机器学习十讲第一讲

大数据指数据采集,数据清洗,数据分析和数据应用的整个流程中理论,技术和方法,即上述公式的整个流程
机器学习是大数据分析的核心内容,解决的是找到关联X和Y的模型F,从Data到X的步骤通常是人工完成(特征工程)
深度学习是机器学习的一部分,核心是自动找到对特定任务有效的特征,即自动完成Data到X的转换。
若Y是模拟人类的行为,则称为人工智能。
机器学习方法的分类

有监督学习

无监督学习

强化学习

基本概念

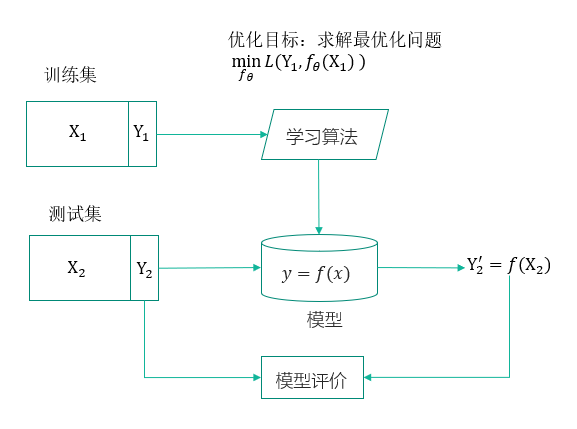
机器学习的一般流程
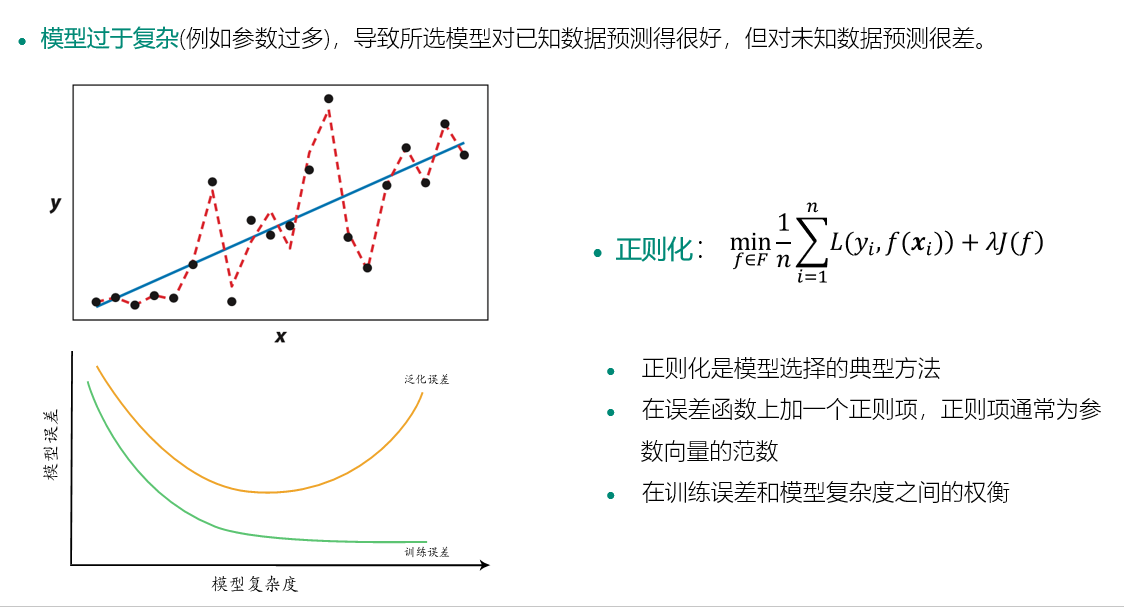
过度拟合问题
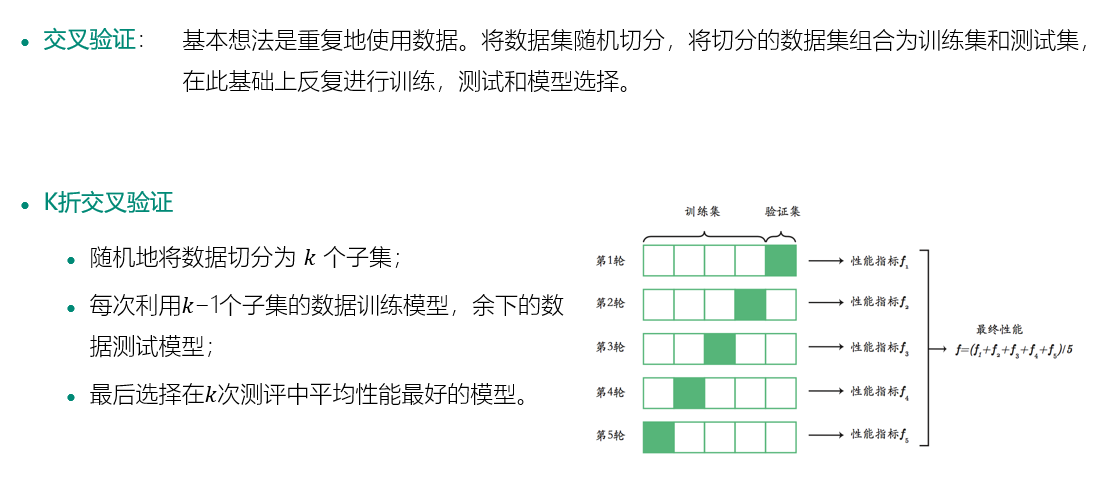
模型选择
机器学习的数学结构
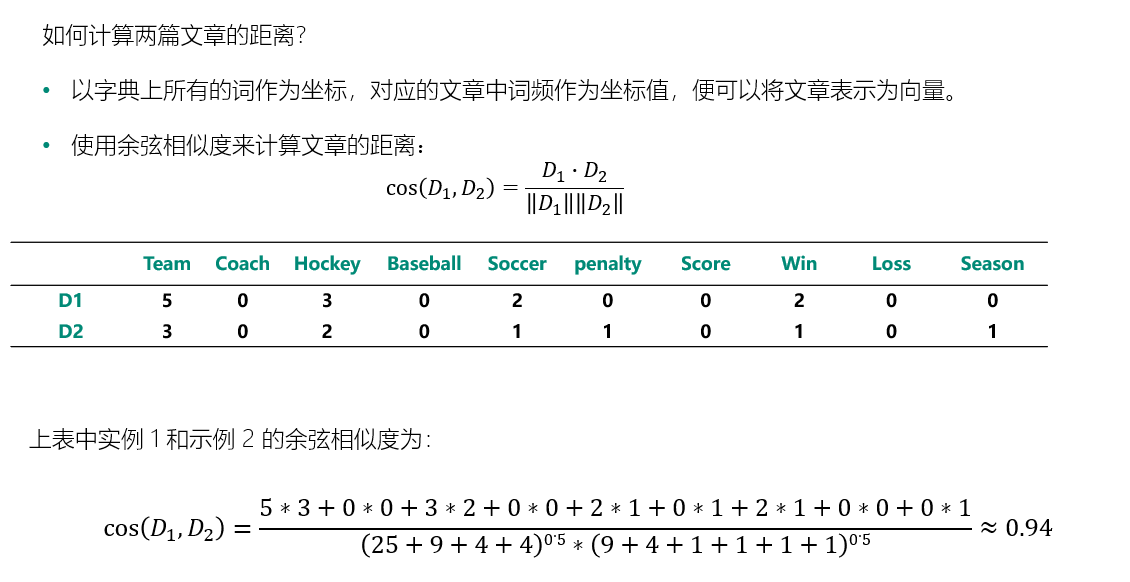
度量结构:表示数据之间的距离
以文本处理为例:
其他常用距离:曼哈顿距离、欧式距离、极大距离
K近邻

