清北学堂—2020.1提高储备营—Day 4 afternoon(动态规划初步(一))
qbxt Day 4 afternoon
——2020.1.20 济南 主讲:顾霆枫
目录一览
1.动态规划初步
2.记忆化搜索
3.递推式动态规划
4.记忆话搜索与递推式动态规划的转化
5.状态转移方程
总知识点:动态规划初步
一、动态规划初步:
1.定义:动态规划(Dynamic Programming)是是运筹学的一个分支,是求解决策过程最优化的数学方法。
动态规划被用于解决多阶段最优化决策问题。它的基本思路是将待解决的问题划分成多个阶段,每个阶段可能存在多种不同的状态。如果划分阶段后的问题满足最优子结构,则可以用动态规划算法一个阶段一个阶段,一个状态一个状态地解决问题的所有子问题,继而解决原问题。
2.概念化名词定义
先来一张图,配合食用
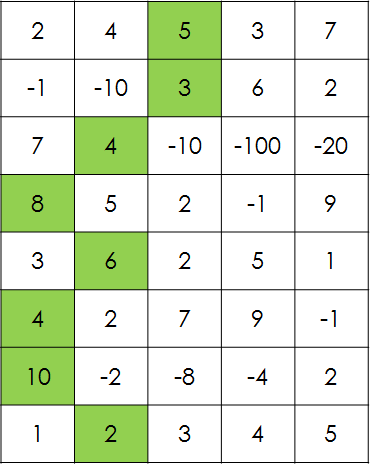
(1)阶段:
图中的每一行就是一个阶段。
阶段的划分是人为的。但是必须满足在一个阶段的任意状态做出任何决策后,得到的新状态都属于之后的阶段。(甚至不能在原阶段停留)
不过实际问题中,有的时候阶段并不是线性的,有的时候你很难描述阶段,但是实际上阶段只是提供了一个解决问题的顺序和设计状态的思路,设计出合理高效的状态才是解决问题的关键。
即:阶段的最大作用是辅助状态设计。
(2)状态:
图中“到达某一行某一个格子”
注意:一个格子不能算一个状态,一个状态应该描述一个事件,并且包含一切会对决策产生影响的限制条件。
比如,如果我要求走每一步时不能选择跟上一步一样的方向,那么我的状态就要额外记录我上一步走了哪个方向。变成“从前一个格子向某个方向走一步到达某一行某个格子”
描述一个状态描述一个状态用了几个“某”字,这个状态就是几维的。(原问题2维,增加限制后3维)(不过这其实不太重要)
(3)子问题:
右图中“从某一行某一个格子走到最后一行的最大得分”
如果我们把原问题看成“从第一行某一个格子走到最后一行的最大得分”
那么子问题与原问题非常相似,或者说根本就是同一个问题,相同的限制条件,相同的最终目的,只是改变了问题的规模,而解决问题需要的方法,也许可以完全仿照原问题。
(4)决策:
“向左下,正下或者右下走一步”
决策是一个集合。不同的状态可能有不同的决策集合。但是同一个状态一定有相同的决策集合。
如图,不论怎么到达的(4,1),其下一步一定只能向正下或右下;不论怎么到达的(5,2),其下一步一定只能向左下、正下或右下。
(5)转移:
“子问题(1,3)进行决策向正下方走一步吼能转化为子问题(2,3)”
转移用来描述两个子问题之间的关系,A子问题对应的状态进行决策C能到转化为B子问题,称为A→B有C转移。
(6)最优解:
不能被优化的解叫最优解,一个问题的最优解不一定唯一,但是最优解的目标值唯一。(废话)
(7)★★★★★ 最优子结构:
能动态规划解决的问题必须满足——任何一个子问题的最优解,做出第一步决策之后,剩下的决策集合仍然是转移到的子问题的最优解。这一条件叫做最优子结构。
这个条件也有等价描述如——
每个子问题的解与转移到它所经历的决策互不影响。(无后效性)
二、记忆化搜索(避免重复求解)
这个知识点我们已经在Day 1 morning大略的说过了,本篇主要说思想性的部分。
Day 1 传送门
1.思想:
开一个数组记录每一个子问题的最优解,如果在对子问题求解的过程中,发现之前已经求过了该问题的最优解,则直接返回之前求过的答案!
