
关于stl::sort--算法第二章作业
在这一年的打题过程中,从最开始的手敲冒泡排序到现在一直用STL里的sort,排序算法使用的频率可以说是非常高的了,而且各种排序算法的思想和有关的一些数据结构也会经常用到,但之前一直听说sort是基于快排的,就会有疑问——堆排序的最坏最好复杂度都是nlogn,而快排的最坏复杂度是n2,为什么不用堆排呢。国庆这几天断断续续地看完了老师给的博客之后终于明白了这个问题,而且更加深入地了解了sort函数对快排的极致优化。
从平均时间上来说,堆排的时间常数要比快排大,因为堆排会让某些数据出现很多大幅度的无效的移动,而快排则是将每个元素快速地移动到最终位置上或是附近,然后进行小范围的移动,详见
https://www.zhihu.com/question/20842649
http://mindhacks.cn/2008/06/13/why-is-quicksort-so-quick/
那么std::sort又是怎么实现来尽量避免快排的最坏情况呢,这篇博客给出了详细的解答
http://feihu.me/blog/2014/sgi-std-sort/
为了让自己看的时候不至于被各种函数名弄晕,做了个图辅助一下
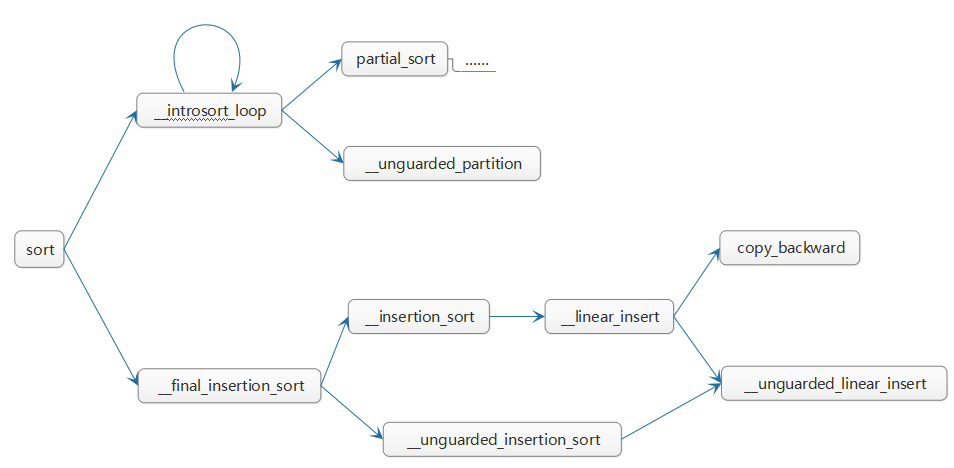
基于个人的理解
__introsort_loop
这个函数的主体部分就是快速排序的部分,但它与一般的快排不一样的是,为了尽量减少枢轴为极值引起的递归恶化,它选取了开头、中间、末尾三个数的中间值作为枢轴,而且这样做可以使__unguarded_partition中的分割操作不需要对first和last指针进行边界检查,只需要指针相交时即可退出,节省了很多次的比较操作,因为在选枢轴时就保证了一定会在超出有效区域之前中止指针的移动,左右区间至少有一个数字。在确定枢轴并划分区间后,就对右区间进行类似常规快排的递归操作,而左区间则是在处理完右区间后,将右边界收缩至枢轴处,再通过一次循环来处理左区间,当收缩到区间内数字个数小于最小分段阈值(小于时会调用插入排序,不调用递归,因为递归开销大)时就处理完毕了,返回上一级。这样就将一半的递归函数调用而转为循环调用,节省了大量开销。
如果快排出现可能恶化的情况,则可以通过递归深度阈值来控制这种趋势,在超过这个阈值的时候对子区间调用堆排序,避免过度递归恶化。
__final_insertion_sort这个函数就是改进版的插入排序操作了,首先在常规的插入排序当中,我们需要对边界做出检查以免出错,那么容易想到的就是,如果排序区间的最小值一定在左侧的话,那么就可以没有顾虑地进行操作,而在上面的函数中,我们只有在区间内数字个数小于最小分段阈值或者递归深度大于递归深度阈值时才会返回。先假设最小分段阈值为16,如果是由于区间内数字个数小于等于16导致最终返回,从快排的操作中我们可以知道最小值一定在左区间,也就是在最左侧的这个小于16的区间内;而如果是由于递归深度过大导致的返回,那么由于递归过深后调用的是堆排序,最左侧的数值也是最小值。所以无论是哪种情况,都可以保证最小值在最左侧的16个元素中。
所以只需对最左侧的16个元素(如果元素个数小于16个,则仅需)调用有边界检查的__insertion_sort函数,对其余元素调用没有边界检查的__unguarded_insertion_sort(__unguarded_linear_insert)就足够了,不会因为没有边界检查而产生问题,从而又减少了相当量的一部分比较操作。
而__insertion_sort函数的具体实现是从第二个元素开始,对每个元素都调用一次__linear_insert,__linear_insert中会将该元素与第一个元素比较,若比第一个元素小,就会调用一次copy_backward函数(copy_backward(拷贝内容起始位置,拷贝内容结束位置,目标数组起始位置),这个函数是从后向前开始拷贝的,所以以末尾为起始位置),将第i个元素前面的元素后移一位;如果不比第一个小,那么左边存在较小值,接下来就是熟悉的操作了——没有边界检查的__unguarded_linear_insert。
看完了这一番剖析后,真的不能不为这些STL设计者对于效率的追求而无所不用其极惊叹,每一行代码都是对极致效率的追求,都是算法的至高体现,算法的美,被展现得淋漓尽致。
(“我就是WA,WA10次,5小时打铁,也不干卡时间的事” “卧槽卧槽真过了,再跑多几十ms就TLE了”)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号