es Elasticsearch 操作手册
原文链接:https://ropledata.blog.csdn.net/article/details/106834609
一、前言
本文版本说明:
- ElasticSearch版本:7.7 (目前最新版)
- Kibana版本:7.7(目前最新版)
前面两篇文章咱们已经对Elasticsearch进行了精细的讲解,第一篇围绕Elasticsearch最新版进行了上万字的详细解析,相信看过的朋友对Elasticsearch及kibana等工具的极速安装配置印象深刻,也至少会对Elasticsearch有一个入门的掌握。第二篇主要围绕Elasticsearch的分词器进行讲解,并重点分析了ik中文分词器。
前文链接:
本文咱们将对Elasticsearch原生的RESTful API操作进行详尽的归纳分析,并会对复杂的常用查询知识点进行一一举例展开,重点会对DSL查询,聚合查询,批量操作等进行举例解析,并会提供一些Elasticsearch的使用技巧。相信学会了这些知识和技巧之后,以后在工作中不管应对多么复杂的场景,都可以得心应手,迅速的根据RESTful API写出完美的代码。好了,废话不多说,让我们开始吧!
注意:下文咱们把ElasticSearch简称为ES,对大家可能出现的疑问进行标红并解释,并会对容易混淆的地方加以声明。

二、索引操作
2.1、创建索引
比如咱们创建一个3副本2分片的名为ropledata的索引:
PUT /ropledata
{
"settings": {
"number_of_shards": "2",
"number_of_replicas": "3"
}
}2.2、删除索引
和删除数据库一样,索引也是可以删除的,只需要执行如下命令就可以删除名为ropledata的索引:
DELETE /ropledata- 1
2.3、修改索引副本数
这里要注意,索引的分片是不允许修改的,咱们只能修改索引的副本数量,比如想把副本数量修改为2个,只需要执行:
PUT ropledata/_settings
{
"number_of_replicas" : "2"
}三、基础增删改查
3.1、插入数据
咱们平时进行基础的数据插入时,可以分为两种情况。一种是指定文档的id,一种是不指定。
注意:不指定的时候,ES会帮我们自动生成,不过不容易记忆,因此推荐指定id的方式插入数据。
疑问一:这里说的id是大括号里面的id吗?
不是的,这点容易混淆,这里包括后面查询或者删除时候用到的ID是创建文档时候指定或者ES自动生成的那个id,那个是唯一id,也就是下面示例里的101,而不是文档里面大括号的那个叫
id字段!文档里面的文档字段是可以没有id的。
-
不指定id
POST /ropledata/_doc/ { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"欢迎点赞,收藏,关注,一起学习" }
-
指定id
POST /ropledata/_doc/101 { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"欢迎点赞,收藏,关注,一起学习" }
3.2、删除数据
如果咱们想删除刚才创建的ropledata索引下的id为101的文档,可以使用如下命令:
DELETE /ropledata/_doc/1013.3、更新数据
这里大家要特别注意,ES里的文档是不可以修改的,但是可以覆盖,所以ES修改数据本质上是对文档的覆盖。
ES对数据的修改分为全局更新和局部更新,下面咱们进行对比说明:
-
全局更新
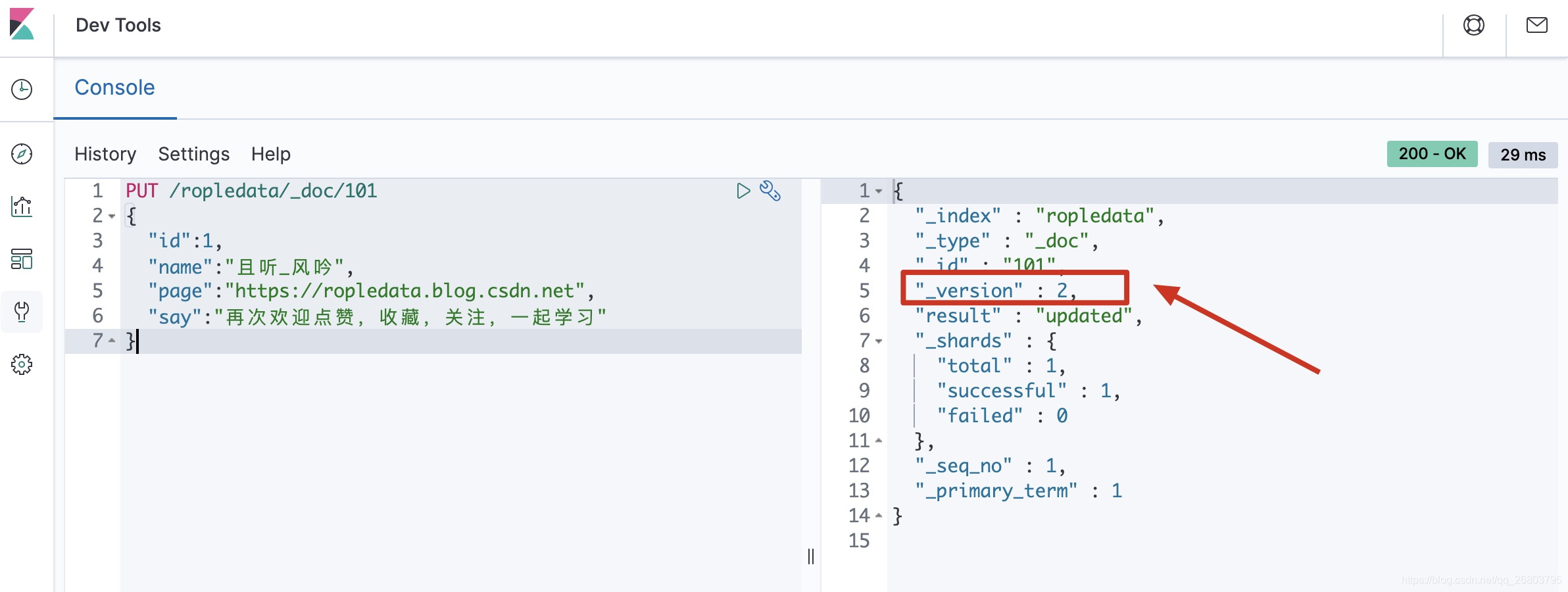
PUT /ropledata/_doc/101 { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"再次欢迎点赞,收藏,关注,一起学习" }然后大家可以多全局更新几次,会发现每次全局更新之后这个文档的
_version都会发生改变!
