

kafka压测
原文并未提及kafka的版本 并且测试的消息大小都偏小 测试数据供参考 原文还测试了broker等 原文请移步文章末尾
4.1 producer测试
4.1.1 batch-size
测试结果
测试结论
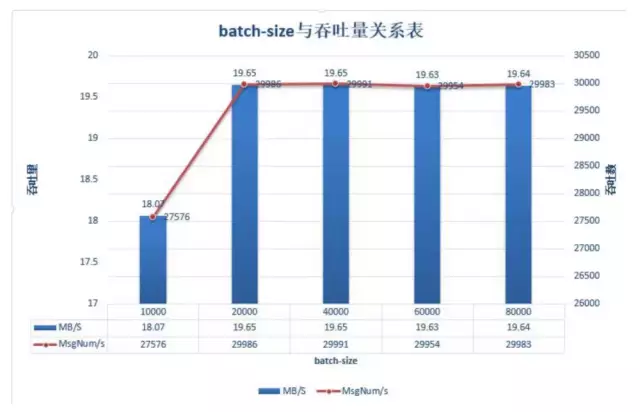
测试中通过我们增加batch-size的大小,我们可以发现在消息未压缩的前提下,20000条一批次之后吞吐稳定在19.65M/s。
4.1.2 ack
测试结果

测试结论

4.1.3 message-size

测试结论
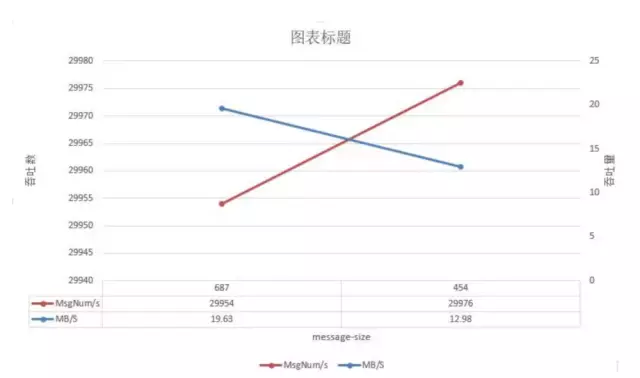
测试中通过我们使用两种不同的消息大小,发现在消息未压缩的前提下且其他参数一致的情况下,687字节的吞吐量是要优于454字节的,目前我们的两种消息为此大小,测试中发现当消息大小为4k时效果最优,也基本符合kafka设计用来传输10K左右的消息的初衷。
4.1.4 compression-codec
测试结果
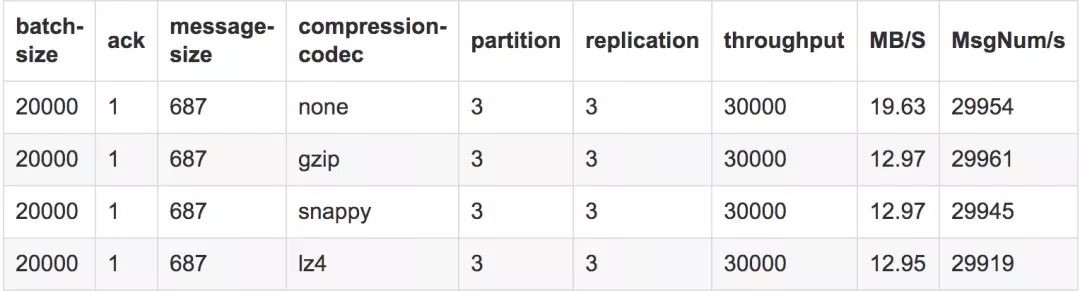
测试结论
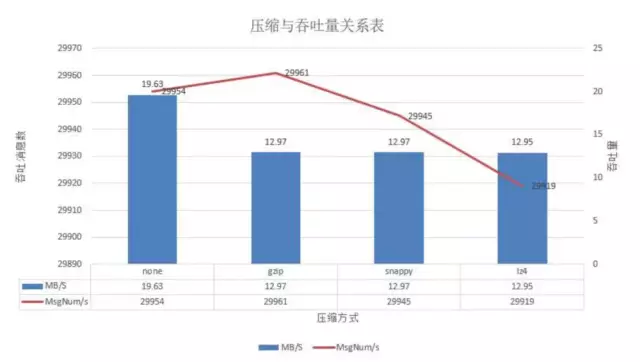
在batch-size为2w且并发量在3w时,可以看出来不压缩的吞吐量最好,其他的基本相差不大。
测试结果2
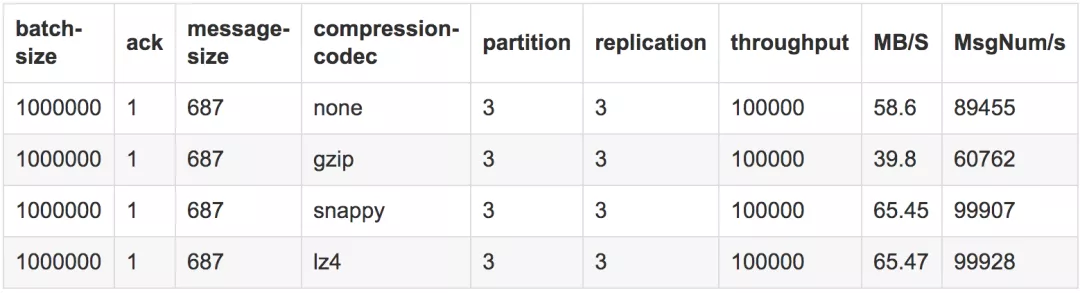
测试结论
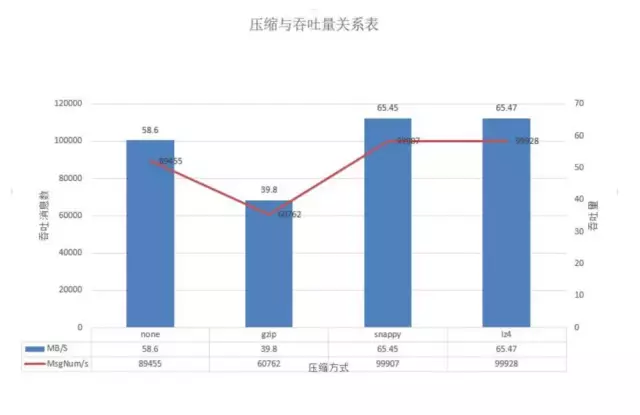
我们在后续测试中发现,在batch-size为100w且并发量在10w时,可以看出来snappy和lz4的吞吐量上升幅度明显,而gzip由于压缩的费时其吞吐最差,不压缩的在本测试中的吞吐次之。
测试结果3