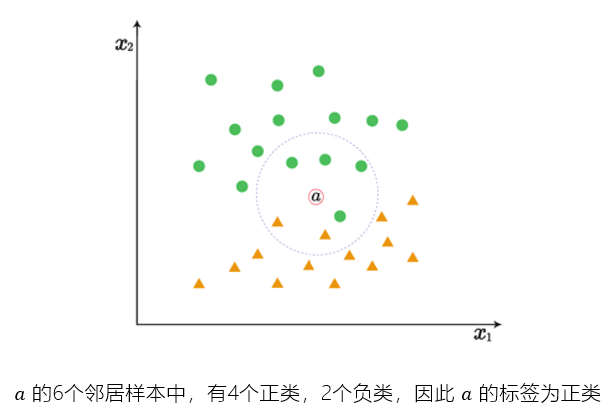
K近邻:K的选择

K近邻:提高计算速度
- K近邻算法最常用的数据结构为k-d树,它是二叉搜索树在多维空间上的扩展
- 当落在某一个节点的超立方体中的样本数少于给定阈值时,节点便不再进一步分裂
- 在K近邻算法中,k-d树的作用是对训练数据集构建索引,从而在预测时,能够快速找到与测试样本近似的样本
网络结构
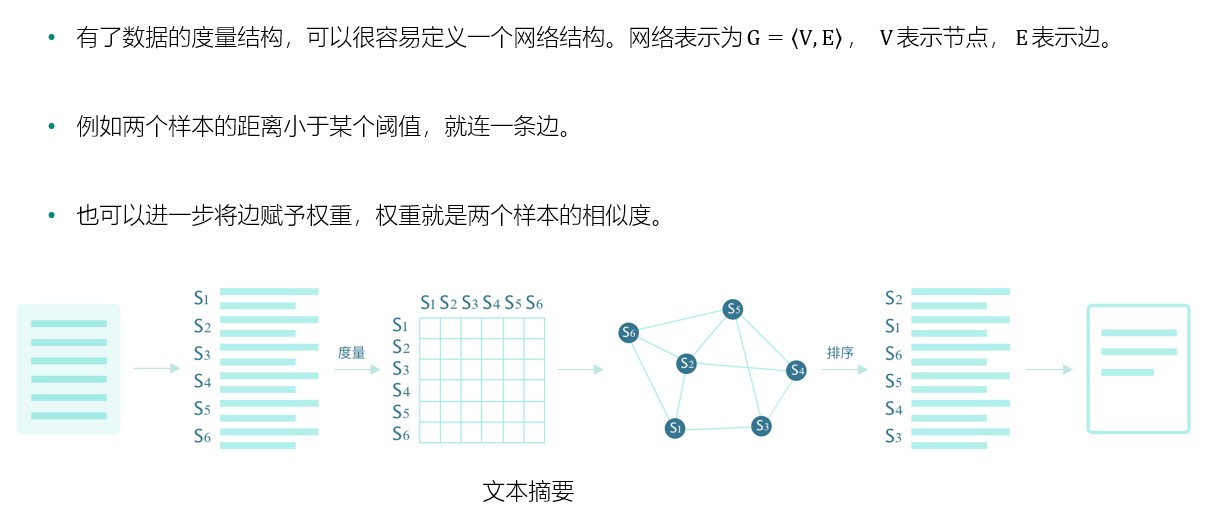
PageRank算法

其他数学结构

Scikit-learn

安装:

pip install scikit-learn
Scikit-learn的基本建模流程
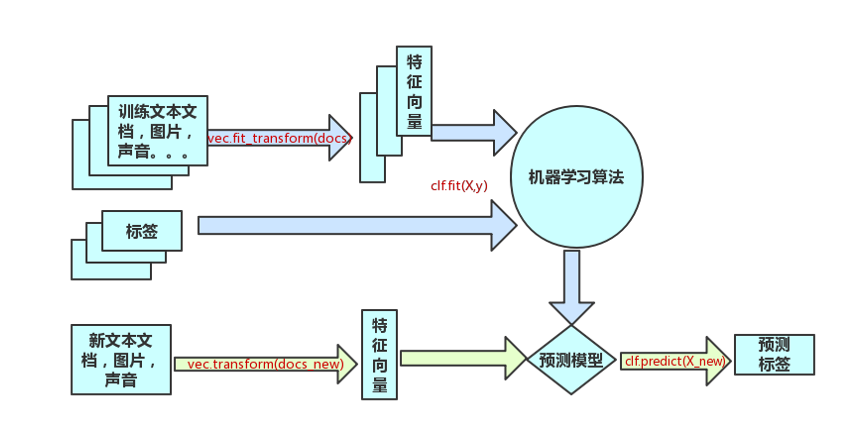
Scikit-learn常用函数
- transform 函数:数据转换
from sklearn import preprocessing scaler = preprocessing.StandardScaler().fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
- fit 函数:模型训练
from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X_train, y_train)
- predict 函数:模型预测
y_pred = lr.predict(X_test)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号