构中,通常需要先启动服务节点(主节点和从节点),然后再启动哨兵节点。
这是因为哨兵节点的作用是监控Redis节点的状态,并在主节点发生故障时自动将从节点切换为主节点,从而实现自动故障转移。如果先启动哨兵节点而没有服务节点可监控,那么哨兵节点将无法正常工作。具体来说,启动Redis哨兵架构的步骤大致如下:
- 配置并启动Redis服务节点,包括主节点和从节点。
- 配置Redis哨兵,指定要监控的主节点和从节点的信息。这可以通过配置文件或命令行参数来完成。
- 启动Redis哨兵节点。在启动后,哨兵节点会开始监控指定的Redis节点,并等待故障转移事件的发生。
需要注意的是,在启动哨兵节点之前,必须确保主从模式已经正确安装和配置,并且所有的Redis工作节点都已经正常运行。这是因为哨兵模式依赖于主从模式来监控Redis节点的状态,并在必要时进行故障转移。
哨兵搭建过程
1、复制一份sentinel.conf文件
cp sentinel.conf sentinel-26379.conf
2、将相关配置修改为如下值:
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis-5.0.3/data"
# sentinel monitor <master-redis-name> <master-redis-ip> <master-redis-port> <quorum>
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
sentinel monitor mymaster 本机IP 6379 2 # mymaster这个名字随便取,客户端访问时会用到,必须是要和客户端访问值一模一样
3、启动sentinel哨兵实例
src/redis-sentinel sentinel-26379.conf
4、查看sentinel的info信息
src/redis-cli -p 26379
127.0.0.1:26379>info
可以看到Sentinel的info里已经识别出了redis的主从
5、可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改
sentinel known-replica mymaster 192.168.0.60 6380 #代表redis主节点的从节点信息
sentinel known-replica mymaster 192.168.0.60 6381 #代表redis主节点的从节点信息
sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵节点
当redis主节点如果挂了,哨兵集群会重新选举出新的redis主节点,同时会修改所有sentinel节点配置文件的集群元数据信息,比如6379的redis如果挂了,假设选举出的新主节点是6380,则sentinel文件里的集群元数据信息会变成如下所示:
sentinel known-replica mymaster 192.168.0.60 6379 #代表主节点的从节点信息
sentinel known-replica mymaster 192.168.0.60 6381 #代表主节点的从节点信息
sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵节点
sentinel monitor mymaster 192.168.0.60 6380 2
当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点加入集群
哨兵架构的优缺点
Redis哨兵(Sentinel)系统是Redis用来实现高可用性和监控的工具,它能够帮助管理多个Redis服务器实例,并在出现故障时进行适当的动作,比如自动故障迁移或发送警告。以下是Redis哨兵架构的一些优缺点:
优点:
1. 高可用性:哨兵系统能够确保在主Redis实例出现故障时,自动将备用实例提升为新的主实例,以实现服务的持续可用性。
2. 监控:哨兵会不断地监控Redis实例的健康状况,包括节点是否可达、是否响应命令等,并在出现问题时发出警告。
