MongoDB DBA 实践4-----创建复制集
一、复制
复制允许多个数据库服务器共享相同数据的功能,从而确保冗余并促进负载平衡
1、数据冗余及可用性
复制技术提供数据冗余及可用性,在不同的数据库服务器上使用多个数据副本,复制技术防止单个数据库服务器出现数据故障而出现数据丢失。通过设置从库,你能在上面进行灾难切换、数据备份、报表服务等。在某些应用场景下,你还能提高读的能力,客户端通过将读和写请求分发到不同的服务器上面。
2、MongoDB复制技术
副本集:一组MongoDB服务器,用于实现复制和自动故障转移。MongoDB推荐的复制策略。
复制集(replica Set)或者副本集,由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据通过上述方式来保持复制集内所有成员存储相同的数据集,提供数据的高可用性。
3、 复制集(replica Set)主要作用:
- Failover (故障转移,故障切换,故障恢复)
- Redundancy(数据冗余)
- 避免单点,用于灾难时恢复,报表处理,提升数据可用性
- 读写分离,分担读压力
- 对用户透明的系统维护升级
二、复制集
1、副本集中成员
主要包括三个:主节点、副节点、仲裁节点。
在一个副本集群中,对成员个数的最低要求是:一个主节点、一个从节点、一个仲裁节点。但是大多数实际应用中是一个主节点、两个从节点。在3.0版本中一个集群中最多可以达到50个成员,在3.2版本中可以有12个成员。
1)主节点
在一个副本集群中,只能存在一个主节点,接收所有写请求。MongoDB应用写操作到数据文件中并记录操作到日志文件oplog中。从节点成员复制这些oplog日志并应用操作到他们的数据集中。在集群中,所有成员都能接收读请求,但是默认上应用程序的读请求直接被发送到主节点上。当主节点不可用了,这就触发了竞选,会在剩下的从节点中选择一个新节点。在某些情景下,会有两个节点有那么一瞬间认为他们自己是主节点,但是他们最多只有一个能够完成写操作,它就是目前的主库,并且另外一个是前主节点还没有觉察它被降级了,典型的由于是网络分区。当这种情况出现时,连接到前主库的客户端也许会察觉到过期数据,最后进行回滚。
2)从节点
为了复制数据,从节点采用异步的方式,复制主库上的oplog并应用日志中操作到自己的数据集。一个主从集群环境中可以存在多个从库。
3)仲裁者
它没有数据集并且不能成为主库,它的存在可以允许主从复制集群中成员数为奇数,因为它总有一个投票权。
2、副本集部署架构
复制集群的架构能够影响集群的容量及性能。标准的生产环境部署架构是一个具有三个成员的复制集群,能够很好的提供容错和冗余能力。一般而言,我们要避免复杂,凡事根据实际的应用需求设计集群架构。
下面介绍几种常用的架构:
1)具有三成员复制集群
复制集群最低要求需要有三个成员,在三成员架构中,分为一主两从和一主一从一仲裁者。
- 一主两从模式:当主库不可用,两个从库通过竞选成为新主库
- 一主一从一仲裁模式:当主库不可用,这个唯一从库将会成为新主库
三、复制集集群的实现(一主两从)
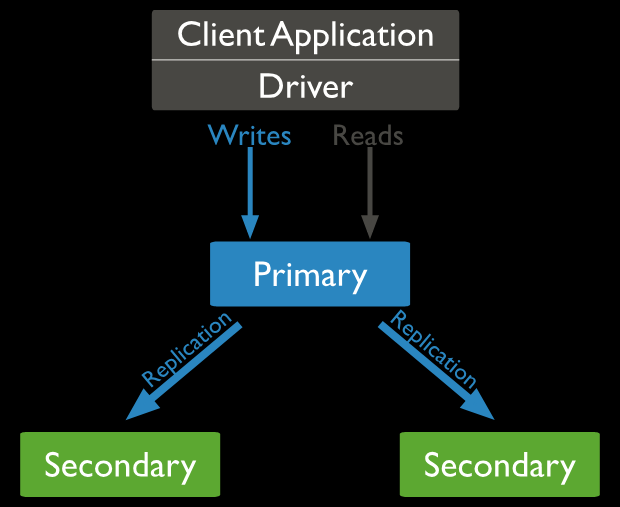
复制集结构图