测试结论

我们在后续测试中发现,在batch-size为100w且并发量在20w时,lz4的吞吐量优势明显达到19w/s,snappy次之为12.8w/s,而gzip由于压缩的费时其吞吐最差基本在5.8w/s,不压缩的在本测试中的吞吐也能达到11w/s。
测试结果4

测试结论
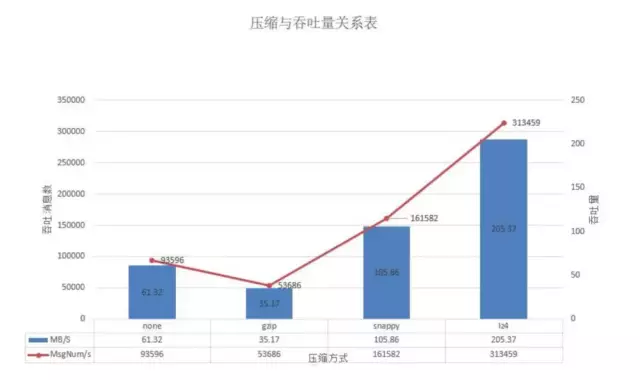
在batch-size为100w且并发量在50w时,lz4的吞吐量优势明显达到31.3w/s,snappy次之为16.1w/s,而gzip由于压缩的费时其吞吐最差基本在5.3w/s,不压缩的在本测试中的吞吐也能达到9.3w/s。
测试结果5
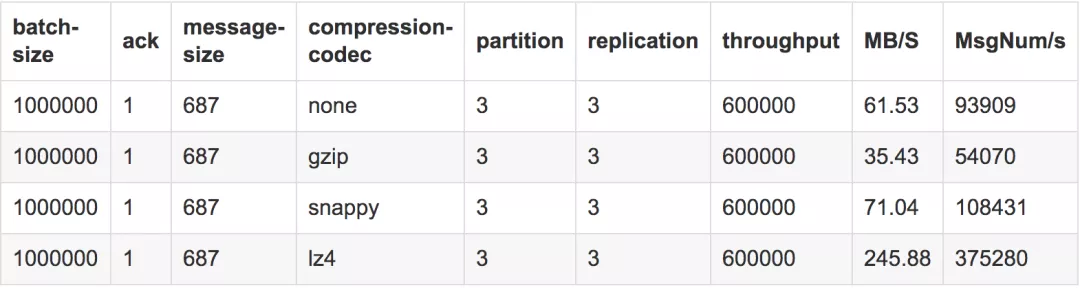
测试结论
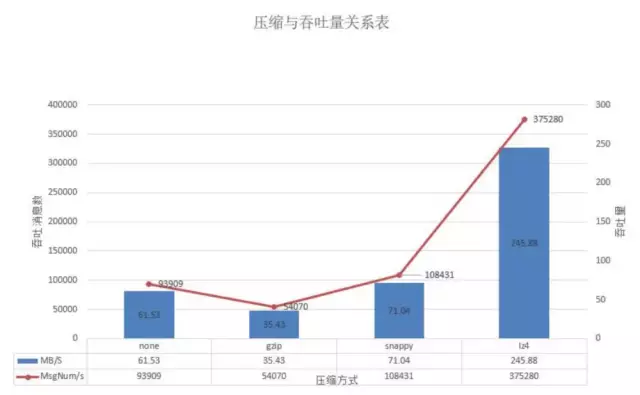
在batch-size为100w且并发量在60w时,lz4的吞吐达到37.5w/s,snappy此时下降到10.8w/s,而gzip由于压缩的费时其吞吐最差基本在5.4w/s,不压缩的在本测试中的吞吐为9.4w/s。
测试结果6
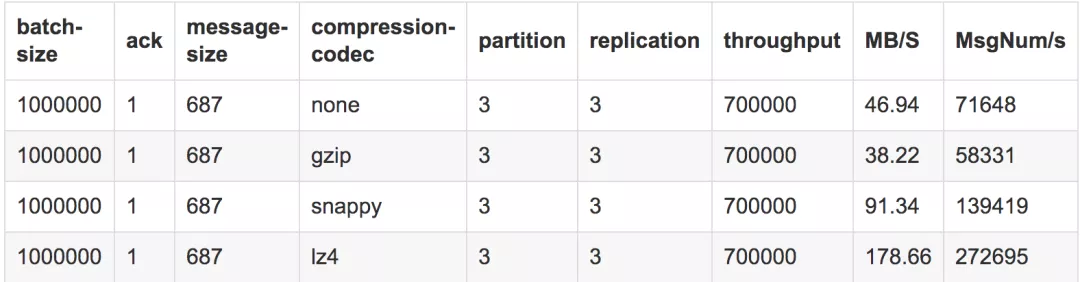
测试结论
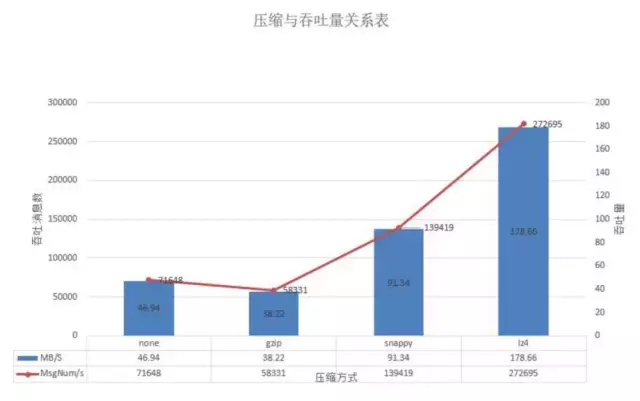
在batch-size为100w且并发量在70w时,lz4的吞吐量下降到达到27.2w/s,snappy次之为13.9w/s,而gzip则继续保持在5.8w/s,不压缩则下降到7.1w/s。
测试结果7
测试单副本单分区下的各压缩的吞吐量:
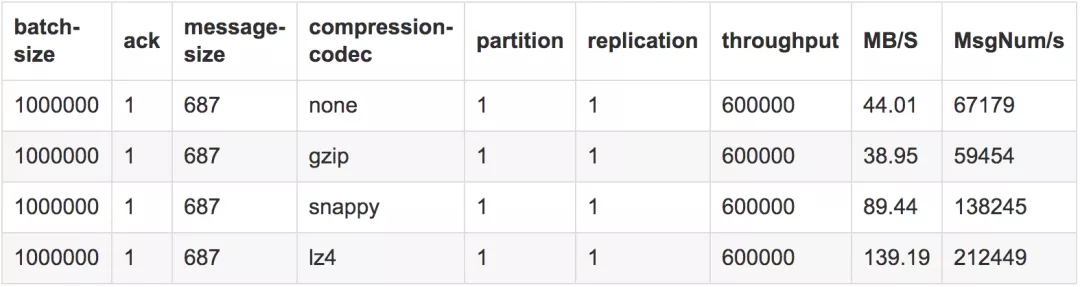
测试结论