3. 故障迁移:当主Redis实例不可用时,哨兵可以根据配置的规则自动将一个从实例转换为主实例,以实现故障的无缝迁移。
4. 配置灵活:哨兵允许用户配置多种参数,如选举超时时间、故障转移的策略等,以适应不同的业务需求。
5. 支持多数据中心:哨兵支持设置多个哨兵实例,每个实例负责不同的Redis主从集群,这样就可以实现跨数据中心的故障转移能力。
缺点:
1. 复杂性:相对于单实例的Redis,哨兵架构引入了更多的配置和组件,这可能会增加系统的复杂性。
2. 性能开销:哨兵系统会有一部分的性能开销,因为它需要监控和维护额外的信息,并处理故障转移等逻辑。
3. 多哨兵配置复杂:在复杂的环境中,多个哨兵之间的协调和配置可能会变得复杂,需要仔细规划。
4. 不支持读写分离:哨兵架构不支持传统的读写分离,因为从实例在故障转移时可能被提升为新的主实例。
5. 数据一致性:在某些复杂的故障转移情况下,可能会出现短暂的数据不一致问题,虽然Redis支持事务和持久化机制,但在极端情况下仍需注意数据一致性。
总体而言,Redis哨兵系统在提供高可用性和监控功能的同时,也带来了一定的复杂性和性能考虑。对于需要高可用性的Redis应用场景,哨兵是一个很好的选择,但在规划和部署时需要仔细考虑上述优缺点。
同时哨兵架构中,主节点会存储全部的数据,增加节点只是可以减少访问并发的压力,对写入内存压力来说没有什么提升。
哨兵模式下故障转移过程
在Redis哨兵(Sentinel)模式下,故障转移是指当主Redis实例因某些原因不可用时,哨兵系统将会触发一个流程,将一个从实例(Slave)升级为新的主实例(Master),并确保所有从实例跟随新的主实例。以下是故障转移的基本流程:
1. **监控状态**:哨兵系统持续监控Redis主实例和从实例的健康状态。它通过向实例发送PING命令并监听实例的回复来判断实例是否健康。
2. **故障检测**:如果哨兵检测到主实例不可达或者响应命令出现异常,它将认为主实例出现了故障。
3. **选举过程**:当哨兵确定主实例不可用时,它将开始一个选举(Election)过程。选举过程中,哨兵会尝试联系其他哨兵实例,以确定是否有其他哨兵已经发起了一个有效的选举。
4. **领导者选举**:如果哨兵实例在选举过程中被选为领导者(Leader),它将负责协调故障转移过程。如果多个哨兵实例同时争夺领导地位,它们将通过一个基于Redis投票机制的方式决定领导者。
5. **命令复制**:领导者哨兵会从剩余的从实例中选择一个实例(通常是具有最高运行序号的实例)作为新的主实例,并通过Redis命令复制协议(REPL)来同步这个实例的内存状态到其他从实例。
6. **更新配置**:一旦新的主实例被选举出来,哨兵将更新配置,使得其他从实例开始复制新的主实例的数据。这个过程可能包括更新从实例的配置文件或者直接通过Redis命令来更改从属关系。
7. **故障转移完成**:在新的主实例准备好并配置所有从实例之后,故障转移过程完成。此时,哨兵会向客户端发送消息,告知它们新的主实例的位置,客户端可以根据这个信息更新它们的连接。
8. **后续处理**:旧的故障的主实例在恢复后,可能会被配置为从实例并开始复制新的主实例的数据,或者根据具体情况被移除或重新配置。
整个故障转移过程是由哨兵系统自动完成的,不需要人工干预。但是,为了确保故障转移的顺利进行,需要正确配置哨兵系统,包括指定主实例和从实例、设置选举超时时间、配置故障转移策略等。
故障转移中如何保证数据的一致性
在Redis哨兵(Sentinel)模式的故障转移过程中,确保数据一致性是一个重要的考虑点。以下是一些措施和机制,用于确保在故障转移过程中数据的一致性:
1. **写入确认**:在故障转移过程中,新的主实例在接替旧的主实例之前,会等待一些写入操作被确认。这可以通过配置参数`redis-sentinel min-slaves-to-write`来实现,它指定了一个最小数量的从实例必须处于“在线”(UP)状态,主实例才能执行写操作。
2. **复制偏移量**:Redis使用复制偏移量(replication offset)来跟踪主实例和从实例之间数据同步的位置。在故障转移过程中,新的主实例会等待直到它的复制偏移量追赶上其他从实例,确保从实例有最新的一致性数据。