![在这里插入图片描述]()
-
局部更新
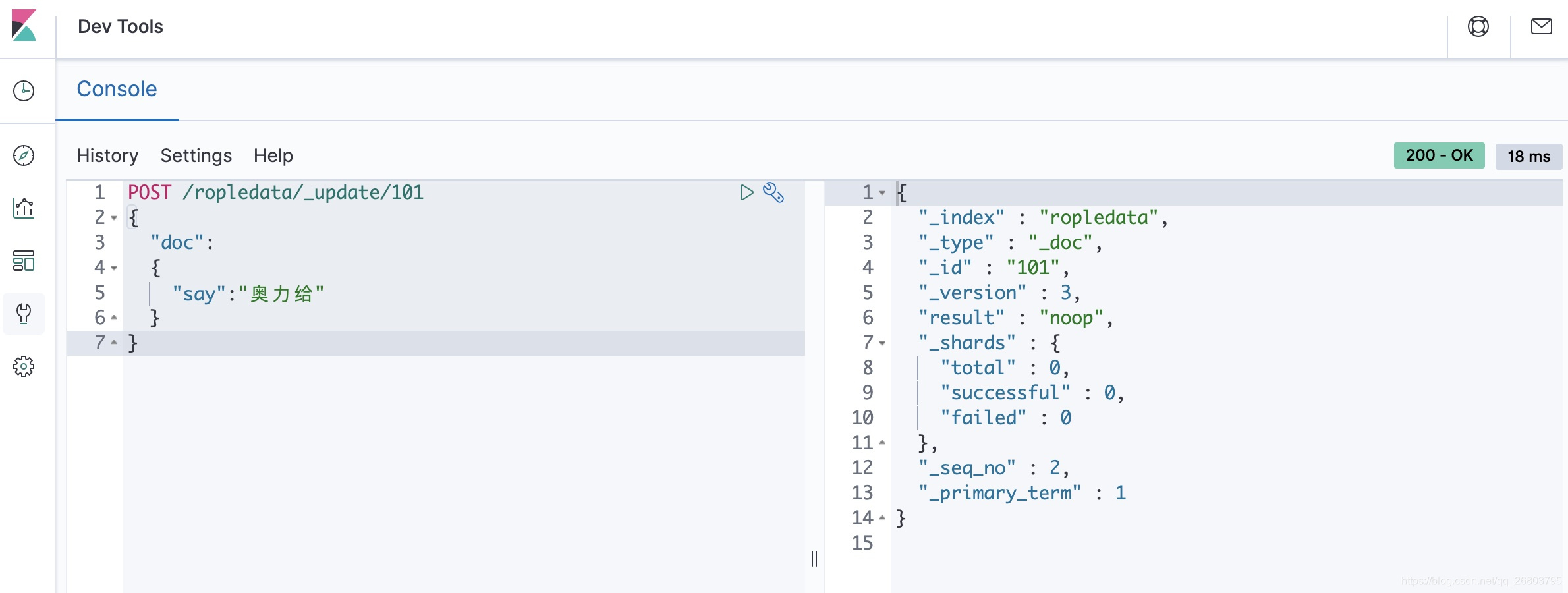
POST /ropledata/_update/101 { "doc": { "say":"奥力给" } }这时候我们可以多次去执行上面的局部更新代码,会发现除了第一次执行,后续不管又执行了多少次,
_version都不再变化!