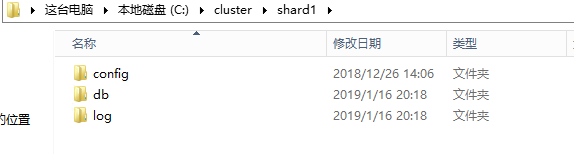
1.在目录下新建文件夹cluster,再分别新建文件夹shard1

2.shard1文件夹结构如下:其中config是配置文件、db是数据存放地址、log是日志文件
3.shard1目录下每个config文件夹中都有mongod.cfg文件分别如下:
1 # mongod.conf 2 3 # for documentation of all options, see: 4 # http://docs.mongodb.org/manual/reference/configuration-options/ 5 6 # Where and how to store data. 7 storage: 8 dbPath: C:\cluster\shard1\db 9 journal: 10 enabled: true 11 # engine: 12 # mmapv1: 13 # wiredTiger: 14 15 # where to write logging data. 16 systemLog: 17 destination: file 18 logAppend: true 19 path: C:\cluster\shard1\log\mongod.log 20 21 # network interfaces 22 net: 23 port: 27020 24 bindIp: 0.0.0.0 25 26 27 #processManagement: 28 29 #security: 30 31 #operationProfiling: 32 33 replication: 34 replSetName: shard1 35 36 #sharding: 3738 ## Enterprise-Only Options: 39 40 #auditLog: 41 42 #snmp:
4.在cluster目录里的bin目录下
新建如下几个bat文件(用于启动不同的MongoDB实例):
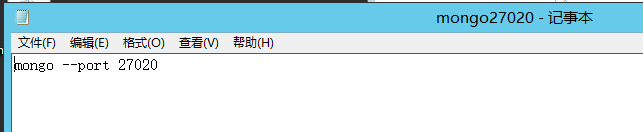
具体如下:

