
1
Hadoop的起源
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
hadoop的历史版本
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
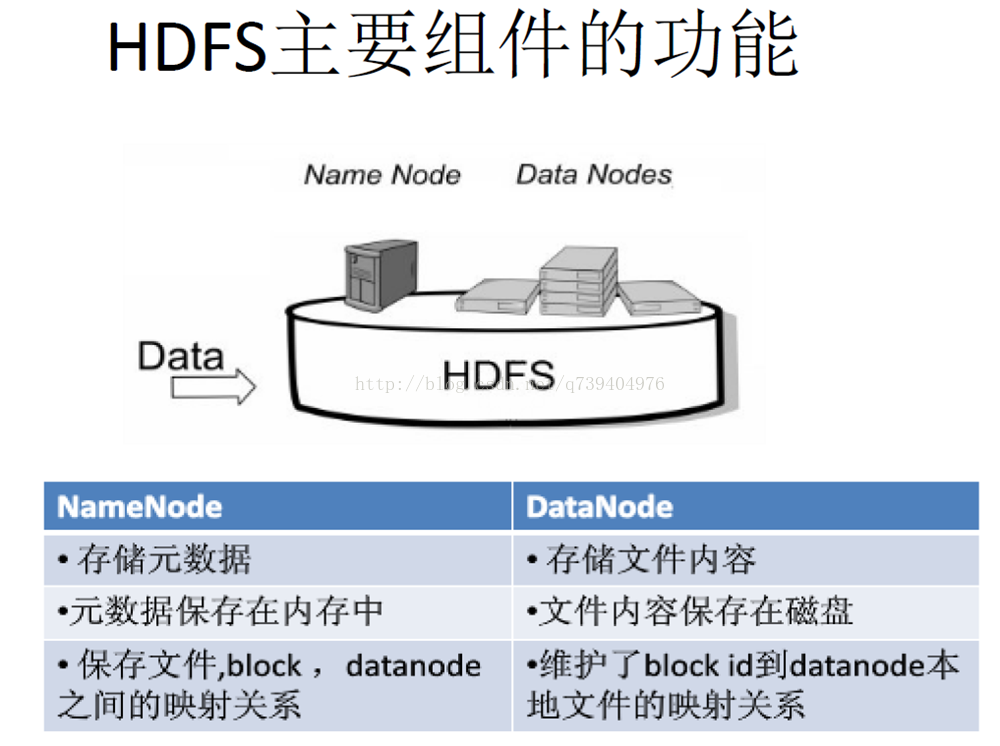
2在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditL
第二名称节点(SecondaryNameNode)
:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般是单独运行在一台机器上
SecondaryNameNode让EditLog变小的工作流程:
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号