
中文命名实体识别
什么是命名实体识别(NER)
定义:
命名实体识别(NER):也称实体识别、实体分块和实体提取,是信息提取的一个子任务,
指在将文本汇总的命名实体定位,并分类为预先定义的类别,如: 人员、组织、位置、时间
表达式、数量、货币值、百分比等。
注意:
中文的NER与英文的不太一样,中文NER问题很大程度上取决于分词的结果,比如:实体边界和单词
的边界在中文NER中经常是一样。所以在中文NER问题中,有时通常对文本进行分词,然后再预测序
列中单词的类别。这样一来,在分词中造成的错误会影响到NER的结果。基于字向量的模型能够避免
上述问题,但因为单纯采用字向量,导致拆开了很多并不应该拆开的词语,从而丢失了他们本身内在
的信息。
目的:
识别文本中的命名实体并将其归纳到相应的实体类型中。
应用场景:
NER是NLP中一项非常基础的任务,可用于:信息提取、问答系统、句法分析、机器翻译等众多NLP任务
的基础工具。
从NLP流程看,NER可以看做此法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、
对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统
等诸多NLP任务的基础。
NER方法
模型层面:
1、基于规则的方法;
2、无监督学习方法;
3、有监督学习方法;
输入层面:
1、基于字的方法;
2、基于词的方法;
3、基于字和词的方法。
基于规则的方法:
依赖人工制定的规则,规则的设计一般基于句法、语法、词汇的模式,以及特定领域的知识。当词典的大小有限时,基于规则的方法可以达到很好的效果。这种方法通常具有高精确率和低召回率的特点。但是这种方法无法难以迁移到别的领域,对于新的领域需要重新制定规则。
无监督学习方法:
利用语义相似性进行聚类,从聚类得到的组当中抽取命名实体,通过统计数据推断实体类别。
基于特征的监督学习方法:
可以表示为多分类任务或者序列标注任务,从数据中学习。
https://img-blog.csdnimg.cn/4646b59d766e49efb434a76fc6309825.png
常见命名实体识别算法
BiLSTM-CRF模型
https://img-blog.csdnimg.cn/18de507342eb4879861b513350792532.png
论文名称:Neural Architectures for Named Entity Recognition
论文链接:https://arxiv.org/pdf/1603.01360.pdf
应用于NER中的BiLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明BiLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。
在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
什么是LSTM?
1、RNN
参考连接:https://zhuanlan.zhihu.com/p/32085405
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。
比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
普通RNN:
其主要形式如下图所示(图片均来自台大李宏毅教授的PPT):
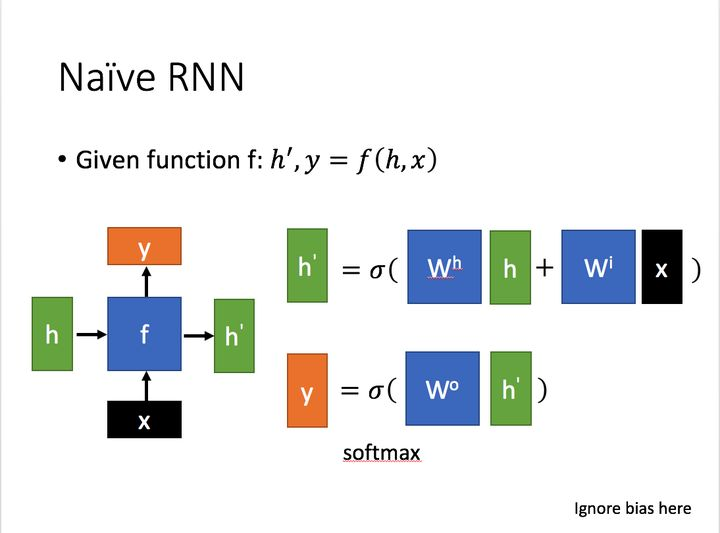
这里:
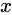 为当前状态下数据的输入,
为当前状态下数据的输入,
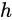 表示接收到的上一个节点的输入。
表示接收到的上一个节点的输入。
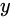 为当前节点状态下的输出,
为当前节点状态下的输出,