![在这里插入图片描述]()
疑问二:局部更新的时候ES底层的流程是怎样的?和全局更新相比性能怎么样?局部更新的底层流程:
- 内部先获取到对应的文档;
- 将传递过来的字段更新到文档的json中(这一步实质上也是一样的);
- 将老的文档标记为deleted(到一定时候才会物理删除);
- 将修改后的新的文档创建出来。
性能对比:
- 全局更新本质上是替换操作,即使内容一样也会去替换;
- 局部更新本质上是更新操作,只有遇到新的东西才更新,没有新的修改就不更新;
- 局部更新比全局更新的性能好,因此推荐使用局部更新。
3.4、基础查询数据
3.4.1、搜索全部数据(默认展示10条数据)
-
GET全局搜索数据:
GET /ropledata/_search -
match_all全局搜索数据,可以加各种条件,比如排序:
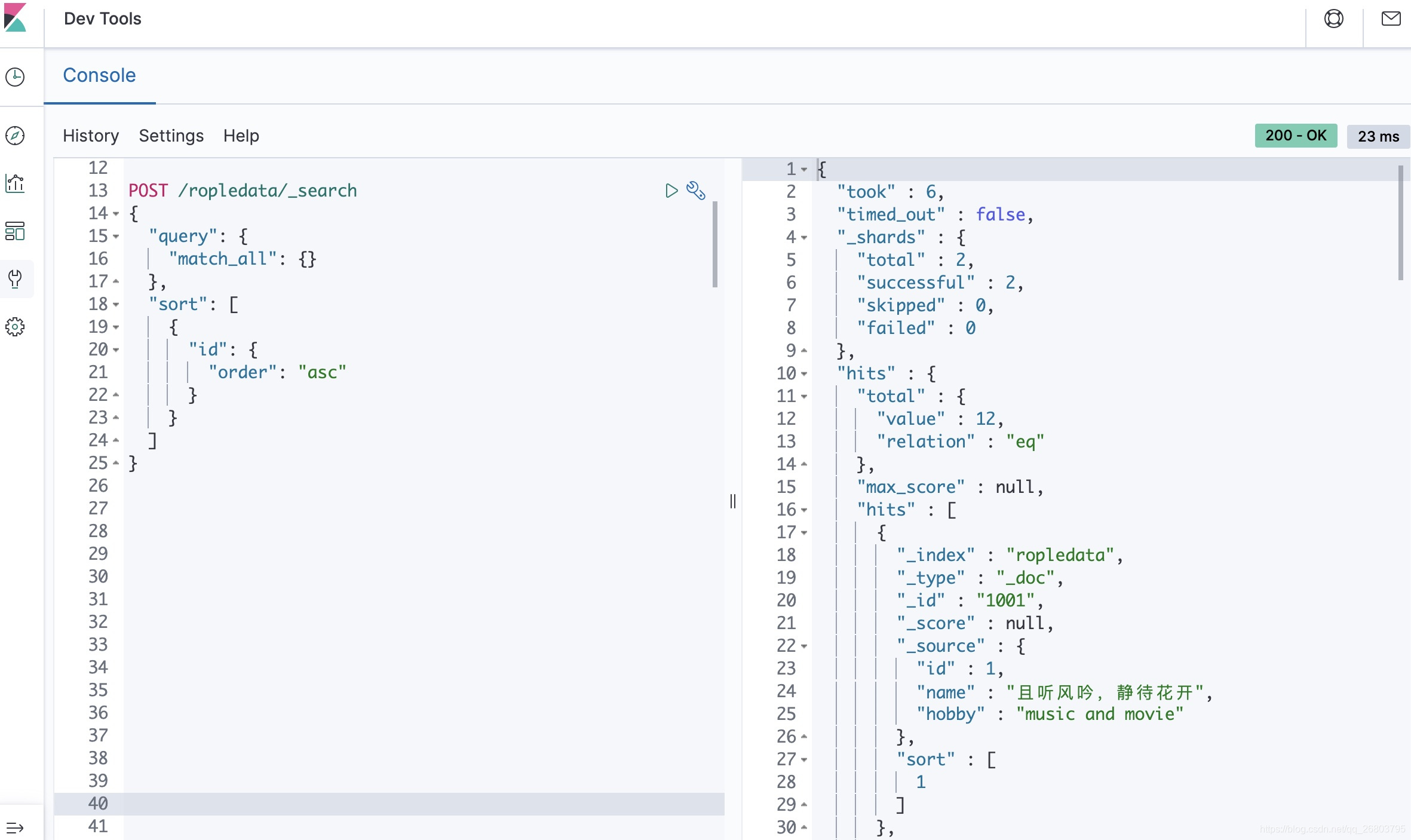
POST /ropledata/_search { "query": { "match_all": {} }, "sort": [ { "id": { "order": "asc" } } ] }以match_all为例,查询后的结果如下:
![在这里插入图片描述]()
疑问三:查询出来的字段都是什么含义呢?
