《机器学习》第一次作业——第一至三章学习记录和心得
第一章 模式识别基本概念
1.1 什么是模式识别
- 模式识别: 即给定一个模式(可以是图片,音频等,往往传入的是向量),判别出其属于的类别或对应的回归值
- 分类包括二类和多类分类
- 本质上是一个推理的过程
1.2 模式识别数学表达

- 模式识别相当于是一个特殊的函数,输入的是模式

- 模型: 即y = f(x)
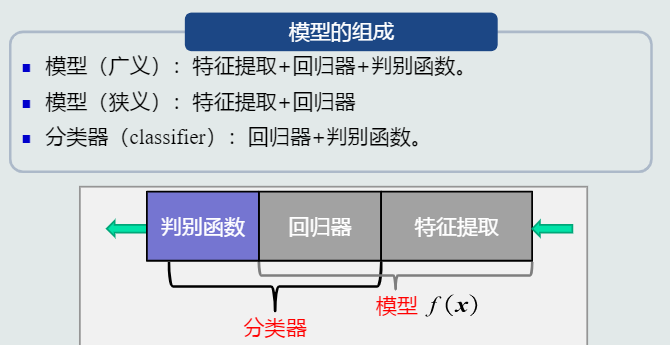
- 判别器有二类分类和多类分类
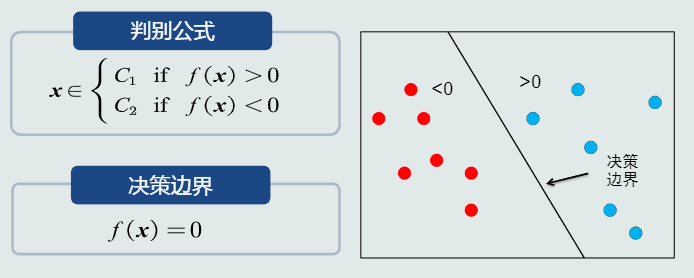
- 特征: 可以区分不同类别模式的,可测量的量



- 特征空间: 模式所在空间,每一个坐标对应特征的一个维度,每个点对应一个模式
1.3 特征向量的相关性
- 每个特征向量代表一个模式
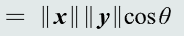