我们这次使用1个分区1个副本的主题,测试中通过我们使用不同的压缩格式,在其他参数一致的情况下,在并发和batch-size增大到60w和100w的情况下,lz4达到最好的吞吐21.2w/s,而普通不压缩的方式则维持在6.7w/s。
-
测试结论
本次测试对数据的存储块大小未测,但在之前的测试中发现压缩以及解压的情况也是lz4算法最优,==lz4压缩最大时可以达到30w+/s的吞吐,而不压缩为12w/s,snappy最大为16w/s,gzip最大为5.8w/s==;故后续生产消息时建议采用lz4压缩,不仅可以节省磁盘,也可以大幅度增加我们的吞吐。
4.1.5 partition
测试结果
分区数越多,单线程消费者吞吐率越小。

测试结论
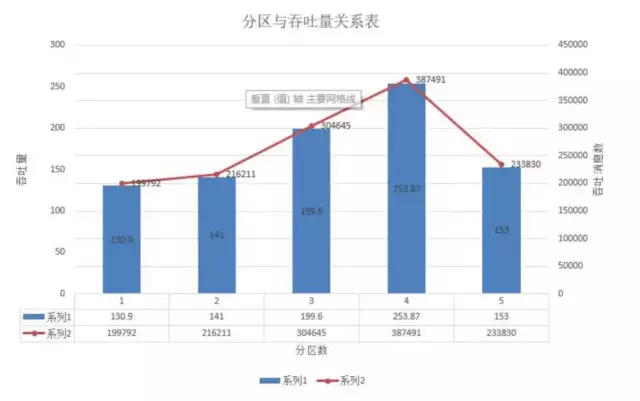
在我们的broker线程小于partiton数时,随着线程增多,吞吐上升,而在两者对等时,达到最优,后续基本稳定,但是由于网络和磁盘的问题可能会有一些起伏。
4.1.6 replication
测试结果
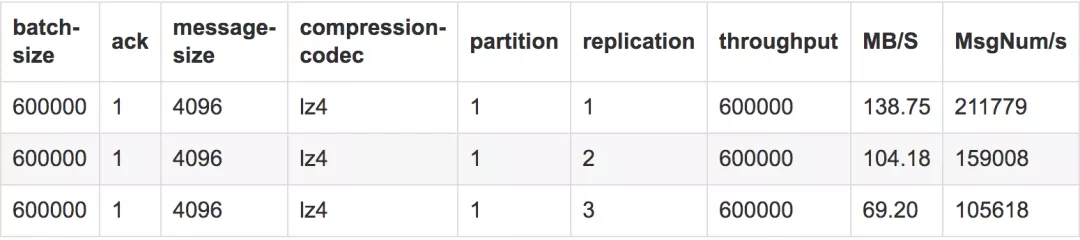
测试结论
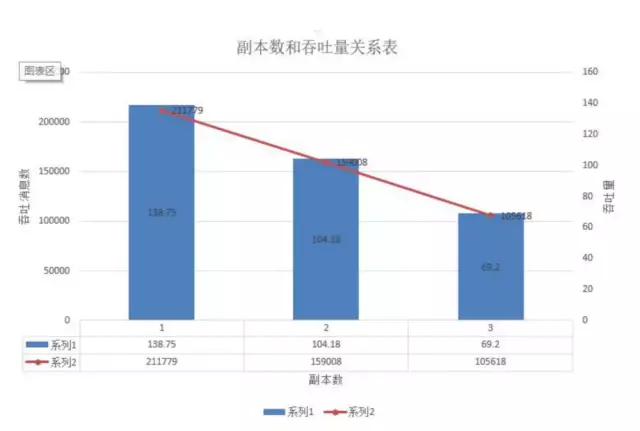
Replication是我们对不同partition所做的副本,它的大小会在ISR中显示,为了保证数据的安全性,ISR中掉出的版本应该保持在1,所以此处我们从replica为2开始测试。在ack不同时,其数量的多少会对性能造成线性的影响,数量过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~4为宜,我们设置为3个,既能保障数据的高可用,又避免了浪费过多的存储资源。
4,1.7 throughout IO
测试结果

