
决策树
决策树
概念
决策树(Decision Tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对数据进行分类的过程。它可以认为是if-then规则的集合。
优点:
1)可以自学习。在学习过程中不需要使用者了解过多的背景知识,只需要对训练数据进行较好的标注,就能进行学习。
2)决策树模型可读性好,具有描述性,有助于人工分析;
3)效率高,决策树只需要一次构建,就可以反复使用,每一次预测的最大计算次数不超过决策树的深度。
构建
步骤:
- 遍历所有特征划分方式,选择一个最有划分,那这个最优划分就是让划分之后的数据变得更“纯”;
- 基于选择出来的最优划分,将数据集分为多个字数据集;
- 对每个子数据集采用相同的操作,进行数据的划分,直到每个数据集中只有一个类别的样本数据
或者树的深度达到给定的限制条件的时候,结束构件过程- 对所有的数据集进行划分,直到达到限制条件。
目的(方向)
将数据划分为不同的数据子集,划分时候保证:
每次划分都是让数据集尽可能只有一个类别的数据,或者某个类别的数据出现的样本占绝大多数
纯度的度量:
a. 分类
信息熵
Gini系数
错误率
Note: 值越小越好
b. 回归
MAE
MSE
Note: 值越小越好
预测值如何产生?
分类:
a. 基于决策树中非叶子节点上的特征属性的判断条件,判断样本x属于哪个叶子节点(样本x落在哪个叶子节点上)
b. 以样本x所落的叶子节点上所有数据中出现次数最多的那个类别作为当前样本x的预测值
回归:
a. 基于决策树中非叶子节点上特征属性判断条件,判断样本x属于哪个叶子节点(样本x落在哪个叶子节点上)
b. 以样本x所落的叶子节点中所有数据的目标属性y值的均值作为样本x的预测值。
类别
决策树算法类别:
ID3
分类决策树,只能处理离散数据特征,构建的是多叉树, 特征属性仅仅可以使用一次
纯度度量: 使用信息增益g(D,A)进行特征选择

选择信息增益最大的特征作为当前分裂特征。
决策树构建案例:



由此可以根据天气特征,将整个数据集划分为三个子数据集,形成三个分支。
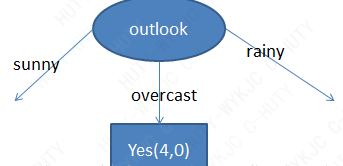
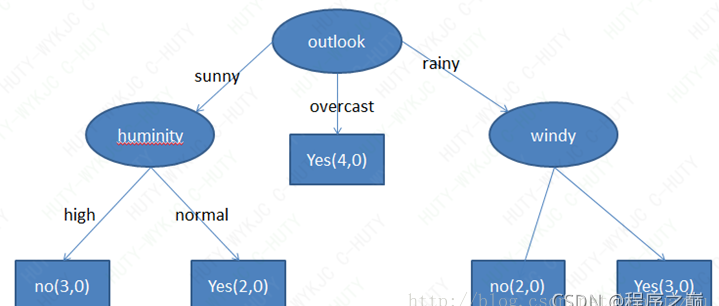
在对每个分支上的数据重复上面构建的步骤,直到将数据分得足够“纯”或者指定深度
可以得到一颗决策树, 如下图:
示例代码:
文件名:treePlotter.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle='sawtooth', fc='0.8') # 定义文本框和箭头的格式
leafNode = dict(boxstyle='round4', fc='0.8')
arrow_args = dict(arrowstyle='<-')
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
#计算父节点和子节点的中间位置,在父节点间填充文本的信息
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
# 画决策树的准备方法
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #计算树的宽度
depth = getTreeDepth(myTree) #计算树的深度
firstStr = list(myTree.keys())[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
# 画决策树主方法
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()
def retrieveTree(i):
listOfTrees =[{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
执行文件
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
"""
decision tree base of ID3
"""
from math import log
import operator
from test.machine_learning.algorithm import treePlotter
from typing import Dict
def createDateSet():
dataSet = [
[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']
]
labels = ['no surfacing', 'flippers']
# change to discrete values
return dataSet, labels
def calcShanonEnt(dataSet):
"""
计算信息熵
:param dataSet:
:return:
"""
numEntries = len(dataSet) # 样本数
labelCounts = {} # 创建一个字典: key为类别,value为个数
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shanonEnt = 0 # 初始化信息熵
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shanonEnt -= prob * log(prob, 2) # log base 2 计算信息熵
return shanonEnt
def splitDataSet(dataSet, axis, value):
"""
按照给定的特征划分数据
:param dataSet:
:param axis: dataSet 数据集下要进行特征划分的列号
:param value: axis下的某个特征值
:return:
"""
retDataSet = []
for featVec in dataSet: # 可以考虑使用pandas
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
"""
选取当前数据集下,用于划分数据集的最优特征
:param dataSet:
:return:
"""
numFeatures = len(dataSet[0]) - 1 # 获取当前数据集特征个数, 最后一列为分类标签
baseEntropy = calcShanonEnt(dataSet) # 计算当前数据的信息熵
bestInfoGain = 0.0 # 初始化最优信息增益
bestFeatrure = -1 # 初始化最优特征
for i in range(numFeatures):
featList = [example[i] for example in dataSet] # 获取数据集中当前特征下的所有值
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals: # 计算每种划分方式的信息熵
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShanonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 计算信息增益
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeatrure = i
return bestFeatrure
def majorityCnt(classList):
"""
返回类别字典中出现频率最高的类别
:param classList:
:return:
"""
classCount = {}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedclassCount = sorted(classCount.items(),
key=operator.itemgetter(1),
reverse=True)
return sortedclassCount[0][0]
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0] # 当前类别完成相同时,则停止继续划分,直接返回该类的标签
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) # 获取最好的分类特征索引
bestFeatLabel = labels[bestFeat]
# 使用字典来存储字典变量来存储树信息
myTree = {bestFeatLabel: {}} # 当前数据集选取最好的特征存储在bestFeat中
del(labels[bestFeat]) # 删除已经在选取的特征
featValues = [example[bestFeat] for example in dataSet]
uniqueValues = set(featValues)
for value in uniqueValues:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def classify(inputTree, featLabels, testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else:
classLabel = valueOfFeat
return classLabel
def storTree(inputTree, filename):
import pickle
fw = open(filename, 'w')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
#outlook','temperature','huminidy','windy
fr = \
['sunny hot high FALSE no',
'sunny hot high TRUE no',
'overcast hot high FALSE yes',
'rainy mild high FALSE yes',
'rainy cool normal FALSE yes',
'rainy cool normal TRUE no',
'overcast cool normal TRUE yes',
'sunny mild high FALSE no',
'sunny cool normal FALSE yes',
'rainy mild normal FALSE yes',
'sunny mild normal TRUE yes',
'overcast mild high TRUE yes',
'overcast hot normal FALSE yes',
'rainy mild high TRUE no']
if __name__ == '__main__':
lenses = [inst.strip().split(' ') for inst in fr]
lensesLabels = ['outlook', 'temperature', 'huminidy', 'windy']
lensesTree = createTree(lenses, lensesLabels)
treePlotter.createPlot(lensesTree)
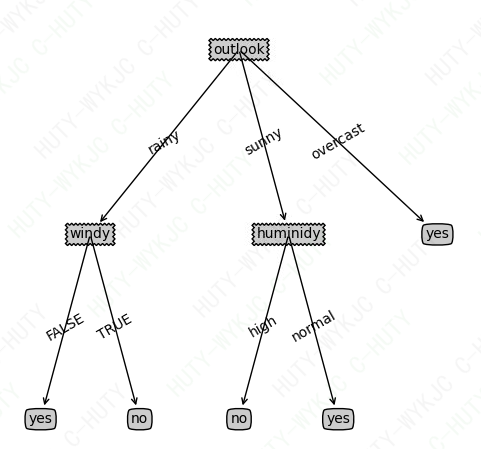
结果如下图:
C4.5
分类决策树,可以处理离散,连续的特征数据,构建的是多叉树, 特征属性仅仅可以使用一次
纯度度量:信息增益率 =g(D,A)/H(A)
eg:
由于前面ID3算法使用信息增益选择分裂属性的方式会倾向于选择具有大量值的特征,
如对于NO.,每条数据都对应一个play值,即按此特征划分,每个划分都是纯的(即完全的划分,只有属于一个类别),
NO的信息增益为最大值1.但这种按该特征的每个值进行分类的方式是没有任何意义的。
为了克服这一弊端,有人提出了采用信息增益率(GainRate)来选择分裂特征。计算方式如下:
gr(D,A)= g(D,A)/H(A), 其中g(D,A)就是ID3算法中的新增增益。

CART
分类回归决策树, 可以处理离散,连续的特征数据,构建的是二叉树,特征属性可以多次使用
纯度度量:基尼系数
决策树欠拟合和过拟合
欠拟合:
- 利用加深数的深度;
- 利用集成算法Adaboost或者GBDT
过拟合:
- 降低树的复杂度, 限制树的深度/规模(eg: 减枝)
- 利用集成学习中的随机深林算法来解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号