- 投影不具备对称性,表示了向量x分解到向量y方向上的程度
可以表示为

1.4 机器学习基本概念


机器学习就是一种确定模型参数的方式
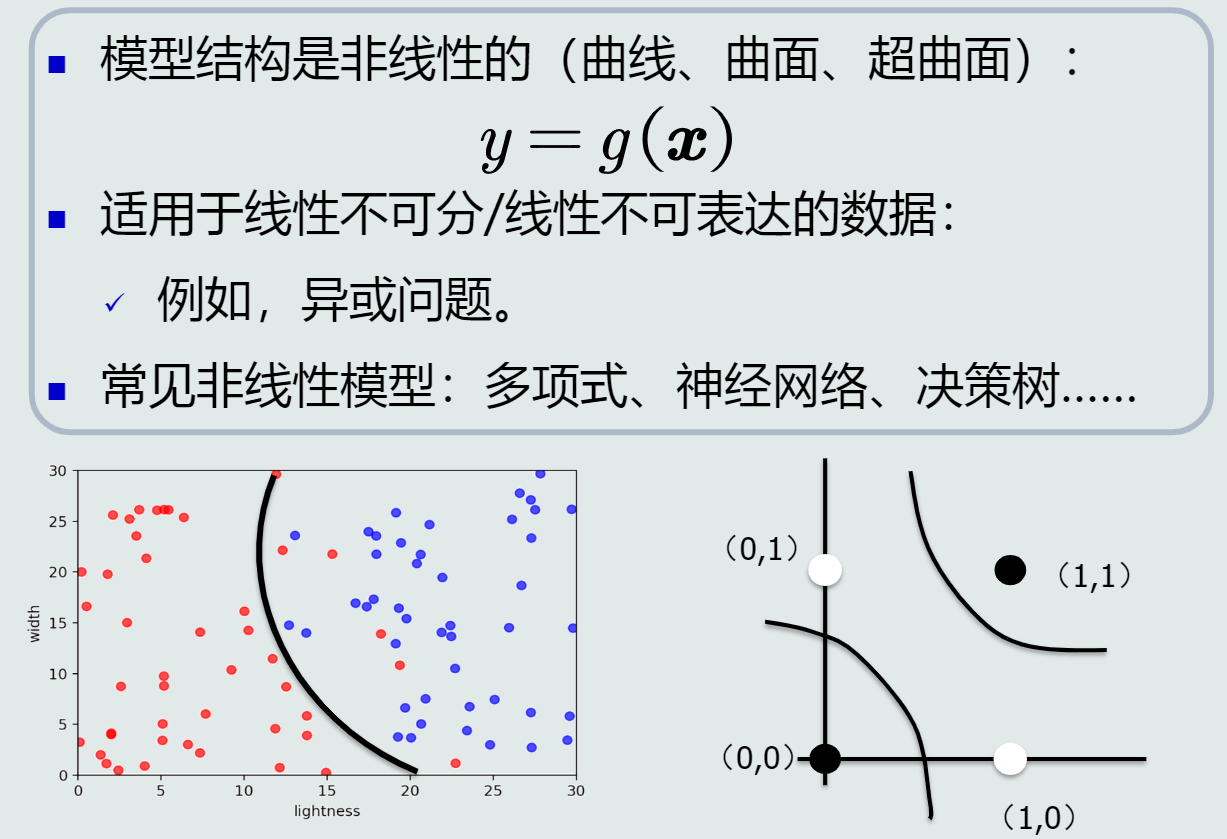
- 线性模型&非线性模型

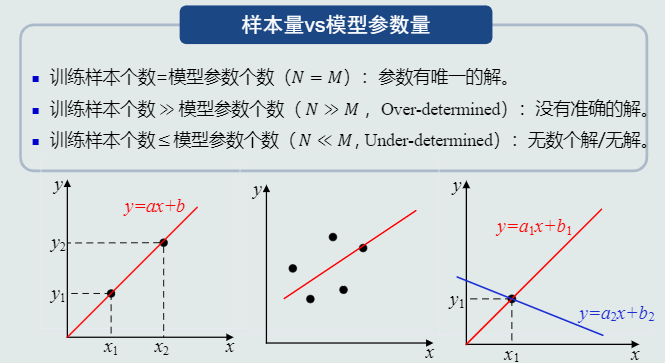
- 训练样本个数 等于 模型参数 最好
- 目标函数,就是添加一个标准,是一个最优化的目标,利用这个标准通过训练样本算出参数

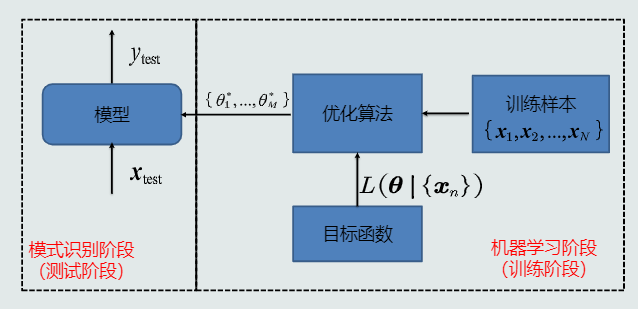
- 机器学习的方式

- 主要分为监督式学习和非监督式学习


1.5模型的泛化能力
- 基本概念:训练集&测试集、训练误差&测试误差



- 泛化能力是模型十分重要的能力之一,为了提升模型的泛化能力,训练时往往不会把所有的样本都正确归类(存在部分比较特殊的样本),若是强行在训练时让模型迁就所有的样本,则会出现过拟合的情况
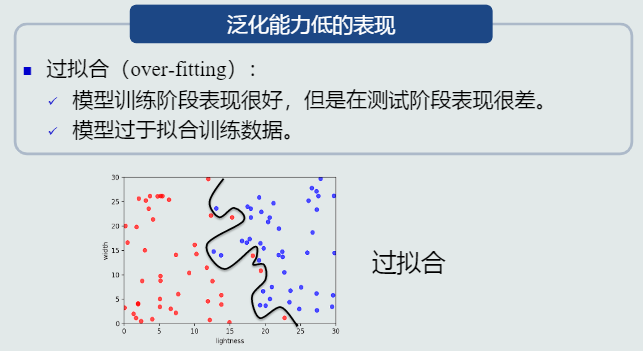
- 如何提升泛化能力