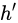 为传递到下一个节点的输出。
为传递到下一个节点的输出。
通过上图的公式可以看到,输出 h' 与 x 和 h 的值都相关。
而 y 则常常使用 h' 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。
对这里的 y 如何通过 h' 计算得到往往看具体模型的使用方式。
通过序列形式的输入,我们能够得到如下形式的RNN。
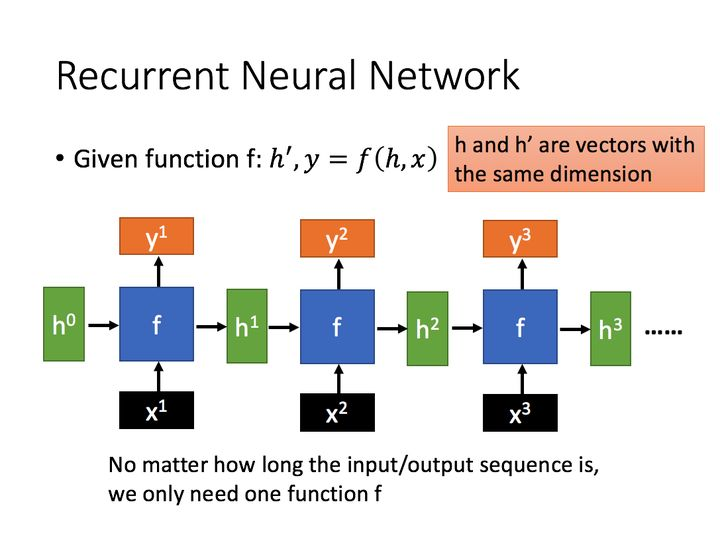
2、LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了 解决长序列训练过程中的 梯度消失 和 梯度爆炸 问题。
简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
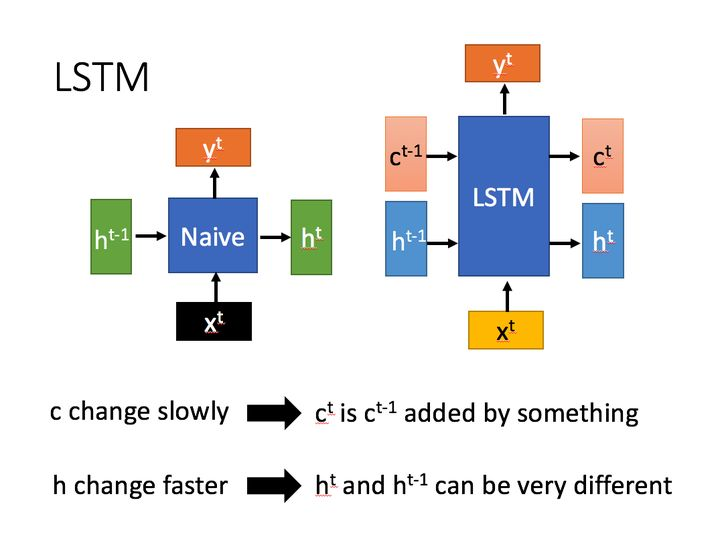
相比RNN只有一个传递状态 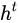 ,
,
LSTM有两个传输状态,一个 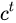 (cell state),
(cell state),
和一个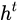 (hidden state)。
(hidden state)。
(Tips:RNN中的 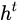 对于LSTM中的
对于LSTM中的 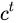 )
)
其中对于传递下去的 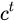 改变得很慢,
改变得很慢,
通常输出的 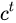 是上一个状态传过来的
是上一个状态传过来的 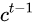 加上一些数值。
加上一些数值。
而 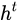 则在不同节点下往往会有很大的区别。
则在不同节点下往往会有很大的区别。
深入LSTM结构
下面具体对LSTM的内部结构来进行剖析。
首先使用LSTM的当前输入 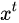 和上一个状态传递下来的
和上一个状态传递下来的 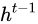 拼接训练得到四个状态。
拼接训练得到四个状态。

其中, 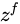 ,
, 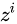 ,
,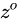 是由拼接向量乘以权重矩阵之后,再通过一个
是由拼接向量乘以权重矩阵之后,再通过一个 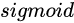 激活函数转换成0到1之间的数值,
激活函数转换成0到1之间的数值,
来作为一种门控状态。而 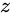 则是将结果通过一个
则是将结果通过一个 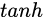 激活函数将转换成-1到1之间的值(这里使用
激活函数将转换成-1到1之间的值(这里使用 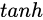 是因为这里是将其做为输入数据,而不是门控信号)。
是因为这里是将其做为输入数据,而不是门控信号)。
下面开始进一步介绍这四个状态在LSTM内部的使用