3. **断线重连**:在故障转移后,从实例会尝试与新的主实例重新建立连接,并继续同步数据。如果从实例在一定时间内无法连接到新的主实例,它会尝试重新连接到旧的 主实例(如果旧的 主实例恢复了),这样可以避免数据不一致。
4. **配置更新**:故障转移后,从实例会根据新的主实例信息更新它们的配置,确保所有从实例都知道新的主实例的位置。
5. **Sentinel监控**:哨兵系统会继续监控所有实例的健康状态,并在检测到任何不一致性时采取行动。例如,如果一个从实例落后于新的主实例太多,哨兵可能会尝试将该从实例从旧的 主实例那里重新同步数据。
6. **客户端重连**:客户端应用需要监听主实例的变化,并在必要时更新它们连接的主实例。通常,这可以通过使用Redis客户端的哨兵支持来实现,客户端会自动重连到新的主实例。
7. **持久化机制**:Redis提供了数据持久化机制,如RDB快照和AOF日志,这些机制可以帮助在故障转移后恢复数据。确保在故障转移前有最新的快照或AOF日志重做,可以减少数据不一致的风险。
通过上述机制,Redis哨兵系统在故障转移过程中尽量保证了数据的一致性。然而,在实际操作中,特别是在故障转移的初期阶段,可能会存在短暂的数据不一致。因此,设计系统时应考虑这种短暂的不一致性,并在必要时实施额外的数据一致性保障措施。
请推荐一些确保数据一致性的最佳实践。
确保数据一致性是分布式系统设计中的一个重要方面,特别是在像Redis这样的数据存储系统中。以下是一些确保数据一致性的最佳实践:
1. **使用同步复制**:在Redis中,确保使用同步复制(sync replication)模式,这样主实例在写入数据后,会等待从实例确认接收到了这些数据,然后再回复客户端。这可以通过设置`replica-ping-timeout`和`replica-offset-threshold`参数来调整。
2. **最小同步偏移量**:通过设置`min-slaves-to-write`参数,可以指定主实例需要至少有一定数量的从实例处于在线状态并且同步偏移量小于阈值时,才能执行写操作。这样可以确保主实例写入的数据被至少一个从实例确认。
3. **使用Redis事务**:虽然Redis事务不能像关系型数据库那样保证原子性和一致性,但在执行涉及多个操作的任务时,使用`MULTI`、`EXEC`、`DISCARD`和`WATCH`命令可以帮助避免部分写入问题。
4. **使用Lua脚本**:对于复杂的操作,可以使用Lua脚本在Redis中执行,这样可以确保多个步骤要么全部成功,要么全部失败,从而保持数据的一致性。
5. **快照和持久化**:定期创建RDB快照和/或使用AOF日志记录所有的写操作,可以帮助在系统故障时恢复数据。确保在发生故障转移之前有最新的快照或AOF日志重做。
6. **哨兵和集群配置**:正确配置Redis哨兵,确保它在检测到故障时可以正确地执行故障转移。同时,如果使用Redis集群,确保集群模式下的数据分布和复制配置是合理的。
7. **监控和报警**:实施监控系统来跟踪Redis实例的健康状态和性能指标。在检测到任何异常时,确保有报警系统通知运维人员。
8. **分散式锁或事务管理**:在需要原子性操作的场景中,可以使用分散式锁或者其他事务管理工具(如Redis事务或基于Redis的分布式锁库)来确保数据一致性。
9. **客户端重试机制**:在客户端实现重试机制,当遇到数据不一致或服务不可用时,可以尝试重新连接或重新执行操作。
10. **最小化数据不一致窗口**:在设计系统时,尽量减少数据不一致性的窗口时间。例如,使用分布式消息队列或其他队列技术来缓冲写入操作,直到数据一致性得到保证。
11. **定期审查和测试**:定期审查系统的数据一致性措施,并进行故障转移和恢复流程的测试,以确保在实际故障发生时,系统能够按照预期工作。
这些实践可以帮助设计更加健壮和一致性的Redis应用程序,但需要注意的是,在分布式系统中完全消除数据不一致性是不可能的,关键是要在可用性和一致性之间找到合适的平衡点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号