5.分别启动三个不同的MongoDB实例表示不同的节点
- 先运行

- 再运行

另外两个节点一样顺序启动。
6. 部署复制集集群
- 初始化主节点,直接使用rs.initiate(),但是显示成员时显示的是主机名
- 添加两个副节点
> rs.initiate() { "info2" : "no configuration specified. Using a default configuration for the set", "me" : "Server131:27020", "ok" : 1, "operationTime" : Timestamp(1547659827, 1), "$clusterTime" : { "clusterTime" : Timestamp(1547659827, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } } shard1:SECONDARY> rs.add("192.168.111.135:27020") { "ok" : 1, "operationTime" : Timestamp(1547659866, 1), "$clusterTime" : { "clusterTime" : Timestamp(1547659866, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } } shard1:PRIMARY> rs.add("192.168.111.138:27020") { "ok" : 1, "operationTime" : Timestamp(1547659878, 1), "$clusterTime" : { "clusterTime" : Timestamp(1547659878, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } } shard1:PRIMARY>
- 这时集群已经建立完毕,member下有3个成员,用rs.conf()
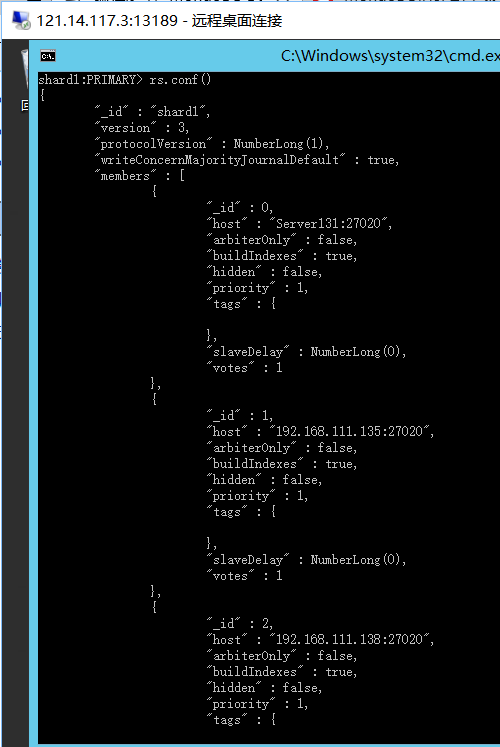
-
分别在另外两个节点输入rs.status(),可以看见对应节点状态与类型。
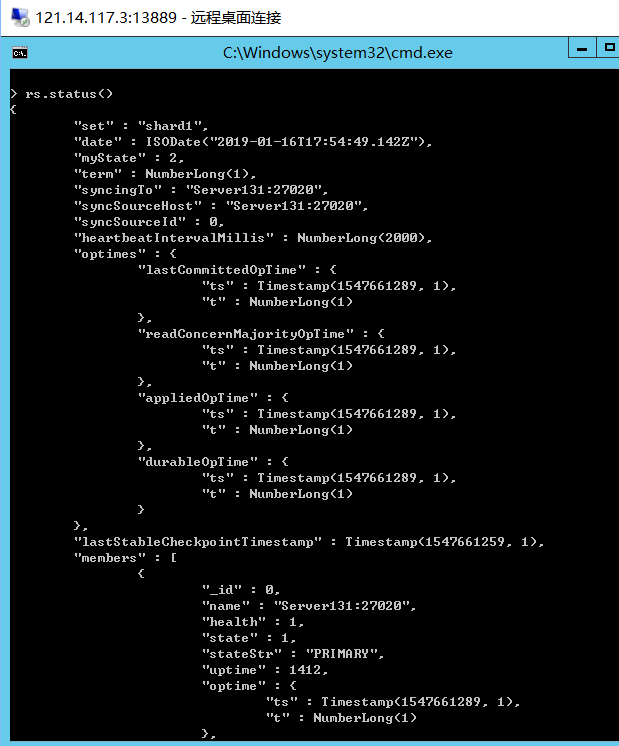
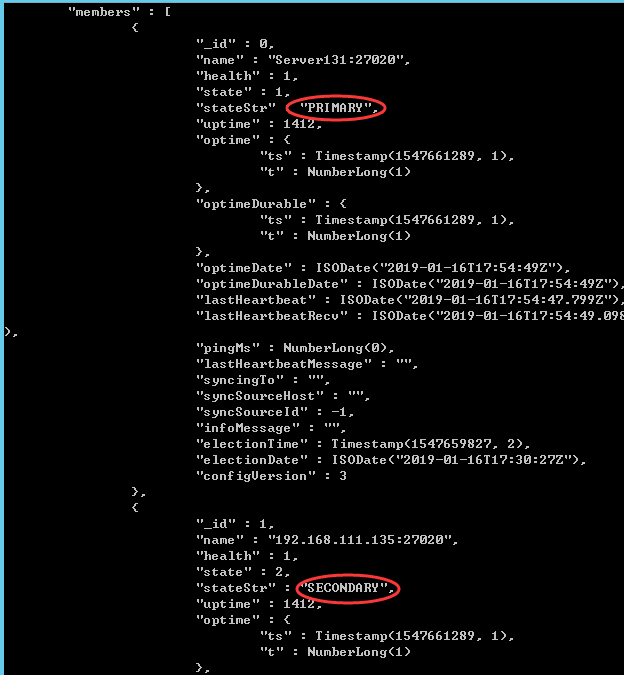

注意:SECONDARY是不允许读写的,要使用rs.slaveOk()获得读写权限,可以看出主节点的student数据库已经同步到副节点中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号