表格
表格是一个非常好的工具,在没有数据库的情况下,也是可以存储大量的数据信息,基于此,我们对表格的操作要更加的细致。
python拥有非常多的处理表格数据的第三方库,我们使用的是xlrd、xlw和xlutils。
(一)简单基础的表格数据的读取:表格--行列--单元格
#coding:utf-8 import xlrd import xlwt #对于Excel表格的操作,我们首先要学会读数据,分步进行 #打开表格--读取里面的表--表数据获取 data = xlrd.open_workbook("中科启信通讯录.xls") table = data.sheets()[0] table1 = data.sheet_by_index(0) table2 = data.sheet_by_name("员工通讯录") # 三中获取表格方式得到的是一个表格,都是中科启信通讯录.xls这个word里面的第一个表格,数据源已经get #获取表格的行数和l列数 rows = table.nrows cols = table.ncols #获取每一行的数据 for i in range(rows): print(table.row_values(i)) #获取每一列的数据 for i in range(cols): print(table.col_values(i)) #获取单元格的数据 print(table.cell(0,0).value) #通过行列获取单元格的数据 print(table.row(0)[0].value) print(table.col(0)[0].value)
(二)表格中常见的逻辑处理
(1)统计一些字段的出现次数或根据出现次数做的统计
#coding:utf-8 import xlrd import xlwt import xlutils.copy as copy import matplotlib.pyplot as plt work_book = xlrd.open_workbook("../../文本/中科启信通讯录.xls") table = work_book.sheets()[0] #对于第一张表格的数据,我们可以看到有效数据从第三行到第三十九行 #统计公司一共有多少部门,并统计出部门人数 #第三张表格的男女比例的计算也是如此计算步骤 officeCounts =[] for i in range(2,39): for j in [2,6,10,14]: if(table.cell(i,j).value != ""): officeCounts.append(table.cell(i,j).value) officeCountsPeo ={} for off in officeCounts: officeCountsPeo[off] = officeCountsPeo.get(off,0)+1 #序列化,可以对人数进行排序 #将得到的部门和部门人数变成一个元素是元组的列表 officeCountsPeoLis = list(officeCountsPeo.items()) officeCountsPeoLis.sort(key= lambda x:x[1], reverse = True) #创建要操作的表格,并且增加一个表,用作部门人数统计 book = copy.copy(work_book) #判断这个表格是否已经存在了,因为可能运行过此程序一次了 table_name = work_book.sheet_by_name("部门人数") if not table_name: work_table = book.add_sheet("部门人数") work_table.write(0, 0, '部门') work_table.write(0, 1, '人数') for i in range(len(officeCountsPeoLis)): work_table.write(i + 1, 0, officeCountsPeoLis[i][0]) work_table.write(i + 1, 1, officeCountsPeoLis[i][1]) # 将写入的数据进行保存 book.save("../../文本/中科启信通讯录.xls") #将数据读出来进行画图 plt.rcParams['font.sans-serif'] = ['KaiTi'] plt.rcParams['font.serif'] = ['KaiTi'] plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符串 plt_table = work_book.sheet_by_name("部门人数") plt.figure(figsize=(10,10)) x_label = plt_table.col_values(0)[1:] x = range(len(x_label)) y = plt_table.col_values(1)[1:] rect = plt.bar(x, height=y,color="orange", width=0.4,alpha=0.8,label="部门人数") for re in rect: height = re.get_height() plt.text(re.get_x() + re.get_width() / 2, height + 1, str(height), ha='center', va='bottom') plt.xlabel("部门") plt.ylabel("人数") plt.ylim(0,40) plt.title("部门人员人数统计") plt.xticks(x,x_label,rotation=45) plt.legend() plt.show()
结果:根据我们的分析,我们将每个部门的人数进行了统计,然后把统计的数据写入到了我们创建的一个新的表格中,最后根据写入的数据进行画图分析。
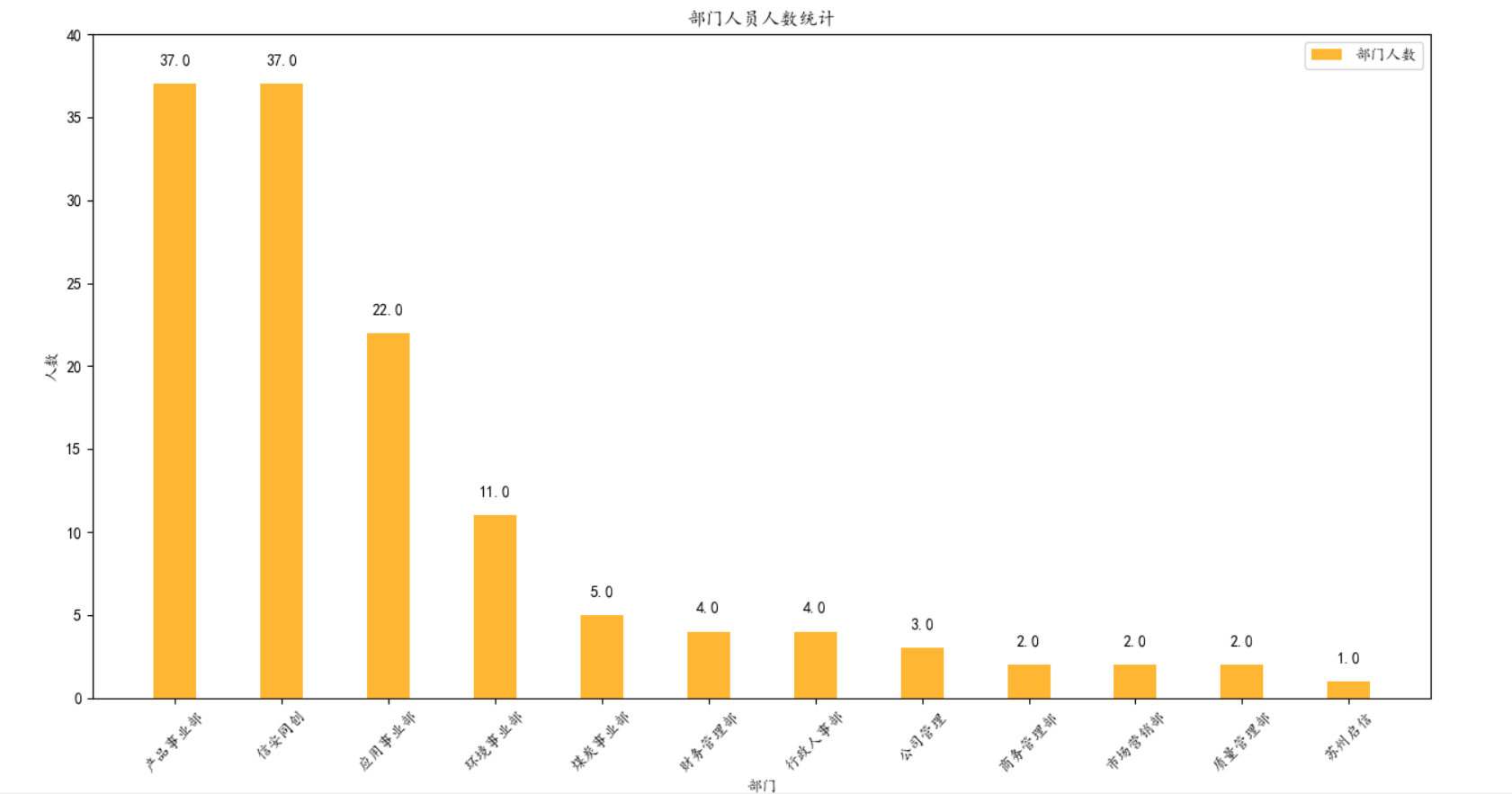
(2)表格数据的一些简单整理
#coding:utf-8 import xlrd import xlwt work_book = xlrd.open_workbook("../../文本/中科启信通讯录.xls") table = work_book.sheets()[0] #对于第一张表格的数据,我们可以看到有效数据从第三行到第三十九行 #表格的每一条记录都是四个人的信息,要将每个人的信息分隔开,每四列是一个人的信息 #同样的,对于第三张表格,每六列是一个人的信息的切分也是如此 rowsInf = [] for i in range(2,39): rowsInf.append(table.row_values(i)) peoInf = [] for row in rowsInf: for j in range(len(row)//4): if(row[4*j] != ''): peoInf.append(row[4*j:4*j+4])
(三)表格数据作为画图的数据源
参考我们在上面画的张图片,我们使用画图的方式统计公司的工资的分配。我们根据工资构成,将工资体系分成4个等级0-5K-10K-15K-20K。
#coding:utf-8 import xlrd import xlwt import xlutils.copy as copy import matplotlib.pyplot as plt work_book = xlrd.open_workbook("../../文本/中科启信通讯录.xls") table = work_book.sheet_by_name('员工工资表') # 有些数据的数据类型是string,先进行数据的预处理,将string和float的数据区分 #使用余数与字典解决,要比使用数组,然后判断工资范围代码简单的很多 #首先把要处理的数据取出来 sals = [] for i in range(1,38): for j in [4,10,16,22]: if(table.cell(i,j).value != ''): sals.append(table.cell(i,j).value) #然后根据工资与5000的整除值判断等级,计算每个等级的个数 #整除值为0:工资小于5000 #整除值为1:工资5000--10000 #整除值为2:工资10000--15000 #整除值为3:工资15000--20000 saladengji = {} for sal in sals: dengji = sal//5000 if(dengji==0): dengji ='小于5K' elif(dengji==1): dengji ='5K-10K' elif(dengji==2): dengji = '10K-15K' else: dengji ='15K以上' saladengji[dengji] = saladengji.get(dengji,0)+1 salaryList = list(saladengji.items()) salaryList.sort(key=lambda x:x[1], reverse=False) book = copy.copy(work_book) #还是有BUG,第一次执行的时候肯定没有这个表 # 想法是判断一下表格里是否有这个表 #先去上课,回来再说吧,要使用try-catch table_name = work_book.sheet_by_name("工资统计") if not table_name: work_table = book.add_sheet("工资统计") work_table.write(0,0,'工资等级') work_table.write(0,1,'人数') for i in range(len(salaryList)): work_table(i+1,0,salaryList[i][0]) work_table(i+1,1, salaryList[i][1]) book.save("../../文本/中科启信通讯录.xls") #将数据读出来进行画图 plt.rcParams['font.sans-serif'] = ['KaiTi'] plt.rcParams['font.serif'] = ['KaiTi'] plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符串 plt.figure(figsize=(10,10)) x_label = table_name.col_values(0)[1:] y = table_name.col_values(1)[1:] x = range(len(x_label)) rect = plt.bar(x, height=y, width=0.4, color="orange", alpha=0.8,label ='工资范围') for re in rect: height = re.get_height() plt.text(re.get_x() + re.get_width() / 2, height + 1, str(height), ha='center', va='bottom') plt.xlabel("工资等级") plt.ylabel("人数") plt.title("工资工资分布") plt.ylim(0,50) plt.xticks(x, x_label,rotation=45) plt.legend() plt.show()
结果: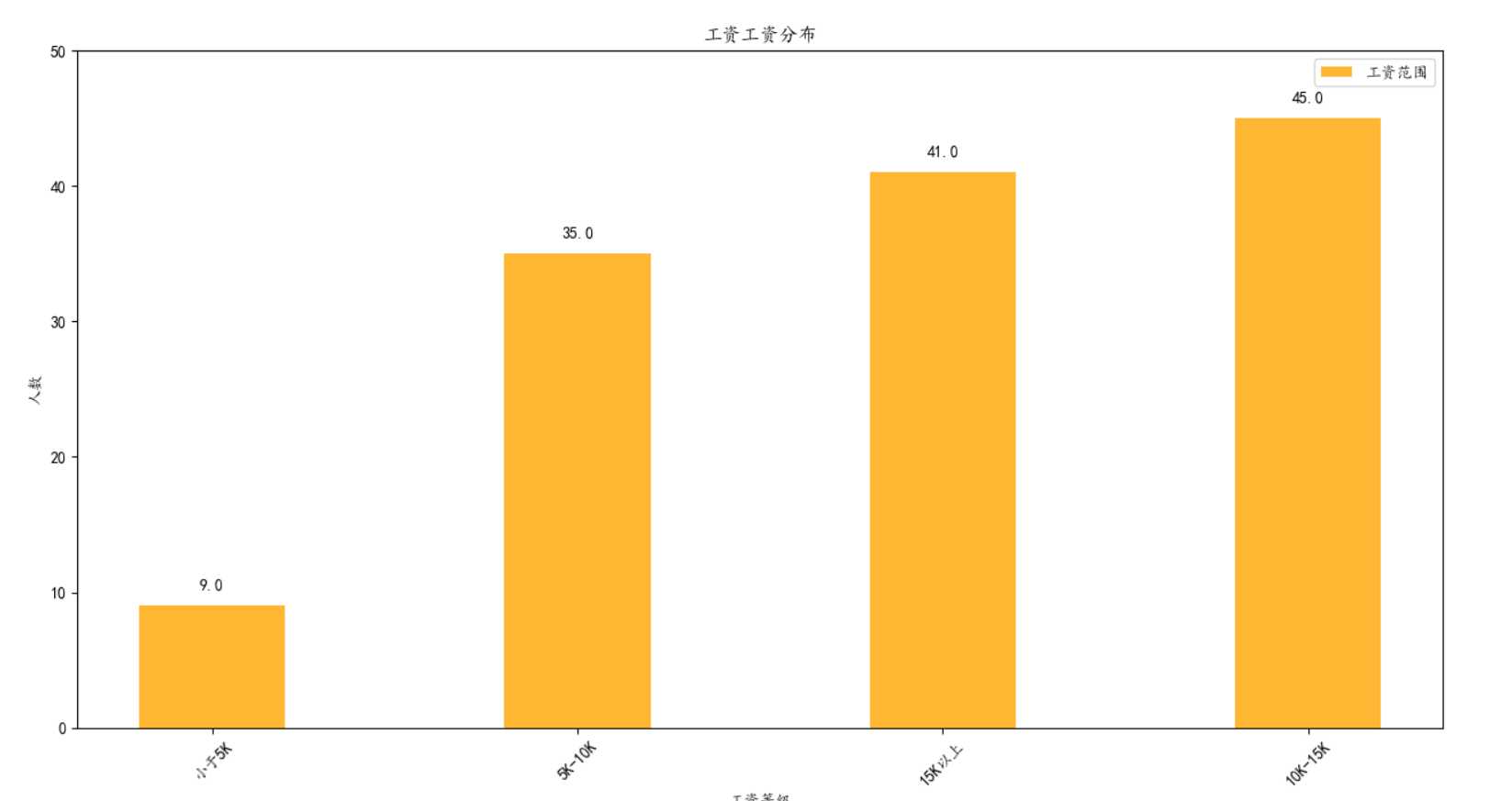

 浙公网安备 33010602011771号
浙公网安备 33010602011771号