数据的归一化处理
数据的标准化(normalization)和归一化
数据的标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
目前数据标准化方法:直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
归一化
数据标准化中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。归一化是统一在0-1之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化的目标
1 把数变为(0,1)之间的小数
2 把有量纲表达式变为无量纲表达式
归一化的好处
1. 提升模型的收敛速度
2.提升模型的精度
常见的数据归一化方法
最常用的是 min-max标准化 和 z-score 标准化。
min-max标准化
是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
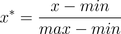
其中max为样本数据的最大值,min为样本数据的最小值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要将数据映射到[-1,1],则将公式换成:
x* = x* * 2 -1
或者进行一个近似
x* = (x - x_mean)/(x_max - x_min), x_mean表示数据的均值。
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
ps: 将数据归一化到[a,b]区间范围的方法:
(1)首先找到原本样本数据X的最小值Min及最大值Max
(2)计算系数:k=(b-a)/(Max-Min)
(3)得到归一化到[a,b]区间的数据:Y=a+k(X-Min) 或者 Y=b+k(X-Max)
即一个线性变换,在坐标上就是求直线方程,先求出系数,代入一个点对应的值(x的最大/最小就对应y的最大/最小)就ok了。
z-score 标准化(zero-mean normalization)
参考:
https://blog.csdn.net/Orange_Spotty_Cat/article/details/80312154
https://blog.csdn.net/pipisorry/article/details/52247379
log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:

使用注意:max为样本数据最大值,并且所有的数据都要大于等于1。
atan函数转换
通过反正切函数也可以实现数据的归一化:

使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上,而并非所有数据标准化的结果都映射到[0,1]区间上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号