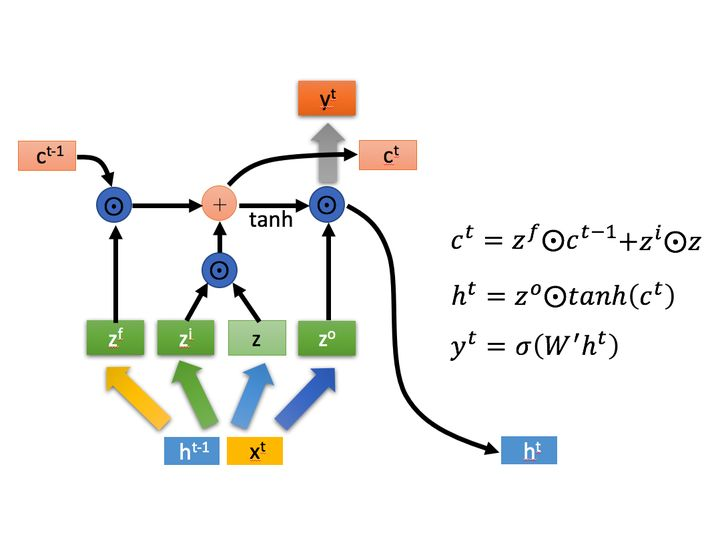
 是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。
是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。  则代表进行矩阵加法。
则代表进行矩阵加法。
LSTM内部主要有三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重 要的”。
具体来说是通过计算得到的 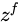 ( f 表示forget)来作为忘记门控,来控制上一个状态的
( f 表示forget)来作为忘记门控,来控制上一个状态的 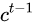 哪些需要留哪些需要忘。
哪些需要留哪些需要忘。
- 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入
![]() 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的
进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 ![]() 表示。而选择的门控信号则是由
表示。而选择的门控信号则是由 ![]() (i代表information)来进行控制。
(i代表information)来进行控制。
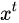 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的
进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 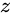 表示。而选择的门控信号则是由
表示。而选择的门控信号则是由 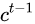 (i代表information)来进行控制。
(i代表information)来进行控制。将上面两步得到的结果相加,即可得到传输给下一个状态的
。也就是上图中的第一个公式。
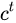 。也就是上图中的第一个公式。
。也就是上图中的第一个公式。- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过
![]() 来进行控制的。并且还对上一阶段得到的
来进行控制的。并且还对上一阶段得到的 ![]() 进行了放缩(通过一个tanh激活函数进行变化)。
进行了放缩(通过一个tanh激活函数进行变化)。
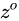 来进行控制的。并且还对上一阶段得到的
来进行控制的。并且还对上一阶段得到的 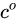 进行了放缩(通过一个tanh激活函数进行变化)。
进行了放缩(通过一个tanh激活函数进行变化)。与普通RNN类似,输出 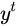 往往最终也是通过
往往最终也是通过 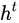 变化得到。
变化得到。
以上,就是LSTM的内部结构。通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
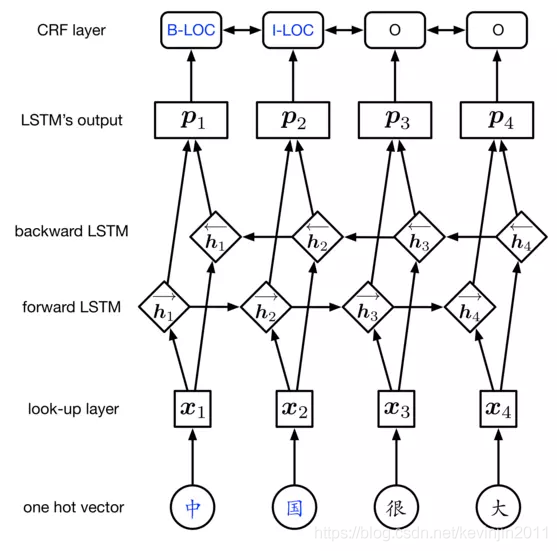
BiLSTM-CRF中,BiLSTM部分主要用于,根据一个单词的上下文,给出当前单词对应标签的概率分布,可以把BiLSTM看成一个编码层。