-
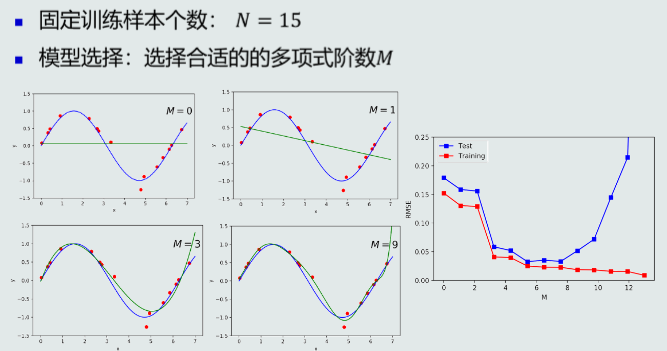
多项式拟合&超参数

-
提高泛化能力:模式选择、正则化,通过调节正则系数,可以降低过拟合的程度

1.6 评估方法与性能指标
- 评估方法


留一验证: 即K = N的K折交叉验证

- 性能指标度量

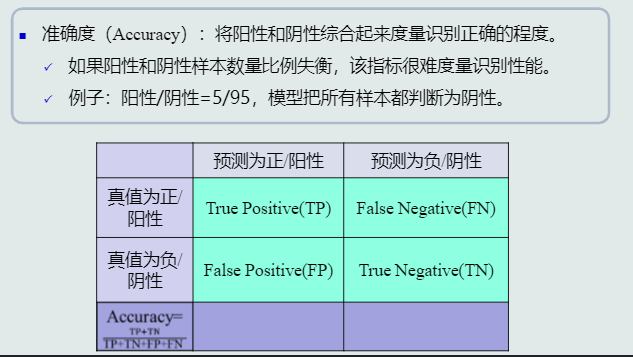



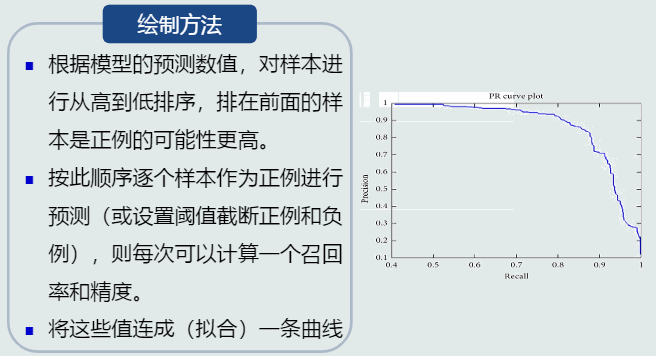
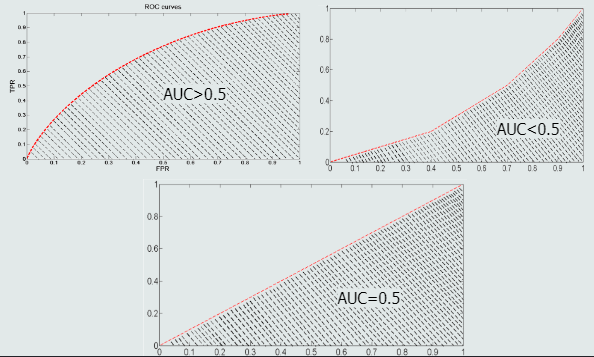
- 性能指标还有: 混淆矩阵,PR曲线、ROC曲线、AUC