- took:Elasticsearch运行查询需要多长时间(以毫秒为单位);
- timed_out :搜索请求是否超时 ;
- _shards 搜索了多少碎片,并对多少碎片成功、失败或跳过进行了细分;
- _max_score 找到最相关的文档的得分;
- hits.total.value :找到了多少匹配的文档;
- hits.sort :文档排序后的位置(比如上面查询的1,2,3…) ;
- hits._score:文档的相关性评分(在使用match_all时不适用)
3.4.2、指定文档id搜索数据:
GET /ropledata/_doc/1013.4.3、根据关键字搜索数据
比如咱们想查找ropledata这个索引下,name字段为**“且听风吟,静待花开”**的数据:
GET /ropledata/_search?q=name:"且听风吟,静待花开"3.4.4、高亮显示数据
注意:使用高亮查询,会对要查询的数据进行分词搜索!
有时候我们想把查询到的数据进行高亮显示,比如查到“且听风吟”后,想把name这个字段的数据高亮显示,可以用如下的方式:
POST /ropledata/_search
{
"query": {
"match": {
"name": "且听风吟"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}查询后,可以得到如下结果:
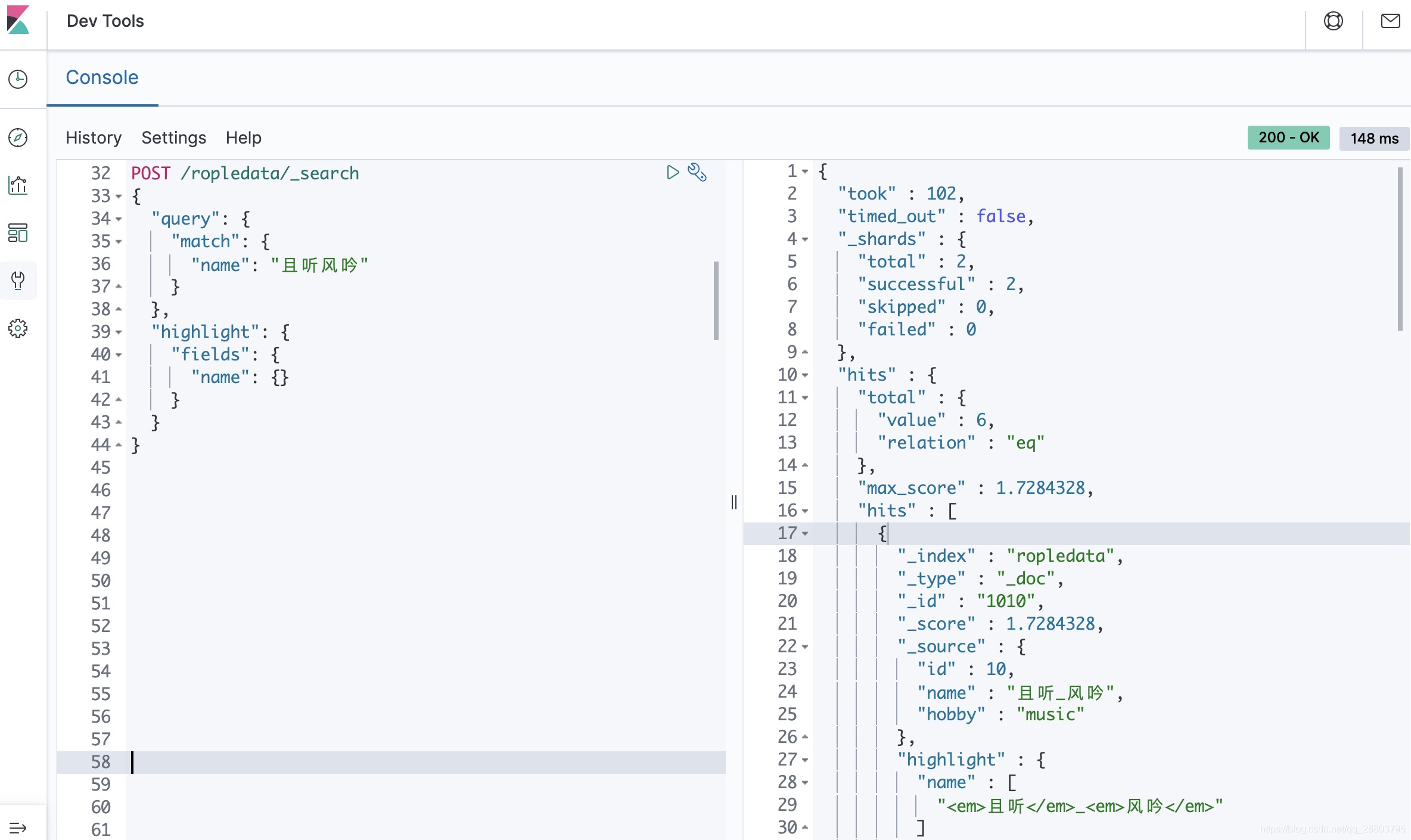
我们可以发现,会查询到分词后的“且听风吟”,同时会把name个字段分词后的数据进行高亮强调显示。注:这里的"<em></em>"标签在html里有强调文本的作用,支持所有的浏览器!
四、DSL查询
疑问四:DSL是啥意思呢?怎么通俗点解释呢?