比如,对于标签集{N, V, O}和单词China,BiLSTM可能输出形如(0.88,-1.23,0.03)的非归一化概率分布。
这个分布我们看作是crf的特征分布输入,那么在CRF中我们需要学习的就是特征转移概率。
- CRF
主要讲一下代码中要用到的CRF的预测(维特比解码)
维特比算法流程:
1.求出位置1的各个标记的非规范化概率δ1(j)
δ1(j)=w∗F1(y0=START,yi=j,x),j=1,2,…,m
2.由递推公式(前后向概率计算)
δi(l)=max(1≤j≤m)δi−1(j)+w∗Fi(yi−1=j,yi=l,x),l=1,2,…,l
每一步都保留当前所有可能的状态l 对应的最大的非规范化概率,
并将最大非规范化概率状态对应的路径(当前状态得到最大概率时上一步的状态yi)记录
Ψi(l)=argmax(1≤j≤m){δi−1(j)+w∗Fi(yi−1=j,yi=l,x)}=argmaxδi(l),l=1,2,…,m
就是Pij的取值有m*m个,对每一个yj,都确定一个(而不是可能的m个)能最大化概率的yi状态
3.递推到i=n时终止
这时候求得非规范化概率的最大值为
maxyw∗F(y,x)=max(1≤j≤m)δn(j)=max(1≤j≤m)δn−1(j)+w∗Fn(yn−1=Ψn−1(k),yi=l,x),l=1,2,…,m
最优路径终点
y∗n=argmax(1≤j≤m)δn(j)
4.递归路径
由最优路径终点递归得到的最优路径(由当前最大概率状态状态对应的上一步状态,然后递归)
y∗i=Ψi+1(y∗i+1),i=n−1,n−2,…,1
求得最优路径:
- 损失函数
最后由CRF输出,损失函数的形式主要由CRF给出
在BiLSTM-CRF中,给定输入序列X,网络输出对应的标注序列y,得分为
S(X,y)=∑ni=0Ayi,yi+1+∑ni=1Pi,yi
(转移概率和状态概率之和)
利用softmax函数,我们为每一个正确的tag序列y定义一个概率值
p(y│X)=eS(X,y)∑y'∈YXeS(X,y')
在训练中,我们的目标就是最大化概率p(y│X) ,怎么最大化呢,用对数似然(因为p(y│X)中存在指数和除法,对数似然可以化简这些运算)
对数似然形式如下:
log(p(y│X)=loges(X,y)∑y∈YXes(X,y′)=S(X,y)−log(∑y′∈YXes(X,y′))
最大化这个对数似然,就是最小化他的相反数:
¥−log(p(y│X))=log(∑y′∈YXes(X,y′))−S(X,y)$
(loss function/object function)
最小化可以借助梯度下降实现
在对损失函数进行计算的时候,前一项S(X,y)很容易计算,
后一项log(∑y′∈YXes(X,y′))比较复杂,计算过程中由于指数较大常常会出现上溢或者下溢,
由公式 log∑e(xi)=a+log∑e(xi−a),可以借助a对指数进行放缩,通常a取xi的最大值(即a=max[Xi]),这可以保证指数最大不会超过0,于是你就不会上溢出。即便剩余的部分下溢出了,你也能得到一个合理的值。
又因为log(∑yelog(∑xex)+y),在log取e作为底数的情况下,可以化简为
log(∑yey∗elog(∑xex))=log(∑yey∗∑xex)=log(∑y∑xex+y)。
log_sum_exp因为需要计算所有路径,那么在计算过程中,计算每一步路径得分之和和直接计算全局得分是等价的,就可以大大减少计算时间。
当前的分数可以由上一步的总得分+转移得分+状态得分得到,这也是pytorch范例中
next_tag_var = forward_var + trans_score + emit_score
的由来注意,由于程序中比较好选一整行而不是一整列,所以调换i,j的含义,t[i][j]表示从j状态转移到i状态的转移概率
直接分析源码的前向传播部分,其中_get_lstm_features函数调用了pytorch的BiLSTM
总结概述:
假设数据集有两种实体类型:人物(PER)和地点(LOC),并采用BIO标注体系。
因此会有五种实体标签:B-PER、I-PER、B-LOC、I-LOC、O。