这样分析复杂度,每个子问题只会被求解一遍,而每个子问题求解时只会进行三次(O(1))操作,总复杂度为O(nm)
2.一般步骤
(1)提炼数学模型
(2)设计状态,定义子问题
(3)写记忆化搜索
3.例题
(1)滑雪问题
题目描述:
众所周知,滑雪只能从海拔高处滑向海拔低处。告诉你一个平面区域的海拔,滑雪时每次可以向东南西北四个方向中海拔小于当前格子的格子滑一步,求最长的滑雪路线。
分析:子问题:从(x,y)出发的最长滑雪路线
那么状态显然就是滑到了(x,y),决策也有{停止,(向上),(向下),(向左),(向右)}
而优化也是显然的,如果A格子比相邻的B格子海拔高,那么B格子的最长滑雪路线增加A格子可以用来优化A的滑雪路线。
如何确定顺序?
其实只要从左到右从上到下枚举就好了,因为每个子问题只会求解一次,当枚举到已求解过的格子时自然会直接跳过。
(伪)代码:
int Solve(子问题)
{
if (子问题已求解) return 记录的结果;
枚举每一个可以转移来的子问题 Solve(这些子问题),更新当前答案;
记录答案;
return 答案;
}
//主程序中
枚举每一个子问题 Solve(该子问题);
4.优缺点分析
优点:
- 普适性极强,所有满足最优子结构的问题都可以用记忆化搜索解决,不必要按阶段顺序求解,甚至不必要划分阶段
- 有的题目中一些小规模的子问题不会对最终答案有贡献,记忆化搜索不会对这些问题求解
- 思路直接,是正常的分析问题解决问题思路,不需要太多推导
缺点:
- 在函数调用时需要消耗一定时间,而且递归层数过多可能造成栈空间超限
- 代码实现上稍微复杂一些(代码量大些)
- 程序结构复杂,不利于优化
三、递推式动态规划
一道例题配合食用:
题目描述:
给一个N行M列的表格,每个格子里有一个整数。你从第一行选一个格子进入,之后每一步只能向左下,正下或右下走,不能走到表格之外。走到最后一行时结束,你的得分为你走过的每一个格子上数字之和,要求最大化你的得分。
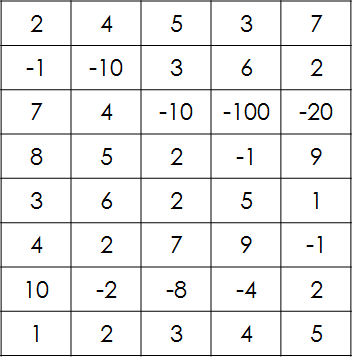
记忆化搜索代码:
int Solve (int x,int y) //解决子问题:到达(x,y)的最大得分
{
if (ans[x][y]!=-INF) return ans[x][y];
if (x==1) return ans[x][y]=a[x][y]; //最小规模子问题
int res=-INF; //将最大目标值预制为最小(负无穷)
if (y>1) res=max(res,Solve(x-1,y-1)+a[x][y]);
if (y<m) res=max(res,Solve(x-1,y+1)+a[x][y]);
res=max(res,Solve(x-1,y)+a[x][y]);
return ans[x][y]=res;
}
重点:
if (y>1) res=max(res,Solve(x+1,y-1)+a[x][y]);
if (y<m) res=max(res,Solve(x+1,y+1)+a[x][y]);
res=max(res,Solve(x+1,y)+a[x][y]);
思考一下,如果在调用这一次函数之前,你能确保Solve(x+1,y+1),Solve(x+1,y+1),Solve(x+1,y)已被求解过,那么这些Solve(x+1,?)的调用就完全没有意义,还不如直接用ans[x][?]。实际上我们可以依此写出一个公式
ans[i][j]=a[i][j]+max{ans[i+1][j-1],ans[i+1][j],ans[i+1][j+1]};
f[i][j]=a[i][j]+max{f[i+1][j-1],f[i+1][j],f[i+1][j+1]};
(伪)代码2.0:
将f[1~n][0~m+1]赋值为-INF