第二章 基于距离的分类器
2.1 MED分类器

2.2 特征白化

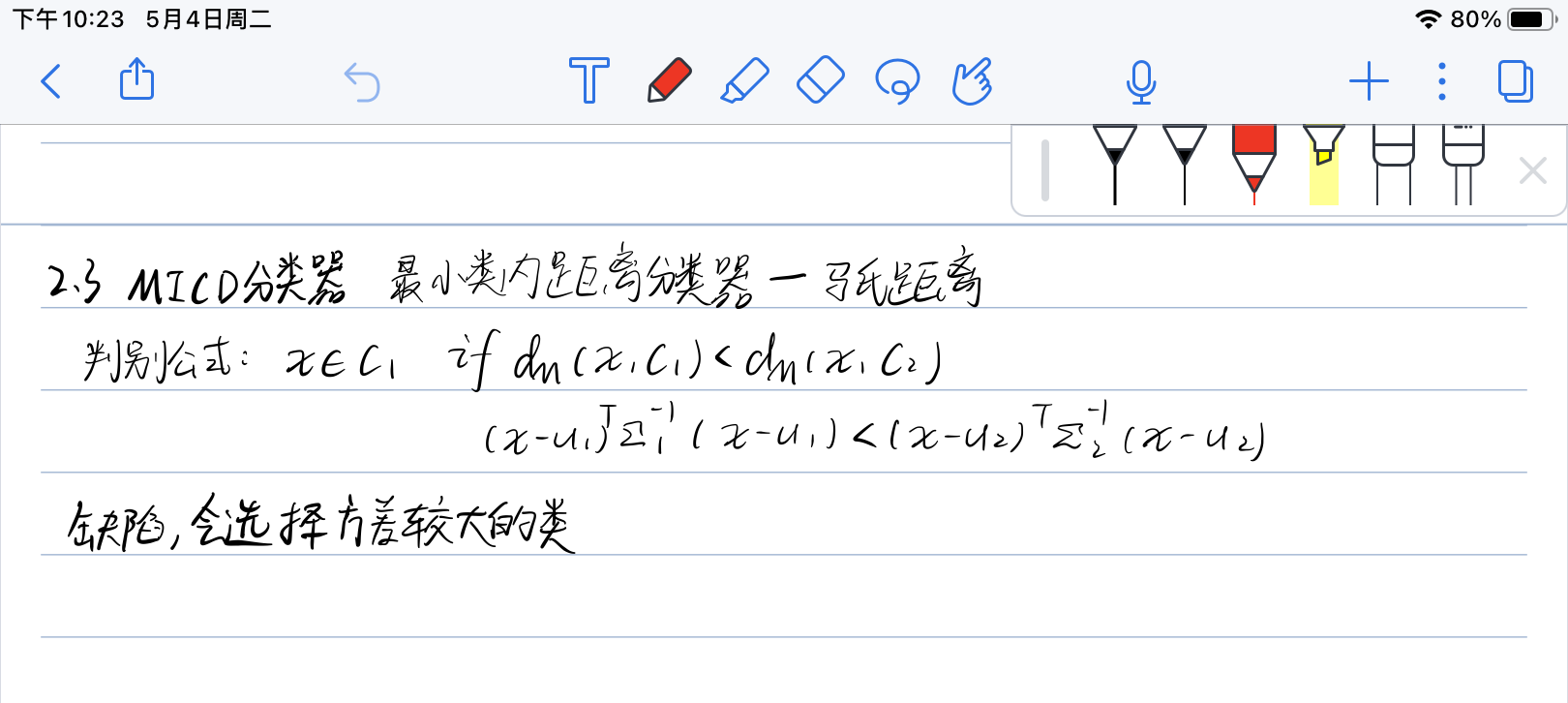
2.3 MICD分类器
- 其实就是距离变成马氏距离的MED分类器
第三章 贝叶斯决策与学习
3.1贝叶斯决策与MAP分类器