首先,BiLSTM-CRF的输入是词向量,输出是每个单词的预测的序列标注。
第一步:单词输入,单词进入look-up layer层,使用CBOW、Skip-gram或者glove模型映射为词向量。
第二步:词向量进入BiLSTM层,通过学习上下文的信息,输出每个单词对应于每个标签的得分概率。
例如,对于w0,BiLSTM节点的输出得分是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) 以及0.05 (O),这些score作为CRF layer的输入。
此处的标签的得分概率作为CRF模型中的未归一化的发射概率。
第三步:所有的BiLSTM的输出将作为CRF层的输入,通过学习标签之间的顺序依赖信息,得到最终的预测结果。
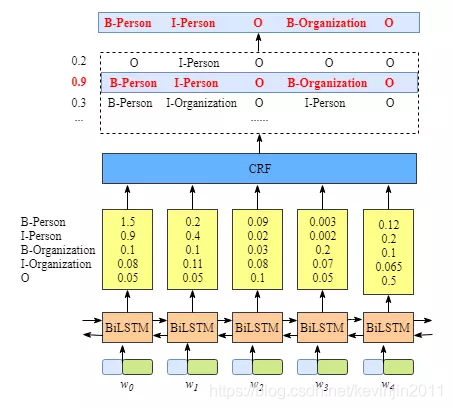
4.CRF层的作用:
在BiLSTM-CRF模型中,若直接通过取BiLSTM输出的标签概率最大值作为最终预测输出,可能会出现诸如I作为开头的词、存在两个连续的B的词、B-PER和I-LOC连在一起等情况,模型效果将会降低。
CRF层可以通过学习数据集中标签之间的转移概率从而修正BiLSTM层的输出,从而保证预测标签的合理性。
BiLSTM层学习的是序列的上下文信息,
CRF层学习的是标签之间的依赖信息。
Bert算法
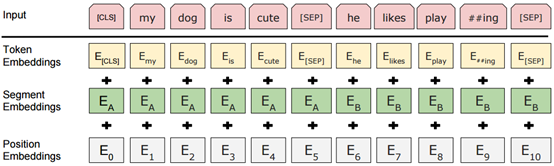
Bert(Bidirectional Encoder Representations from Transformers)算法,顾名思义,是基于Transformer算法的双向编码表征算法,Transformer算法基于多头注意力(Multi-Head attention)机制,而Bert又堆叠了多个Transfromer模型,并通过调节所有层中的双向Transformer来预先训练双向深度表示,而且,预训练的Bert模型可以通过一个额外的输出层来进行微调,适用性更广,而不需要做更多重复性的模型训练工作。
Bert算法的论文:https://arxiv.org/abs/1810.04805
Bert算法的开源代码:https://github.com/google-research/bert
bert 详解: https://blog.csdn.net/kevinjin2011/article/details/105037578?spm=1001.2014.3001.5502
参考博客:
https://blog.csdn.net/kevinjin2011/article/details/124691670
https://blog.csdn.net/u014033218/article/details/89304699
https://blog.csdn.net/kevinjin2011/article/details/124691670?spm=1001.2101.3001.6650.9&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~default-9-124691670-blog-89304699.pc_relevant_aa2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~default-9-124691670-blog-89304699.pc_relevant_aa2&utm_relevant_index=13
https://blog.csdn.net/kevinjin2011/article/details/104836867?spm=1001.2014.3001.5502
https://www.cnblogs.com/Nobody0426/p/10712835.html
https://zhuanlan.zhihu.com/p/32085405

 浙公网安备 33010602011771号
浙公网安备 33010602011771号