简单来说,DSL就是ES的一种查询方式,DSL基于JSON实现了直观简单的结构化查询功能。由于DSL查询是JSON格式的,所以更加的灵活,而且可以同时包含查询和过滤器,咱们可以很轻松的构造出复杂的查询功能。
好,废话不多说,咱们把常用的关键点逐一展开,最后再来个复杂的查询玩玩:
-
term查询
term需要完全匹配,不会对词汇进行分词器分析。主要用于查询精确匹配的值,比如数字,日期,布尔值或未经分析的文本数据类型的字符串 (not_analyzed)。
比如咱们查询
id字段为9的数据(注意:这里的id不是文档id,是文档里的咱们自己命名为id的字段):POST /ropledata/_search { "query": { "term": { "id": 9 } } } -
terms查询
terms和term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配。
比如咱们查询
id字段为9和5的数据:POST /ropledata/_search { "query": { "terms": { "id": [5,9] } } } -
range查询
range 主要用于过滤,通常用于按照指定范围查找一批数据,咱们需要记忆如下四个关键字的含义:
- gt :大于
- gte : 大于等于
- lt :小于
- lte : 小于等于
记忆小技巧:gt可以理解为高to,也就是高于,大于的意思。lt可以理解为little to,也就是小于的意思。然后加上e就附加一个等于。
比如咱们想要查询
id字段大于等于5且小于10的数据:POST /ropledata/_search { "query": { "range": { "id": { "gte": 5, "lt": 10 } } } } -
exists查询
exists查询类似sql里的is null条件,通常用于查找文档中是否包含指定字段,包含这个字段就返回返回这条数据。
比如咱们想查询ropledata这个索引下,包含
hobby这个字段的数据:POST /ropledata/_search { "query": { "exists": { "field": "hobby" } } } -
match查询
match 查询是一个标准查询,不管是全文本查询还是精确查询基本上都要用到它。所以非常非常重要,一定要掌握。
在使用 match 查询一个全文本字段时,它会在真正查询之前用分析器先分析match一下查询字符;如果用 match 下指定了一个确切值, 在遇到数字,日期,布尔值或者 not_analyzed 的字符串时,它将为你搜索你给定的值。
比如咱们查询
hobby是run的数据:POST /ropledata/_search { "query": { "match": { "hobby": "run" } } } -
match_phrase查询
疑问五:match_phrase和match有啥区别呢?
match_phrase和match类似,在查询时都会对查询词进行分词,但是match会忽略查询词的空格,而match_phrase不会。因此需要注意的是:查询包含空格的字符串,要用match_phrase!
比如咱们查询
hobby是music and movie的数据(注意:这里要查询的数据包含空格):POST /ropledata/_search { "query": { "match_phrase": { "hobby": "music and movie" } } } -
bool查询
bool 查询可以用来合并多个条件查询结果的布尔逻辑,咱们需要记忆如下操作符关键字:
- must:多个查询条件的完全匹配,相当 于 and;
- must_not:多个查询条件的相反匹配,相当于 not;
- should:至少有一个查询条件匹配, 相当于 or。
注意:这些参数可以分别继承一个查询条件或者一个查询条件的数组。
比如咱们想查询
hobby必须是run,id必须不是4,name可以是一起学习或者且听风吟的数据:POST /ropledata/_search { "query": { "bool": { "must": { "term": { "hobby": "run" } }, "must_not": { "term": { "id": 4 } }, "should": [ { "term": { "name": "且听风吟" } }, { "term": { "name": "一起学习" } } ] } } -
filter查询
filter用于过滤查询,通常和bool连用,就像编程语言一样,用于过滤数据。
比如咱们想查询
hobby为music的用户:POST /ropledata/_search { "query": { "bool": { "filter": { "term": { "hobby": "music" } } } } } -
融合在一起使用
其实常用的就是上面这些,它们一般是融合在一起使用的。比如咱们要查询
id必须不是4,name包含且听风吟,同时id大于等于2且小于10的数据:POST /ropledata/_search { "query": { "bool": { "filter": { "range": { "id": { "gte": 2, "lt": 10 } } }, "must_not": { "term": { "id": 4 } }, "must": { "match": { "name": "且听风吟" } } } } }
五、聚合查询
学会了非常实用的DSL查询,下面咱们再看看聚合查询。
-
常用数学统计函数
首先咱们需要了解几个非常常用的数学统计函数:
- avg:平均值
- max:最大值
- min:最小值
- sum:求和
比如咱们求
id的平均值,有两种写法,基础写法和脚本写法:基础写法:
POST /ropledata/_search { "aggs": { "ropledata": { "avg": { "field": "id" } } }, "size": 0 }脚本写法:
POST /ropledata/_search { "aggs": { "ropledata": { "avg": { "script": { "source": "doc.id.value" } } } }, "size": 0 }疑问六:求平均值或求和时,为什么要加(“size”: 0)呢?
