什么是自然语言的概率分布
自然语言的概率分布,是指在自然语言处理(NLP)中,对语言单位(如单词、短语、句子等)出现的概率进行建模和描述的方式。 它反映了语言使用的统计规律,即某些语言单位比其他单位更常出现。
核心思想:
自然语言并非随机的字符组合,而是遵循一定的统计规律。有些单词、短语和句子结构比其他的更常见。概率分布捕捉了这些频率差异,并将其用于各种 NLP 任务。
几个关键层次的概率分布:
-
词汇级别 (Lexical Level):
- 单词频率 (Word Frequency): 最基本的分布,统计每个单词在语料库中出现的次数。遵循 Zipf 定律,少数单词(如 "the", "a", "of")出现频率极高,而大多数单词出现频率很低。
- n-gram 概率: 考虑单词序列的概率。
- Unigram (一元模型):
P(word),单个单词出现的概率。 它假设单词之间是独立的(这显然不符合自然语言的实际情况)。 - Bigram (二元模型):
P(word2 | word1),给定前一个单词,当前单词出现的条件概率。例如,"natural" 后面跟着 "language" 的概率会比跟着 "cat" 的概率高。 - Trigram (三元模型):
P(word3 | word1, word2),给定前两个单词,当前单词出现的条件概率。 - Higher-order n-grams: 更长的单词序列,理论上可以更好地捕捉上下文信息,但数据稀疏问题会更严重。
![]()
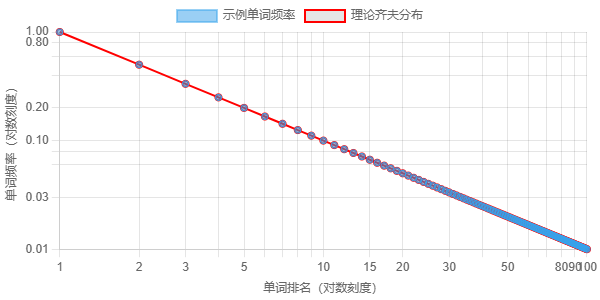
齐夫定律 指出,一个单词的频率与其在频率表中的排名成反比。 这张图展示了这种关系。最常见的单词(排名 1)比第二常见的单词频繁得多, 以此类推。x 轴表示单词的排名(对数刻度),y 轴表示单词的频率 (对数刻度)。红线代表理论上的齐夫分布,蓝点是 示例数据点。
- Unigram (一元模型):
-
句法级别 (Syntactic Level):
- 短语结构概率: 描述句子如何由短语组成的概率。例如,一个句子由名词短语(NP)后跟动词短语(VP)组成的概率。
- 依存关系概率: 描述单词之间的句法依存关系(例如主谓关系、动宾关系)的概率。 例如,"The cat" 中 "cat" 作为 "The" 的定语的概率。
- 概率上下文无关文法 (PCFG): 一种形式语法,给每条语法规则赋予一个概率,从而描述整个句子的生成概率。
![]()
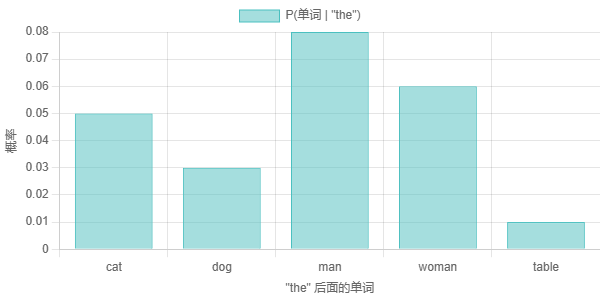
这张条形图显示了 bigram 概率的示例。x 轴显示前一个单词 ("the"),y 轴 显示下一个单词的概率。例如,P("cat" | "the") 可能为 0.05,这意味着在 单词 "the" 之后,下一个单词是 "cat" 的概率为 5%。这些概率来自一个 (假设的)语料库。请注意,某些单词比其他单词更有可能跟在 "the" 后面。
-
语义级别 (Semantic Level):
- 词义分布 (Word Sense Distribution): 一个单词可能有多个含义(词义),每个词义在不同上下文中出现的概率不同。
- 主题分布 (Topic Distribution): 一个文档或一组文档中,不同主题出现的概率。主题模型(如 LDA)用于估计这些概率。
- 语义角色分布 (Semantic Role Distribution): 描述动词与其论元(例如施事者、受事者)之间关系的概率。
![]()