测试结论
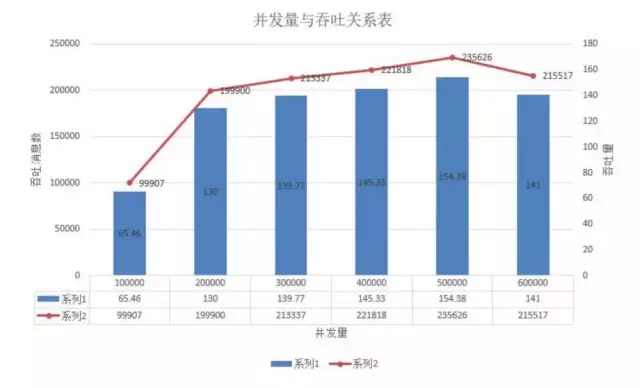
在主题是一个分区和一个副本时,我们看到在并发50w以下时,随着并发数增大,吞吐上升,但是在50w以后时,可以看出并发增大反而吞吐降低了,这是因为IO的限制,在高并发的情况下,产生了阻塞而导致。
4.2 consumer测试
4.2.1 thread
测试结果

测试结论
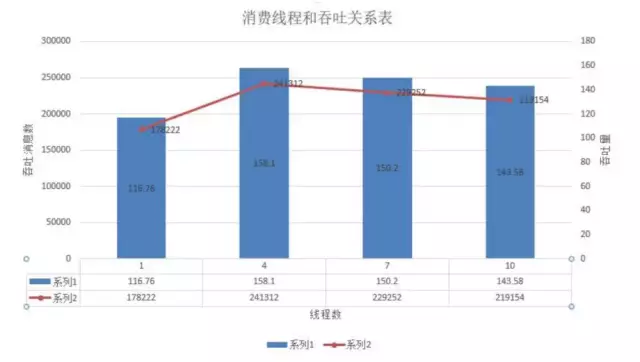
在threads为4时,消费速度最好达到24.1w/s,而后续慢慢平稳。
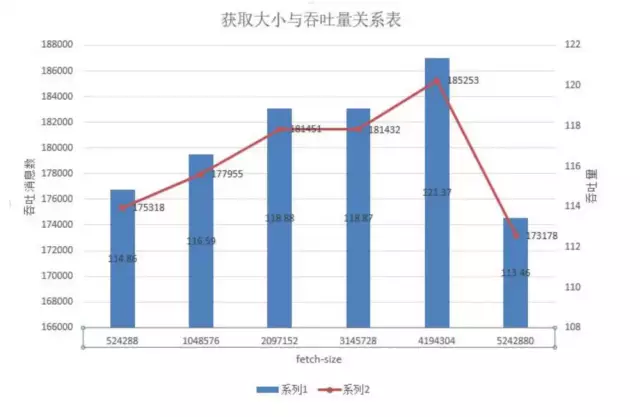