size用来控制返回多少数据,由于咱们是想要在所有文档里求平均值和求和,所以要用size来控制返回一个数据即可,不然ES还会默认返回10条数据。
-
cardinality去查
涉及到聚合查询的场景,当然少不了去重了,ES提供了cardinality去重统计函数来解决这个问题。
比如咱们想根据
id字段去重统计:POST /ropledata/_search { "aggs": { "ropledata": { "cardinality": { "field": "id" } } }, "size": 0 } -
value_count计数统计
有时候咱们会遇到让统计个数的场景,这时候就可以使用value_count来解决了。
比如咱们要统计有多少条数据:
POST /ropledata/_search { "aggs": { "ropledata": { "value_count": { "field": "id" } } }, "size": 0 } -
terms词聚合
terms词聚合可以基于给定的字段,并按照这个字段对应的每一个数据为一个桶,然后计算每个桶里的文档个数。默认会按照文档的个数排序。
比如咱们要根据
id字段进行词聚合:POST /ropledata/_search { "aggs": { "ropledata": { "terms": { "field": "id" } } } } -
top_hits聚合
咱们使用sql时可以很方便的处理top问题,ES也提供了对应的支持,top_hits就是这样的函数,一般和terms连用,可以获取到每组前n条数据。
比如咱们想根据
id分组,然后拿到前6条数据:POST /ropledata/_search { "aggs": { "ropledata": { "terms": { "field": "id" }, "aggs": { "count": { "top_hits": { "size": 6 } } } } }, "size": 0 } -
range范围查询
在咱们日常进行数据统计时,控制数据的范围是必不可少的,除了前面DSL查询时介绍的gt,lt函数,其实在聚合查询里还提供了range用来进行范围查询。
比如咱们想查询
id字段的值在6-9之间和10-20之间的文档有多少:POST /ropledata/_search { "aggs": { "group_by_id": { "range": { "field": "id", "ranges": [ { "from": 6, "to": 9 }, { "from": 10, "to": 20 } ] } } }, "size": 0 }
六、批量操作
作为一个存储系统,对数据的批量增删改查自然也是必不可少的!ES也提供了批量的操作,具体的用法如下。
-
批量插入
POST _bulk { "create" : { "_index" : "ropledata", "_id" : "1009" } } {"id":9,"name": "且听风吟,静待花开","hobby": "music and movie"} { "create" : { "_index" : "ropledata", "_id" : "1010" } } {"id":10,"name": "且听_风吟","hobby": "music"} { "create" : { "_index" : "ropledata", "_id" : "1011" } } {"id":11,"name": "大数据领域","hobby": "movie"} { "create" : { "_index" : "ropledata", "_id" : "1012" } } {"id":12,"name": "一起学习","hobby": "run"} -
批量查询
比如咱们想批量查询ropledata这个索引下文档id为1010,1011,1012的文档数据,可以这样写:
POST /ropledata/_mget { "ids": [ "1010", "1011", "1012" ] } -
批量更新
如果咱们想批量修改1011和1012的文档里的name字段的值,可以这样写:
POST _bulk { "update" : {"_id" : "1011", "_index" : "ropledata"} } { "doc" : {"name" : "批量修改"} } { "update" : {"_id" : "1012", "_index" : "ropledata"} } { "doc" : {"name" : "大家好"}} -
批量删除
如果咱们想批量删除文档id为1011和1012的文档,可以这样写:
POST _bulk { "delete" : { "_index" : "ropledata", "_id" : "1011" } } { "delete" : { "_index" : "ropledata", "_id" : "1012" } }
七、实用骚操作
7.1、浏览器查询结果美化
咱们之前介绍的所有的操作,都是在kibana里输入的,里面可以对输入的命令和输出的结果进行格式化。但是如果咱们直接使用浏览器进行查询时,输出的查询结果会乱成一团,那么怎么去美化呢?
