会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
IndustriousHe
博客园
首页
新随笔
联系
订阅
管理
2019年3月22日
全栈性能测试
摘要: Web项目测试通过标准 启动jemter BadBoy录制(模拟浏览器工具) 把jemter设置成中文
阅读全文
posted @ 2019-03-22 10:42 IndustriousHe
阅读(429)
评论(0)
推荐(0)
2018年12月26日
分布式爬虫
摘要: 分布式爬虫的原理 scrapy分布式爬取的实现 搭建redis服务器 部署代理池和cookie池 配置scrapy redis Bloom Filter(判断一个元素是否存在集合中) scrapy去重
阅读全文
posted @ 2018-12-26 14:29 IndustriousHe
阅读(324)
评论(0)
推荐(0)
2018年12月23日
数据分析
摘要: 猫眼电影简单的分析实例 python coding: utf 8 """ Created on Sat Apr 14 14:45:49 2018 @author: Administrator """ ''' 爬猫眼网站TOP100的电影数据: http://maoyan.com/board/4?of
阅读全文
posted @ 2018-12-23 11:04 IndustriousHe
阅读(333)
评论(0)
推荐(0)
2018年12月9日
《爬虫网络开发实战》
摘要: 爬虫基础 URL&&URI 请求方法:GET&&POST 响应 基本库的使用 urllib urlopen(传递参数data) urlopen(设置超时timeout) 打开网站需要验证账号密码可以借助HTTPBasicAuthHandler完成 代理IP,ProxyHandler Cookie 解
阅读全文
posted @ 2018-12-09 10:15 IndustriousHe
阅读(1277)
评论(0)
推荐(0)
ubuntu安装anaconda
摘要: 1.在windows下载好文件(ubuntu下载太慢了) 2.把下载好的包放入到downloads(路径只要自己喜欢就好) 3.使用终端cd到downloads文件夹 4.终端输入bash ana.........sh 5.一直按回车阅读,然后输入yes,最后添加环境变量就可以用了
阅读全文
posted @ 2018-12-09 10:01 IndustriousHe
阅读(411)
评论(0)
推荐(0)
2018年12月4日
爬虫的基本操作
摘要: anaconda安装 打开浏览器的开发者模式 设置 更多工具 扩展程序 安装xpath解析工具到浏览器扩展程序 使用xpath插件查询元素ctrl+shif+x 获取url地址并获取源码 把获取的URL响应内容从字节转换成字符decode 创建一个新的User Agent 返回url的影响码getc
阅读全文
posted @ 2018-12-04 11:26 IndustriousHe
阅读(1057)
评论(0)
推荐(0)
2018年12月3日
github客户端的操作
摘要: 创建一个本地仓库 在本地仓库修改文件 把本地仓库上传到github上 查看上传后的仓库
阅读全文
posted @ 2018-12-03 12:06 IndustriousHe
阅读(318)
评论(0)
推荐(0)
github浏览器的操作
摘要: 新建项目仓库 新建一个文件 查看版本分支
阅读全文
posted @ 2018-12-03 11:15 IndustriousHe
阅读(376)
评论(0)
推荐(0)
2018年12月2日
把两个列表使用字典关联起来zip
摘要: 
阅读全文
posted @ 2018-12-02 20:27 IndustriousHe
阅读(359)
评论(0)
推荐(0)
集合并集,交集
摘要: 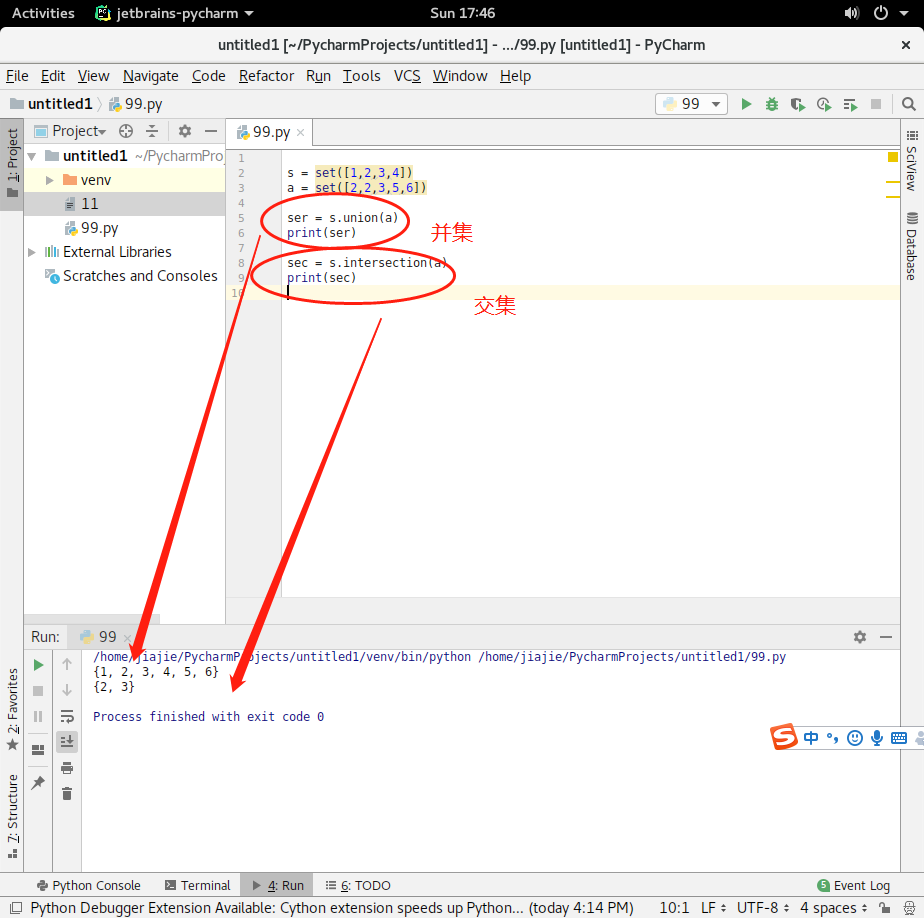
阅读全文
posted @ 2018-12-02 17:50 IndustriousHe
阅读(295)
评论(0)
推荐(0)
下一页
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号