4.2.2 fetch-size
测试结果
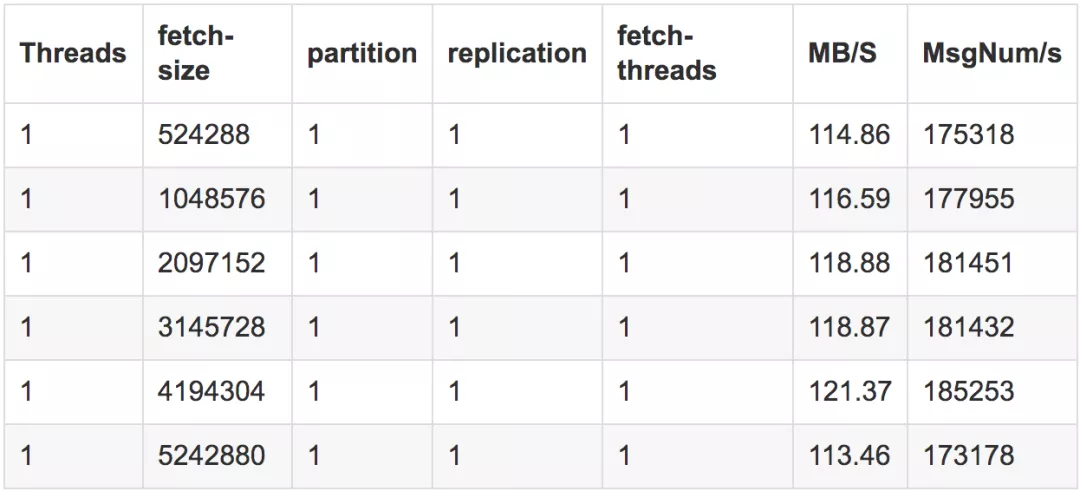
测试结论
4.2.3 partiton
测试结果
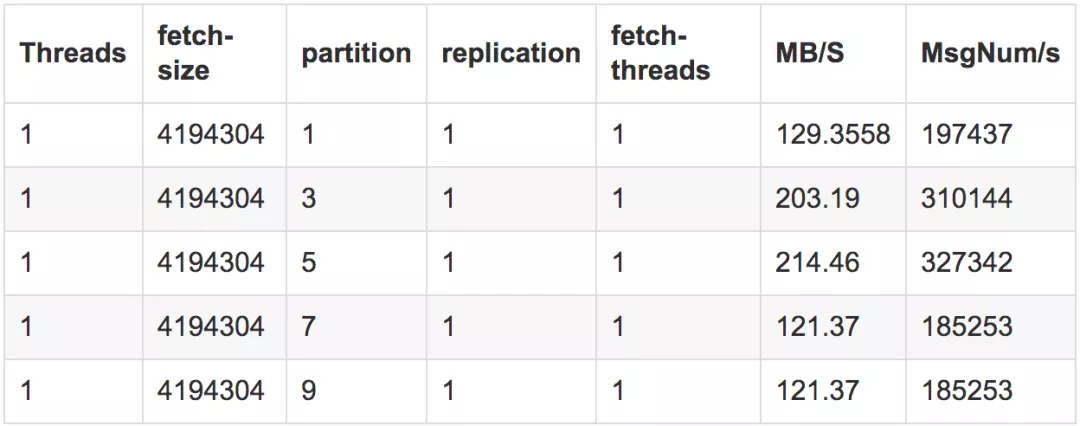
测试结论
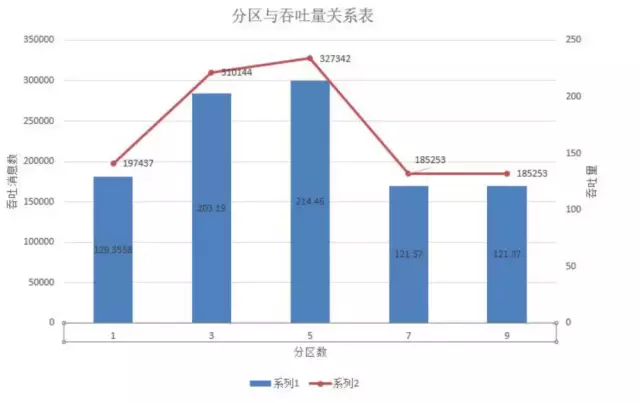
分区数在kafka中和处理的线程数有一定的关系,当thread小于partition数时,那么可能存在一个thread消费两个partition,而==两者一样或者说thread大于partition时,实际是一一对应关系==。
4.2.4 replication
测试结果