别急,只要在查询的最后加上pretty参数,就可以了:
http://127.0.0.1:9200/ropledata/_doc/1001?pretty查询出来的结果就会被美化了:
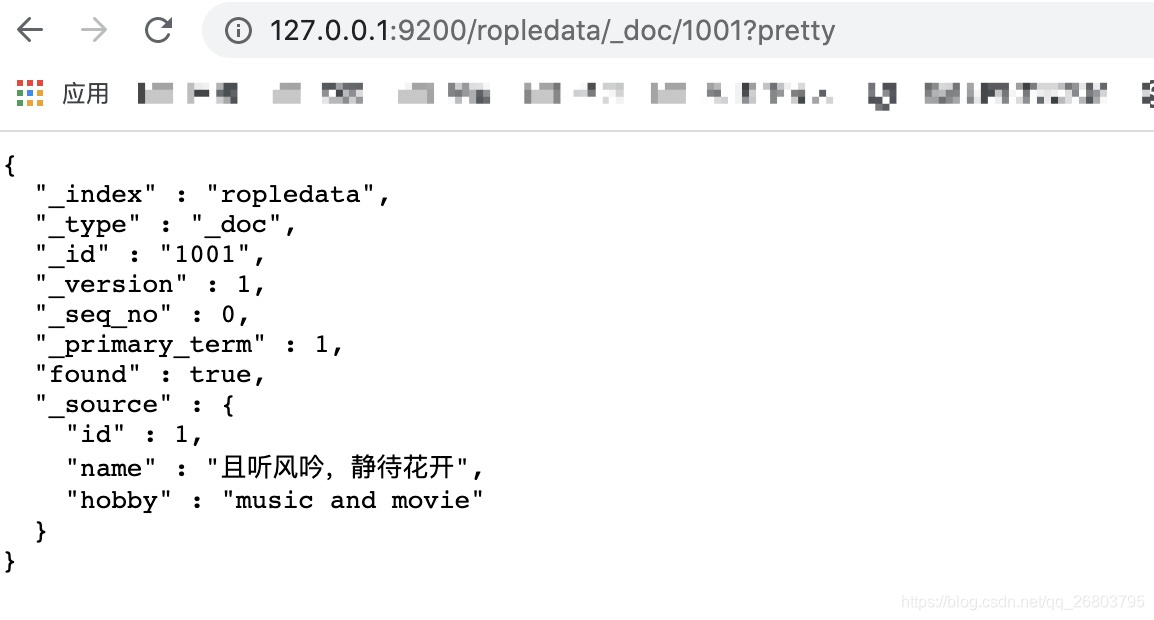
7.2、指定返回的字段
咱们有时候不需要返回整个文档所有的字段,只想要查看其中的一个或者多个字段,这时候ES也提供的有方法,只需要在最后使用**_source**参数,并传递想要返回的字段就可以了。
http://127.0.0.1:9200/ropledata/_doc/1001?pretty&_source=id,name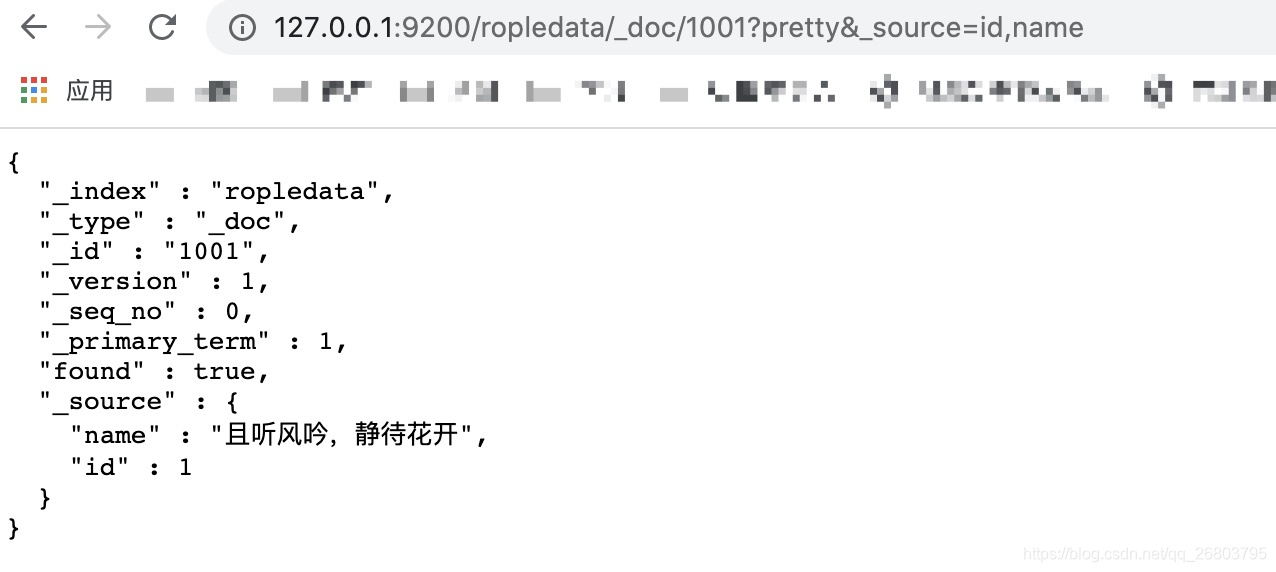
7.3、不显示元数据
咱们查询的时候,会返回一大堆数据,上面那些称为元数据,那不需要的时候,怎么去掉呢?别急,只需要把_doc换成_source就可以了。
http://127.0.0.1:9200/ropledata/_source/1001?pretty&_source=id,name
7.4、查看文档是否存在
有时候咱们为了防止报错,在查询之前,需要查看这个文档是否存在,这时候只需要用到HEAD关键字就可以了。
