

[编译原理]1.词法分析(lexical analysis)
一、词法分析器的作用
1.识别源文件中的 space 和注释并删除;
2.识别源文件中的 lexeme;
3.用 token 来代替源文件中的 lexeme,token 的形式为 <token-name, attribute-value>;
其中 attribute-value为可选项,例如对于常量60,token 即为 <60>,没有attribute-value,
而对于一个整型的变量,就需要有 attribute-value 来存储诸如变量类型、变量值等信息。
对于有 attribute-value 的 token,形式一般为 <token-name, ptr>,其中 ptr 为一个指针,指向存储 attribute-value 的区域。
4.生成一张 symbol table,用于存储某些 token 的 attribute-value,在 lexical analysis 以及之后的阶段都需要用到这张 symbol table。
下面这张图说明了 lexical analyzer, parser(syntax analyzer) 和 symbol table 是如何交互的。

二、如何解析 lexeme
lexeme analyzer 最主要的任务是识别 lexeme。
我们将 lexeme 分成两大类,第一类包括关键字、运算符等,内容都是固定死的;第二类是标识符(identifier),即变量名,只需遵循变量名的模式(pattern)即可,内容不固定,事先不知道。
下面我们介绍两种 lexeme analyzer 识别 identifier 和关键字的方法。
第一种方法:
事先将上述的第一类存入 symbol table,之后每识别出一个 lexeme 就先去查 symbol table,
若该 lexeme 已在 symbol table 中,直接返回该 lexeme,否则先将 lexeme 插入 symbol table 再返回。
第二种方法:
为每一个关键字设计一个 FA,通过 FA 来判断。
词素与正则表达式进行匹配时还要遵循最长前缀匹配原则。
前缀相同时要遵循优先匹配原则。
三、正则表达式 -> NFA -> DFA
DFA不同于NFA的地方:
1.不能以 epsilon 作为 label
2.对于每个状态 s 和每一个 symbol a,只有一条以 s 为出发点,以 a 为 label 的边。
NFA -> DFA


RE -> NFA
1) r = s | t
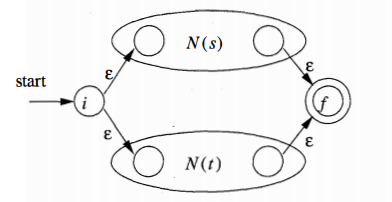
2) r = s t

3) r = s *


 浙公网安备 33010602011771号
浙公网安备 33010602011771号