测试结论

数量过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~4为宜,我们设置为3个,既能保障数据的高可用,又避免了浪费过多的存储资源。
4.2.5 fetch-thread
测试结论

在我们控制其他条件不变的情况下,我们更改fetch-thread的线程数,可以发现是随着线程数增多而消费速度加快,在fetch-threads=10时,最优为146.4m/s。
转载节选自 https://mp.weixin.qq.com/s?__biz=MzI0NTIxNzE1Ng==&mid=2651217964&idx=2&sn=6517a7732ff69f82445c75c4b91a6c6c&chksm=f2a322c7c5d4abd14a6108a2ca6e4913cc5c70a75d803a17d3d3142e9844dde6a514c4ca9f24&mpshare=1&scene=1&srcid=&sharer_sharetime=1569202183520&sharer_shareid=904fe9378619edc63a81ef90022195da&key=7fbd4d18e8fd1c6f03866d845e076c0a849b0b0b04126973151263ddd43588bfa5f951e340a70f9bc15af82bf935e39017d3d1a96999fbcedbc33399c36919e57a4e82f92c43bf150dda1c56178cd207&ascene=1&uin=MTA2MTYyNTc4Mw%3D%3D&devicetype=Windows+7&version=62060834&lang=zh_CN&pass_ticket=ngfhIoUK7ktBYbHIqLZZONtzSK69VqypB3n%2B3xyiyRoRZ%2BLUIf%2B8ewFCZhezQRZL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号