HEAD /ropledata/_doc/1001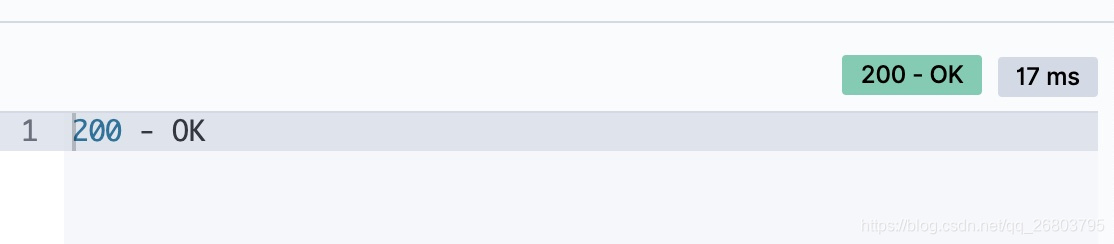
7.5、分页查询
对于海量存储的数据,有时候咱们需要分页查看。ES提供了size和from两个参数,size代表每页的个数,默认是10个,from代表从第几个获取。咱们只要在代码里写清楚这两个参数,就可以实现翻译了。
http://127.0.0.1:9200/ropledata/_search?size=1&from=2&pretty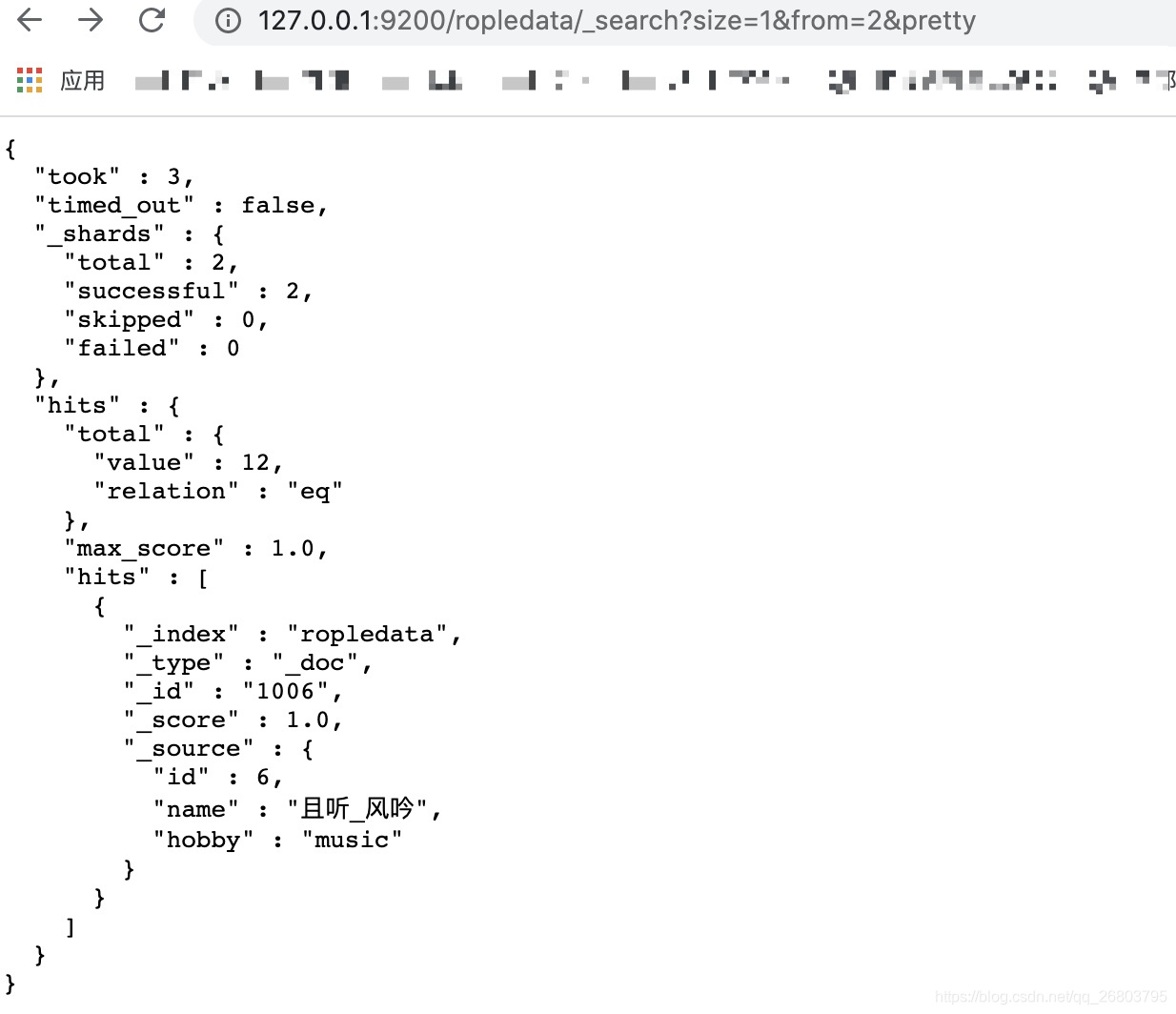
八、总结
本文围绕ES最新版本,从常用基础操作、DSL查询、聚合查询、批量操作,实用技巧等方面进行了详细的举例解析,并对读者可能出现的疑惑进行了标红疑问总结(本文共总结了六处容易产生的疑问点),对需要注意的地方也进行了单独的声明,希望对大家学习ES提供帮助!
注意:如果我的文章对您有所帮助,欢迎关注点赞收藏,如果您有疑惑或发现文中有不对的地方,还请不吝赐教,非常感谢!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号