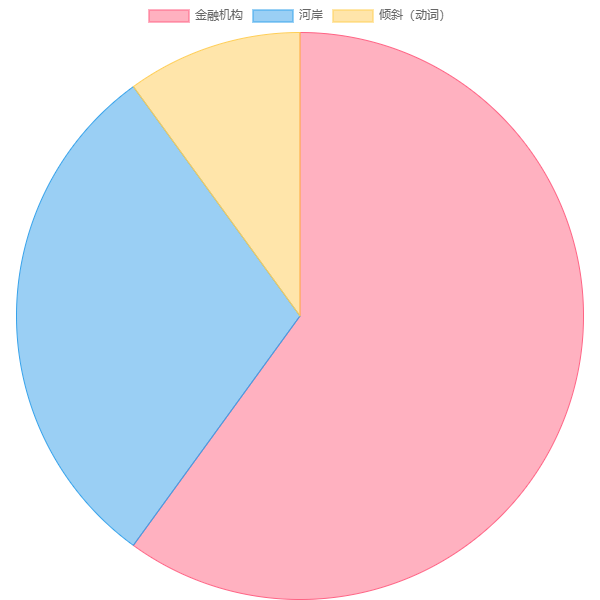
这张饼图展示了单词 "bank" 的词义分布。"bank" 这个词有多个含义(词义), 例如金融机构、河岸或表示“倾斜”的动词。该图显示了 给定语料库中每个词义的概率(或出现次数的比例)。
-
语篇/篇章级别 (Discourse Level)
- 句子间关系概率: 描述句子之间关系的概率(例如,因果关系、转折关系、并列关系)。
- 篇章结构概率: 描述篇章(例如,新闻报道、小说)如何组织成不同部分(例如,引言、正文、结论)的概率。
![]()
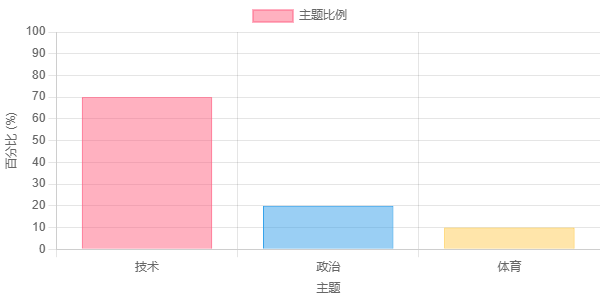
这张图表显示了单个文档中的主题分布,这可能是由主题模型(如潜在狄利克雷分配 (LDA))确定的。每个条形代表一个不同的主题(例如,“技术”、“政治”、“体育”),条形的高度代表该主题在文档中的比例。 一份文件可能主要关于“技术”(70%),其中有一些关于“政治”的讨论(20%),以及少量提及“体育”(10%)。 这是一个简化的表示; 真实的主题模型通常有更多的主题。
应用:
自然语言的概率分布在 NLP 中有着广泛的应用,包括:
- 语言模型 (Language Modeling): 核心任务,预测下一个单词或单词序列的概率。是许多 NLP 应用的基础(如机器翻译、语音识别、文本生成)。
- 拼写纠错 (Spell Correction): 根据上下文,选择最可能的正确拼写。
- 词性标注 (Part-of-Speech Tagging): 根据上下文,确定单词的词性(名词、动词、形容词等)。
- 句法分析 (Parsing): 构建句子的句法结构树。
- 机器翻译 (Machine Translation): 生成目标语言中概率最高的译文。
- 语音识别 (Speech Recognition): 将语音信号转换为文本,选择概率最高的单词序列。
- 文本生成 (Text Generation): 生成符合语法和语义规则的文本。
- 信息检索 (Information Retrieval): 根据查询,找到最相关的文档。
- 文本摘要 (Text Summarization): 生成文本的简短摘要。
- 问答系统 (Question Answering): 根据问题,找到最可能的答案。
- 情感分析 (Sentiment Analysis): 判断文本的情感倾向(积极、消极、中性)。
挑战:
- 数据稀疏 (Data Sparsity): 即使是大型语料库,也无法覆盖所有可能的语言现象。许多 n-gram(特别是高阶 n-gram)可能从未出现过,导致概率估计不准确。
- 长距离依赖 (Long-Distance Dependencies): n-gram 模型难以捕捉相距较远的单词之间的关系。
- 语义和语用 (Semantics and Pragmatics): 概率分布主要基于统计信息,难以完全捕捉语言的语义和语用信息。
- 领域适应性(Domain Adaptability): 在一个领域训练的模型,可能在另一个领域表现不佳。
总结:
自然语言的概率分布是 NLP 的基石,它通过统计语言数据来捕捉语言的规律。从简单的单词频率到复杂的句法和语义模型,概率分布为各种 NLP 任务提供了强大的工具。 尽管存在挑战,但随着深度学习的发展和更大规模语料库的出现,自然语言概率分布的研究和应用仍在不断进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号