3.2 MAP分类器、高斯观测概率
- MAP分类器其实就是根据后验概率去决策

3.3 决策风险与贝叶斯分类器
- 贝叶斯分类针对于所有类,决策根据是决策成某类的风险

3.4 最大似然估计
- 最大似然估计把参数θ、Σ当做是不变量,指定目标函数从而确定参数

3.5 最大似然的估计误差
- 根据计算,Um的最大似然估计是无偏估计,而Σml是有偏估计

3.6 贝叶斯估计(1)
- 贝叶斯估计把参数当做是随机变量,并假设θ的分布是高斯分布

3.7 贝叶斯估计(2)
- 将参数θ的观测似然概率的分布带入,得到x的后验概率分布仍然是一个高斯分布,且N->无穷时,贝叶斯分布越能代表真实的分布



3.8 KNN估计
- 当概率分布形式未知时,就需要使用五参数概率密度估计
- 包括 KNN估计、直方图技术和核密度估计


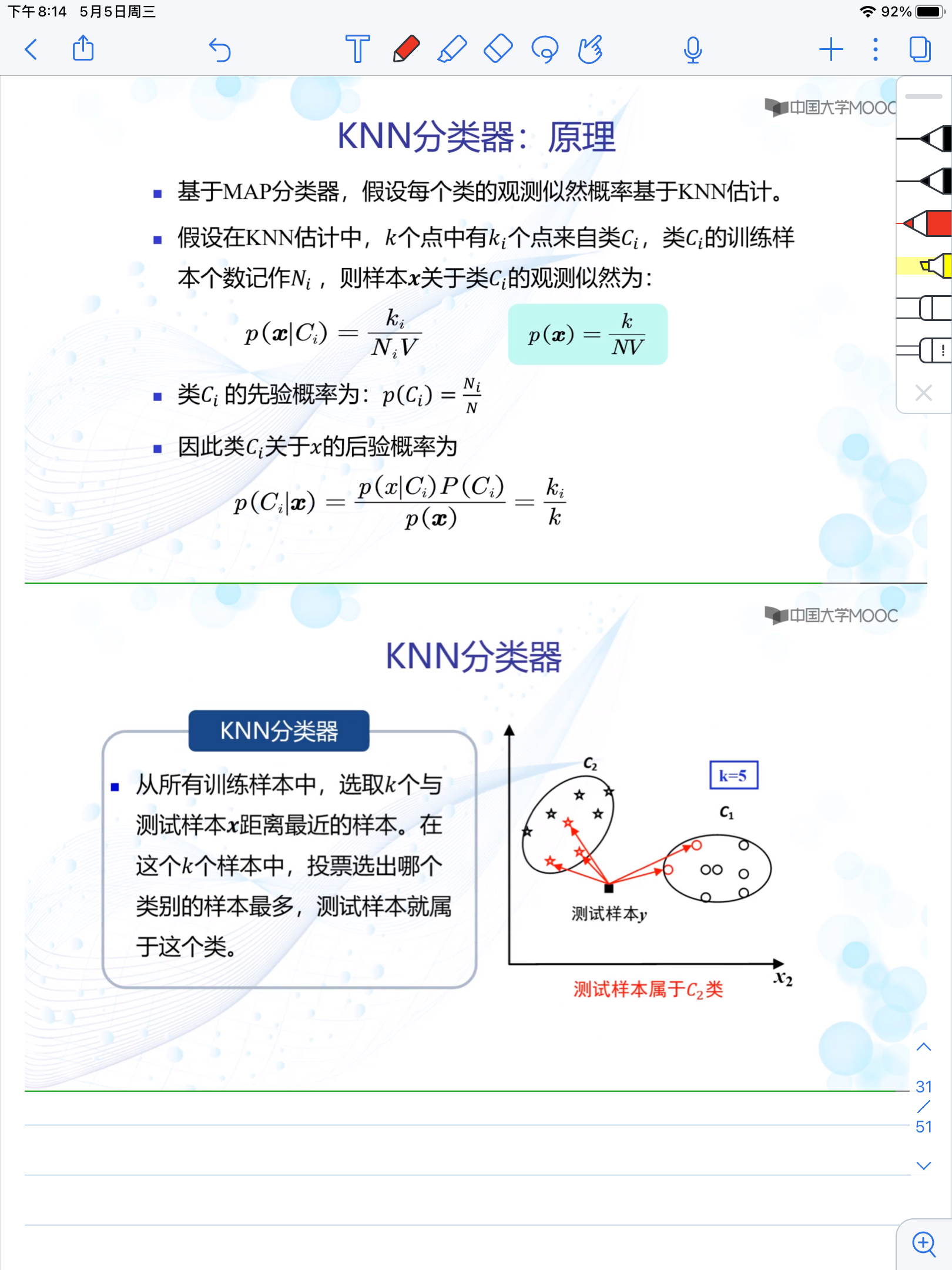
-
经总结,KNN分类估计就是确定k的大小,以x为中心划出一个区域包括k个样本,其中属于哪个类的样本最多,就判定x属于哪一类
-
KNN估计因为需要在x周围寻找k个相邻点,所以需要存储所有训练样本,且易受第k个紧邻点影响,所以易受噪音影响
3.9 直方图与核密度估计


- 核密度估计对KNN和直方图做了改进,有适应性



学习心得
机器学习是一门数学性的学科,对于没有基础的学生来说十分困难,比如说我,需要花费大量时间课后反复看慕课(还看不怎么懂)。但其实它本质上就是讲授如何确定一个模型并使用机器学习去求解模型参数,所以如果忽略掉一些细节,重点关注结论的话,好像也不是那么的难懂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号