for (int j=1;j<=m;j++) f[n][j]=a[n][j]; //求解极小子问题
for (int i=n-1;i>=1;i--)
for (int j=1;j<=m;j++)
f[i][j]=a[i][j]+max(f[i+1][j-1],f[i+1][j],f[i+1][j+1]);
for (int j=1;j<=m;j++) ans=max(ans,f[1][j]);
四、记忆化搜索与递推式动规的转化
1.例题:
乘积最大
题目描述:
设有一个长度为N的数字串,要求选手使用K个乘号将它分成K+1个部分,找出一种分法,使得这K+1个部分的乘积能够为最大。
比如有一个数字串:312, 当N=3,K=1时会有以下两种分法:
- 3×12=36
- 31×2=62
这时,符合题目要求的结果是: 31×2=62
现在,请你设计一个程序,求得正确的答案。
我们用两种方式来求解
Part 1:
记忆化搜索
Solve(n,k)表示序列的前n位加k个乘号的最大乘积
记序列L~R位的数字组成的整数为NUM(L,R)
显然Solve(n,k)=max{Solve(i,k-1)*NUM(i+1,n)}
即记忆化搜索的时候枚举最后一个乘号的位置,转化成这个乘号之前的序列添加k-1个乘号的最大乘积的子问题。
Part 2:
递推式动归
Solve(n,k)=max{Solve(i,k-1)*NUM(i+1,n)}
你直接把Solve(n,k)用f[n][k]替代掉就好了
𝑓[𝑛][𝑘]=max{𝑓[𝑖][𝑘−1]×𝑁𝑈𝑀(𝑖+1,𝑛)} , 𝑖<𝑛
边界情况自己考虑下吧
重点在于递推求值的顺序——
我们发现转移过程中n,k都会减小,所以按照n,k从小到大的顺序求解就好了
for ( i ← 1~n ) for ( j ← 1~k )
for ( j ← 1~i ) k-1
2.递推式动归优缺点分析
优点:
- 代码简短,运行常数小
- 方便概括,程序结构清晰,易于发现优化
缺点:
- 需要一定的推导,有一定的思维难度
- 每一个状态都会被求解,无法排除无效状态
3.何时使用
(1)明确了是动态规划问题
(2)拓扑序不需要程序求出,可以在分析问题时直接得出
(3)按拓扑序DP时循环语句好控制
(4)记忆化搜索明确复杂度不合适
注:
(1)必满足
(2)(3)不满足且(4)不满足时考虑重新设计状态或者直接记忆化搜索
(2)(3)不满足,且(4)满足时考虑重新设计状态甚至换用DP以外的算法或结合数据结构解决
五、状态转移方程
1.概念解释
求解某个子问题的概括性等式称为状态转移方程
状态转移方程的通式:
𝑓[𝑈]=(max)/(min){𝑅(𝑓[𝜎^(−1) 𝑈],𝑔(𝜎,𝜎^(−1) 𝑈))}
注: 𝜎为𝑈状态"下的一个决策", 𝜎^(−1) 𝑈为一个前驱状态, 𝑔(𝜎,𝑈)为一个关于𝜎和𝑈的函数,𝑅表示一个运算式
2.推导方式
Step1. 写出转移式
对于状态/子问题𝑈,解的目标函数值为𝑓[𝑈],进行决策𝜎后的状态为𝜎𝑈,目标函数值为𝑅(𝑓[𝑈],𝑔(𝜎,𝑈))
写出转移式𝑅(𝑓[𝑈],𝑔(𝜎,𝑈))→𝑓[𝜎𝑈]
表示𝑅(𝑓[𝑈],𝑔(𝜎,𝑈))可以用来优化𝑓[𝜎𝑈](或者说子问题𝜎𝑈的求解可以转移到为对子问题𝑈求解,并通过𝑅和𝑔得到最优解的可能值)
Step2. 转移式归总,求出状态转移方程
对于状态𝑈,写出所有形如𝑅(𝑓[𝜎^(−1) 𝑈],𝑔(𝜎,𝜎^(−1) 𝑈))→𝑓[𝑈]的转移式
则状态转移方程为𝑓[𝑈]=(max)/(min){𝑅(𝑓[𝜎^(−1) 𝑈],𝑔(𝜎,𝜎^(−1) 𝑈))}, ∀𝜎
考场上推导在没有经过训练的时候并不简单,所以我们要学习一些DP的经典模型帮助我们快速找到状态设计思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号